| 【多元统计分析】聚类分析【期末复习】 | 您所在的位置:网站首页 › 模糊聚类分析法论文题目 › 【多元统计分析】聚类分析【期末复习】 |
【多元统计分析】聚类分析【期末复习】
|
聚类分析理论阐述
#理论参考 何晓群.多元统计分析(第五版)[M].北京:中国人民大学出版社 获取试卷:关注公众号回复:聚类分析试卷
聚类分析认为所研究的样品或指标之间存在不同程度的相似性,根据一批样品的多个观察指标,找到一些能够度量样品或指标之间的统计量,把这些统计量所谓划分类型的依据,把相似程度较大的样品聚合为一类,把相似程度较大的另外一类样品聚为另一类,关系密切的聚合到一个小的分类单位里,关系疏远的聚合到另一个大的分类单位里,直到把所有的样品或指标都聚合完毕,把不同类型的一一划分出来,形成一个有小到大的分类系统,最后把整个分类系统化成一张分群图,用它把样品或指标之间的亲疏关系表现出来。 对样品进行聚类分析时,要注意样品的数据类型,对定性的数据所做的分类常常分为Q型聚类分析,对变量的分类常称为R型聚类分析。 聚类分析的目的,是将相似的样品(研究对象)聚成类,使类内对象的同质性最大化和类与类之间的对象异质性最大化。 2.相似性度量通过计算样本间的统计距离,进行相似度的度量。 3.统计距离的分类衡量样品是否能分为同一类的指标,是样品之间的统计距离。统计距离分为明氏距离、马氏距离及欧氏距离。 明氏距离(明科夫斯基氏距离) 又称为绝对值距离,只需要将两者的坐标做简单相减,取绝对值数值就可以。设D为两个样本之间的明氏距离,则明氏距离的表达式为: 系统聚类法说聚类分析中使用最多的方法,步骤如下: 计算n个样本两两之间的距离 构造n个类别,每个类别只包含一个样品 合并距离最近的两类为一个新的类别 计算新类与当前各类之间的距离 当类的个数不唯一时,循环第3、4步,直到类别数为1 画出聚类图 决定分类个数和类别 其中,最短距离法和最长距离法是系统聚类法的常用方法,最长距离法和最短距离法的距离所指的是上面计算的类与类之间统计距离,需要注意的是,无论是使用最短距离法进行聚类,还是最长距离法进行聚类,在聚成一个新类的时候,都需要选择两个最短距离的类别聚成一个新类,最短距离法的短,体现在聚成新类之后再次计算类与类之间的距离时,采用类别中与另一个类别中的变量距离最短的一个,而最长距离则是才去距离最长的一个。 5.K-means聚类和有序样品的聚类在数据挖掘中,对商业信息进行挖掘时,时常用到K-means聚类,在R语言和Python中,K-means聚类都是被广泛使用的数据处理方法,在K-means聚类之前,需要对数据进行标准化。 K-means聚类定义: L-means聚类又称为非谱系聚类法,将样品聚集成K个类的集合,类的个数K可以先预定,类的个数K可以先给定,或者在聚类过程中确定。在计算机计算过程中,无需确定距离(即相关系数矩阵),也无须储存数据,所以K-means聚类可以用于数据量较大的情况。 K-means一开始对元素分组,或者从一个构成各类核心的“种子”集合开始,选择好的初始构型能消除系统的偏差,一种方法是从所有项目中随机选择“种子”或随机的元素分成若干个初始类。 步骤如下:【当然通过软件是可以直接一步到位实现的,例如R或者Python都时候几行代码就可以了】 把样品粗略分为K个初始类 进行修改,逐个分派样品到最近均值类中(用标准化or非标准化数据计算欧氏距离)【个人倾向于将数据进行标准化后消除量纲对结果的影响的前提下再用K-means聚类】重新计算接受新样品的类和是取样品的类的形心(均值) 重复步骤2,直到各类无元素进出。 为了避免以下情况的出现,在实际操作中,导师一般建议我们事先确定分类个数。如果没有预先分类,则可能会出现以下情况: (1)聚类结果难以区分。如果存在两个或多个“种子”跑到同一类中,则聚类结果将难以区分。 (2)局外干扰的存在将至少产生一个样品非常分散的类。 (3)即使一直总体由K个类别组成,抽样方法也可造成属于最稀疏类的数据不出现在样本中,强行把这些数据分成K个类会导致无意义的聚类。 有序样品的聚类(1)可能的分类数目 假设用x1,x2,…xn,表示n个有顺序的样品,有序样品的分类结果要求每一类必须呈: ,增加了有序这个约束条件,相对于K-means算法,对分类结果,有序样品的分类就类似于高中排列组合题目的解法,进行插空,所以所有可能的分类有 种, 如果想要分成3类,就相当于插上两根棍子,因此可能分类就有 因此如果是分成k类,那可能分类就是 (1)统计距离的计算【马氏距离的计算】 |

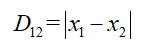 欧氏距离 欧式距离是我们最熟悉的距离之一,早在高中阶段,我们就学会了运用欧氏距离计算两点间的距离,将两点间的距离运用在立体几何中进行解题。但在数据分析中,由于欧氏距离对每个坐标之间的贡献值都是同等的,不能对指标进行合理的加权。而且在度量大小的时候,与指标的单位有关,在进行经济类指标的计算的时候,由于各类数据的单位不统一,导致研究的不准确,因此在统计计算中,不采用欧氏距离作为计算距离的方法。 计算公式:
欧氏距离 欧式距离是我们最熟悉的距离之一,早在高中阶段,我们就学会了运用欧氏距离计算两点间的距离,将两点间的距离运用在立体几何中进行解题。但在数据分析中,由于欧氏距离对每个坐标之间的贡献值都是同等的,不能对指标进行合理的加权。而且在度量大小的时候,与指标的单位有关,在进行经济类指标的计算的时候,由于各类数据的单位不统一,导致研究的不准确,因此在统计计算中,不采用欧氏距离作为计算距离的方法。 计算公式: 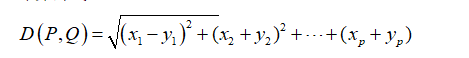 马氏距离 利用坐标差平方除以方差,将数据转化为无量纲的数,可以消除数据量纲对聚类结果之间的影响。计算方法如下:
马氏距离 利用坐标差平方除以方差,将数据转化为无量纲的数,可以消除数据量纲对聚类结果之间的影响。计算方法如下: 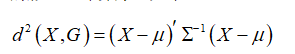 在多元的情况下,转化成矩阵,也是利用公式代入,得到矩阵。 马氏距离的计算在多元统计分析的期末考试中,是一个小的考点。考点主要考察的是逆矩阵的计算。如果逆矩阵的运算不存在问题,一般不会出错。
在多元的情况下,转化成矩阵,也是利用公式代入,得到矩阵。 马氏距离的计算在多元统计分析的期末考试中,是一个小的考点。考点主要考察的是逆矩阵的计算。如果逆矩阵的运算不存在问题,一般不会出错。

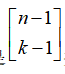
 最长距离法/最短距离法进行聚类
最长距离法/最短距离法进行聚类 


【本文地址】