| 最常用的聚类算法 | 您所在的位置:网站首页 › 概率扩散模型有哪些 › 最常用的聚类算法 |
最常用的聚类算法
|
1 K-Means算法引入 基于相似性度量,将相近的样本归为同一个子集,使得相同子集中各元素间差异性最小,而不同子集间的元素差异性最大[1],这就是(空间)聚类算法的本质。而K-Means正是这样一种算法的代表。 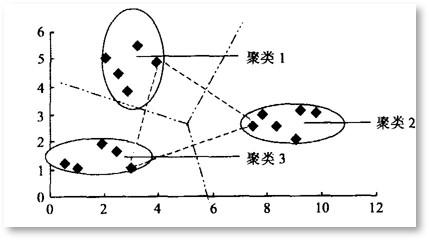 图1 二维空间聚类的例子 [1] 图1 二维空间聚类的例子 [1]上个世纪50/60年代,K-Means聚类算法分别在几个不同的科学研究领域被独立地提出,直到1967年,教授James MacQueen在他的论文《用于多变量观测分类和分析的一些方法(Some Methods for classification and Analysis of Multivariate Observations)》中首次提出“K-Means”这一术语,至此该算法真正开始被推广和应用,并发展出大量不同的改进算法。 如今,K-Means聚类被提出已经超过50年,但仍然是应用最广泛、地位最核心的空间数据划分聚类方法之一。作为一种无监督算法,尽管无法判断结果对错,但是它将为我们研究对象群体的内部结构提供一些很好的切入点。 有无监督学习的一大区别在于定性时机先后的不同。事先无法对样本进行准确的判定,需要建立和总结一定的规则模式后再定性的,属于无监督学习。相反,样本一开始就拥有“目标”标签的话,我们所进行的从特征到目标的建模,则是有监督的学习。 举个例子,动物园中有哈士奇和狼,如果饲养员已经指明了哪些是狼(即样本标签),哪些是哈士奇,我们就能挑出尾巴、爪子、眼睛等特征,训练出一个可以尽量预测对方是狼还是哈士奇的模型,还能给出明确的精度信息,用以评价模型的优劣和预测的可行性,这就是一个有监督学习的过程 。而当没有人告诉我们所有这些动物的真实品种时,我们只能根据个人直觉,把看起来欢脱一些的归为哈士奇,另一些气场不同的则都归为狼,这个对动物外形和习性相似性的感知和判断,就是一个无监督的学习过程,而且是一个聚类的过程。  2 基本步骤 2 基本步骤先来完整地过一遍算法,其步骤具体地: STEP 1 从N个样本数据中随机选取K个对象,作为初始的聚类中心; STEP 2 分别计算每个样本点到各个聚类中心的距离,并逐个分配到距离其最近的簇中; STEP 3 所有对象分配完成后,更新K个类中心位置,类中心定义为簇内所有对象在各个维度的均值; STEP 4 与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转至步骤2,否则转至步骤5; STEP 5 当类中心不再发生变化,停止并输出聚类结果,然后整理我们所需要的信息,如各个样本所属的类等等,进行后续的统计和分析。  图2 一个简单的聚类迭代过程 [2] 图2 一个简单的聚类迭代过程 [2]容易看出,聚类结束之前,类中心会不断移动,而随着类中心的移动,样本的划分情况也会持续发生改变。对此,有这样一个牧师-村民模型可以帮助大家理解这个聚类的过程: 四位牧师(即K=4)去郊区布道,一开始牧师们随意选了几个布道点(即初始聚类中心),并且把这几个布道点的情况公告给了郊区所有的居民,于是每个居民到离自己家最近的布道点去听课(样本分配)。听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的居民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置(聚类中心的迁移和更新)。牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个居民又去了离自己最近的布道点……就这样,牧师每个礼拜更新自己的位置(聚类迭代),居民根据自己的情况选择布道点,最终稳定了下来(聚类完成)。很自然地,最终的聚类结果应该是:在同一位牧师布道处听课的村民们,他们的住址应该最相近,同时他们离在其他牧师处听课的村民们的家都相对较远。这与我们“簇内差异小,簇间差异大”的聚类目标不谋而合。 3 优化分析与思考理解了算法的运作,接下来,我们就要带大家走得深一些,围绕这些步骤,掰开揉碎了来思考一些细节上的问题。 3.1 聚类个数K的问题算法所需要预设的参数至少有2个:聚类个数K和初始聚类中心点。其中,最为人“诟病”的当属合适K值的选取。现实中,K值的选定通常是难以估计的,很多时候,我们并不知道给定的数据集应该分成多少个类别才最合适,这也在一定程度上影响和限制了K-Means的应用合理性。 