| 分区和列操作 | 您所在的位置:网站首页 › 查看分区信息怎么查询 › 分区和列操作 |
分区和列操作
|
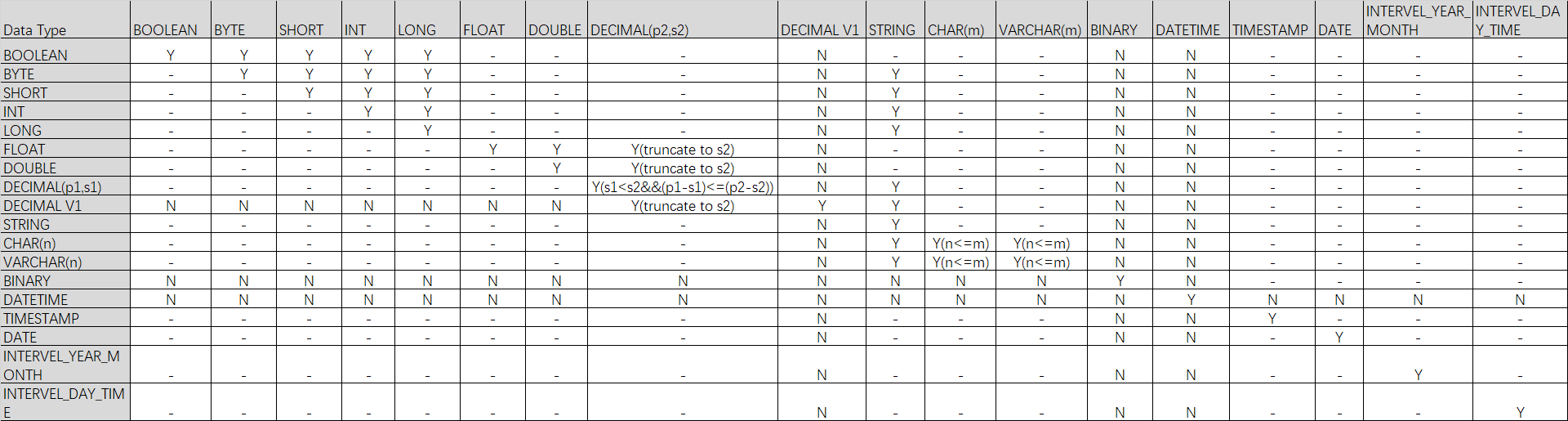
MaxCompute SQL的分区和列操作命令如下。 类型 操作 功能 角色 操作入口 分区操作 添加分区 为已存在的分区表新增分区。 具备修改表权限(Alter)的用户 本文中的命令您可以在如下工具平台执行: MaxCompute客户端 使用SQL分析连接 使用云命令行(odpscmd)连接 使用DataWorks连接 MaxCompute Studio 删除分区 为已存在的分区表删除分区。 修改分区的更新时间 修改分区表中分区的LastModifiedTime。 修改分区值 修改分区表的分区值。 合并分区 对分区表的分区进行合并,即同一个分区表下的多个分区合并成一个分区,同时删除被合并的分区维度的信息,把数据移动到指定分区。 清空分区数据 清空指定分区的数据。 列