聚类的目标是使得每个样本点到距离其最近的聚类中心的总误差平方和(也即聚类的代价函数,后文记作SSE)尽可能小。  图3 聚类代价函数/总误差平方和(SSE) [3] 图3 聚类代价函数/总误差平方和(SSE) [3]理论上随着K的增加,SSE会单调递减,因为类数的增加意味着总有一部分样本点会因为归属到新的类簇而节约下一段距离,直到K=N时,情况将演变为每个样本自成一类,此时SSE值就会降为0。可是这显然不是我们希望的。 根据学者们的长期实践经验,K值最大不应超过样本量的开平方根,即Kmax≤√N。而确定了范围后,最优K值又应该怎么判断?一种简单的思路是:试图找到某一个K值,要求当K大于该值时,SSE的下降变化幅度(或速度)明显变小。换句话说,当K超过某一个数后,每个类簇的聚合程度不再获得显著提升,此时我们就可以认为已找到最佳K的取值。这也是手肘法:通过画出不同K值与SSE值的折线图,若SSE值下降过程中存在“肘点”(下降速度骤减的拐点处),该点所对应的K值即合适的聚类数。不过遗憾的是,若SSE的下降是均匀的,传统的肘部图法也就失灵了。  图4 SSE与K的关系 [2] 图4 SSE与K的关系 [2]虽然目前不少学者对传统的手肘法和其他检验聚类有效性的函数提出了改进,但对于最优K值确定,仍未有最佳的方案,对于我们学习者,更多的时候还是需要凭借常识经验,或者从实际应用场景出发,与算法互相“磨合”。 3.2 初始聚类中心点问题另一个需要预设的参数,是初始聚类中心点。 常用分析软件中的功能模块或函数包,基本上都已经代替使用者们自动预设了随机初始点,只需填入目标K值,就可以跑动算法。但实际上,K-Means对初始聚类中心的位置十分敏感,每次迭代,初始点的不同往往会导致不同的聚类结果。此外过于临近的初始中心点,有时还会导致模型的收敛时间变长(即Step4中迭代时间变长)。一种简单粗暴的解决方式是,选择不同的初始聚类中心,多次运行算法,挑出聚类效果更佳(SSE更小)、解释性更强的一组结果。 当然了,我们或许更想知道算法上的改进手段。一种常见的优化方法是采用最大距离法,如:首先选取数据集中距离最大的两个点作为初始聚类中心,将剩余数据对象依据到聚类中心点距离的远近分配到相应的簇中,并更新聚类中心,然后继续寻找与聚类中心距离最远的点作为下一个中心点……  与此类似地还有K-Means++,它是传统K-Means的改良版,同样是基于最大距离,这里结合加权概率的思想优化了对K个初始中心的选取,使得在选取第n+1(n+1图6 球形(左)和非球型数据(右)的K-Means聚类效果差异 另外,这里顺便提一下离群点的问题。离群点或者噪声数据会对均值产生较大的影响,导致中心偏移,因此在正式执行聚类之前,需要事先检查并去除异常值,以减少离群点、孤立点对于聚类效果的影响。另一种缓解异常值带来的影响的方式,是以中位数作为中心点的选取根据,事实证明中位数比均值更能抵抗离群点带来的干扰,并且不限于数值型数据,而能包容更多的数据类型。 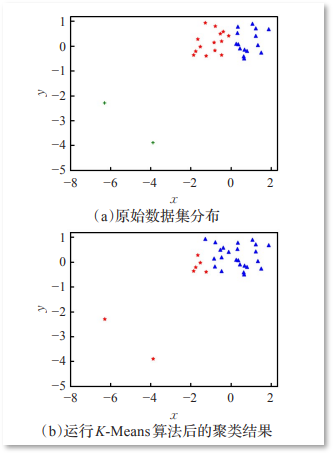 图7 离群点带来的影响 [2]3.4 聚类时间问题 图7 离群点带来的影响 [2]3.4 聚类时间问题首先我们容易关注到结束信号的问题。上面的流程中提到,当聚类中心不再改变时(数学上即要求SSE函数收敛),我们认为聚类过程结束,但是这并不是唯一的结束信号。为了节省计算时间,有时我们也会通过设置迭代次数、设置簇内平方和或SSE下降阈值,又或者替换为“直到仅有1%的点改变簇”这样的弱条件,来控制算法的进程。出于对问题复杂度和计算量的合理预判,若聚类中心的更新超过了迭代次数上限,或者代价函数SSE已经小于所设定的阈值,我们都有理由提前终止。 此外,为了提高收敛速度,还可以考虑采用二分K-Means法,将所有点作为一个簇,将该簇一分为二,然后选择能最大程度降低聚类代价函数的簇划分为两个簇,以此进行下去,直到簇的数目等于给定的个数K为止。值得一提的是,该法更突出的优点在于能够很好地解决K-Means收敛到局部最优的问题,帮助我们找到全局最优解。 局部最优还是全局最优,是不少机器学习算法所需要面临的问题。在传统K-Means中,K个初始点设置后,各个簇的大致范围其实也就落定了,无论更新多少次,中心点的位置也不会有过大的变化,也因此我们只是不断在调整当前类簇的大小(或者说形状),然后找到这K个类簇取得最小SSE时的聚类结果,这也就是我们所找到的局部最优。然而K相同的情况下,更换初始点,有可能会得到更小的SSE,而继续换,可能会继续获得更小的SSE,直到再也没有更小的情况出现,此时才是真正的全局最优解。 3.5 标准化问题最后补充一点是,考虑到我们所研究的对象通常包含多列数据,这些数据代表不同方面的属性值,在单位和数量级上可能存在较大的差别,因此为了避免这些差异可能引发的计算精度下降等问题,对于连续属性,可以先对数据进行规范化处理(如零均值规范化、最大最小值规范化等),再进行距离的计算。 4 实操案例(R&Python)原理已经基本介绍完毕,下面我们就来看一下如何在软件中实现吧。如果是对编程语言并不熟悉的朋友,可以通过SPSS进行快速实现,只需输入预设K值,调整一下选项中的输出,就能马上得到聚类中心、各个样本的类别归属,及各个样本到最近中心的距离等。下面我们来展示K-Means在python和R中的基本实现。 Python以下展示使用sklearn,并直接采用sklearn库自带的鸢尾花数据集对K-Means进行实现的案例,这里用到的类是sklearn.cluster.KMeans。 1.可以向KMeans传入的参数: sklearn官网所提供的参数说明有9个,我们使用时,如无特别需要,一般只有第一个参数(n_cluster)需要设置,其他参数直接采用默认值即可。 一种示例: class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='auto') 对于我们来说,常常只需要: sklearn.cluster.KMeans(n_clusters=K) 1. n_cluster:聚类个数(即K),默认值是8。2. init:初始化类中心的方法(即选择初始中心点的根据),默认“K-means++”,其他可选参数包括“random”。3. n_init:使用不同类中心运行的次数,默认值是10,即算法会初始化10次簇中心,然后返回最好的一次聚类结果。4. max_iter:单次运行KMeans算法的最大迭代次数,默认值是300。5. tol:浮点型,两次迭代之间簇内平方和下降的容忍阈值,默认为0.0001,如果两次迭代之间下降的值小于tol所设定的值,迭代就会停下。6. verbose:是否输出详细信息,参数类型为整型,默认值为0,1表示每隔一段时间打印一次日志信息。7. random_state:控制每次类中心随机初始化的随机种子,作用相当于能够锁定和复现同一次随机结果,默认为none,也可以随机设置数字。 【下面两个小编也表示不懂,因此直接将翻译放上来,如果有了解的朋友欢迎来指教~】8. copy_x:在预先计算距离时,首先将数据居中在数值上更准确。如果 copy_x 为 True(默认),则不修改原始数据。如果为 False,则修改原始数据,并在函数返回之前放回,但通过减去再添加数据均值可能会引入小的数值差异。请注意,如果原始数据不是C-contiguous,即使copy_x 为False,也会进行复制。如果原始数据是稀疏的,但不是 CSR 格式,即使 copy_x 为 False,也会进行复制。9. algorithm:有三种参数可选:auto”, “full”, “elkan”,默认为auto。K-means 算法使用。经典的EM-style算法是“full”。通过使用三角不等式,“elkan” 变体对具有明确定义的集群的数据更有效。然而,由于分配了一个额外的形状数组(n_samples,n_clusters),它更加占用内存。2.可以输出的属性: 通过调用这些属性,就可以输出我们所关注的一些聚类结果: 1. cluster_centers_:最终聚类中心的坐标;2. labels_:每个样本点对应的类别标签;3. inertia_:每个样本点到距离它们最近的类中心的距离平方和,即SSE;4. n_iter:实际的迭代次数;5. n_features_in_:参与聚类的特征个数;6. feature_names_in_:参与聚类的特征名称。3.实战案例 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris #调用数据 iris = load_iris() #导入sklearn自带的鸢尾花数据集 X = pd.DataFrame(iris.data, columns=iris.feature_names) X.head(10)输出鸢尾花数据集的前10行,可以看到特征包括了:萼片长度(sepal lenth)、萼片宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)。  以萼片长度和萼片宽度为例,看看原始数据集在该二维空间的散点分布图吧: #取其中两个维度,绘制原始数据散点分布图 #x, y为散点坐标,c是散点颜色,marker是散点样式(如'o'为实心圆) plt.scatter(X["sepal length (cm)"], X["sepal width (cm)"], c = "red", marker='o', label='sample') #横坐标轴标签 plt.xlabel('sepal length') #纵坐标轴标签 plt.ylabel('sepal width') #plt.legend设置图例的位置 plt.legend(loc=2) plt.show()输出:  正式建模前,我们先尝试用手肘法确定最佳的K值。 from scipy.spatial.distance import cdist #先对图像样式做一些设计 plt.plot() colors = ['b','g','r'] markers = ['o','v','s'] #生成一个字典保存每次的代价函数 distortions = [] K = range(1,10) for k in K: #分别构建各种K值下的聚类器 Model = KMeans(n_clusters=k).fit(X) #计算各个样本到其所在簇类中心欧式距离(保存到各簇类中心的距离的最小值) distortions.append(sum(np.min(cdist(X, Model.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0]) #绘制各个K值对应的簇内平方总和,即代价函数SSE #可以看出当K=3时,出现了“肘部”,即最佳的K值。 plt.plot(K,distortions,'bx-') #设置坐标名称 plt.xlabel('optimal K') plt.ylabel('SSE') plt.show()根据肘部图可以看到,当K=3时,产生了所谓的“肘点”,从K=3到K=4,SSE的下降速度明显变缓。故最佳的K取值应为3。  下面开始建模! model = KMeans(n_clusters=3) #构造聚类器 model.fit(X) #拟合我们的聚类模型此时模型就已经完成了,model中已经保存了所有的结果数据,接下来就可以随意提取我们想要的聚类信息了: label_pred = model.labels_ #获取聚类标签 label_pred输出所有149个样本的类别标签:  ctr = model.cluster_centers_ #获取聚类中心
ctr ctr = model.cluster_centers_ #获取聚类中心
ctr输出三个最终的聚类中心坐标: inertia = model.inertia_ #获取SSE
print("计算得到聚类平方误差总和为",inertia)输出:  最后再看一下我们的样本聚类后的效果吧: #绘制K-Means结果 #取出每个簇的样本 x0 = X[label_pred == 0] x1 = X[label_pred == 1] x2 = X[label_pred == 2] #分别绘出各个簇的样本 plt.scatter(x0["sepal length (cm)"], x0["sepal width (cm)"], c = "red", marker='o', label='label0') plt.scatter(x1["sepal length (cm)"], x1["sepal width (cm)"], c = "green", marker='*', label='label1') plt.scatter(x2["sepal length (cm)"], x2["sepal width (cm)"], c = "blue", marker='+', label='label2') plt.scatter(model.cluster_centers_[:,0],model.cluster_centers_[:,1], c = "black", marker='s',label='centroids') plt.xlabel('sepal length') plt.ylabel('sepal width') plt.legend(loc=2)输出如下。仍然观测萼片长度和宽度的二维空间上样本的分布情况,三种标志分别代表来自三种类别的样本。centroids为三个聚类的中心点。 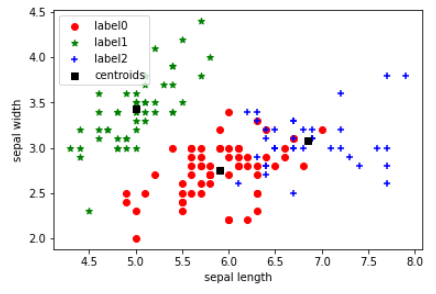 R R由于实现思路和包用法与Python中类似,在此不再对函数进行具体的解释,有兴趣的朋友可以自行查询百度或官网help一下。 案例中,我们使用R中内置的usarrest数据集,该数据集包含1973年美国每个州每10万居民因谋杀(Murder)、袭击(Assault)和强奸(Rape)而被捕的人数,以及每个州居住在城市地区的人口百分比(UrbanPop)。为便于解释说明,我们只取前三个指标。先来导入数据: rm(list = ls()) #清空工作台缓存数据 warnings('off') #忽略所有警告 library(factoextra) #一个绘图包,我们可以小小借用一下 library(cluster) #实现K-Means的包 #导入R自带数据集 data可以看到在K=4时,我们得到了想要的“肘点”。下面我们就开始正式建模,此处使用的是R内置的kmeans包,基本使用方法如kmeans(data,centers,iter.max,nstart,......),其所需要我们传入的参数同样很简明:其中data代表传入的数据集,centers代表聚类个数(即K值),至于其他的参数,如无特别的需要,我们直接使用默认值即可。 #可以设置随机种子 #set.seed(1) #调用kmeans聚类算法,根据前面的讨论,定义 k = 4 km 1. cluster:每个样本的标签。2. centers:聚类中心点的坐标。 3. totss:全体数据集的离差平方和。 4. withinss:每个类内的误差平方和(反映类内相似性,数值越小越好)。 5. tot.withinss:各类别的类内误差平方和的总和,数值上等于withinss加和,即SSE 。6. betweenss:各类别间的误差平方和,数值上等于totss – tot.withinss (反映类间差异性,数值越大越好)。7.size:每个组中的数据点数量 。8. iter:迭代次数。 9. ifault:可能存在问题的指标。比如我们想要查看总的误差平方和(即SSE): km$tot.withinss马上就可以得到:  此外,我们也可以使用aggregate()函数查看每个类中各个变量的均值。通过by将聚类得到标签与原数据集连接,可以看到如第一个类中,平均每十万人发生的谋杀被捕案数为7.2例,袭击被捕为156.6例,强奸被捕为21.1例。 输出:  最后,我们来看看聚类完成后的样本分布吧: # pch用于设置标记符的样式,19为实心近似菱形,8为米字符;cex用于设置尺寸大小 plot(df, col = km$cluster, main="Kmeans Cluster with K = 4 ", pch = 19) points(km$centers, col = 1:4, pch = 8, cex = 3)简单地取前两个维度,可以看到:  还可以借助factoextr库的fviz_cluster包,画出一些更复杂的图。这里仅仅展示了最简单的样式,通过设置其他参数,可以进一步调整和修饰样式。 fviz_cluster(km, data = df)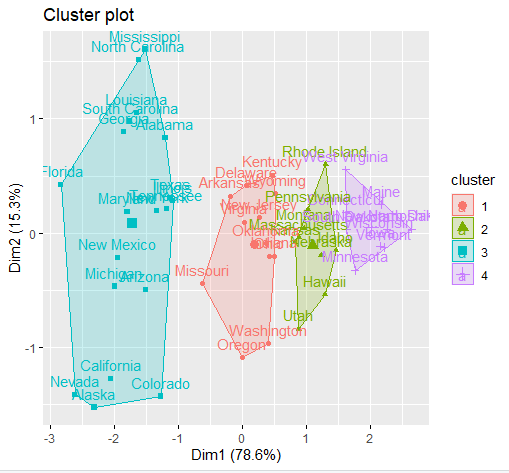 TIPS:善用help,无论是学习python还是R,对我们都大有助益~  help一下,就可以快速查到kmeans包的用法说明啦 help一下,就可以快速查到kmeans包的用法说明啦 查阅fviz_cluster详细参数列表5 本篇小结 查阅fviz_cluster详细参数列表5 本篇小结K-Means聚类由于其本身原理通俗易懂、执行简单有效、聚类速度快、聚类结果可解释性强的优点,得到了广泛的应用。然而,传统的K-Means也存在不少缺陷,比如对K值的选择没有准则可依循,聚类结果的好坏依赖于对初始聚类中心的选择,容易陷入局部最优解,对异常数据较为敏感,只能处理数值属性的数据,聚类结果可能不平衡[4]等等。因此我们往往会从K值的选取、初始聚类中心点的选取、相似性和距离度量、离群点的检测和去除等方面对算法进行改进。 K-Means基本原理虽简单,但本文希望通过各种优化改进的思路,打开大家的思维,引导大家深入思考这样一种聚类算法背后的本质。 参考文献: [1] 杨善林,李永森,胡笑旋,潘若愚.K-MEANS算法中的K值优化问题研究[J].系统工程理论与实践,2006,(02):97-101. [2] 杨俊闯,赵超.K-Means聚类算法研究综述[J].计算机工程与应用,2019,55(23):7-14+63. [3] 王千,王成,冯振元,叶金凤.K-means聚类算法研究综述[J].电子设计工程,2012,20(07):21-24. [4] 贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007,(01):10-13. |
【本文地址】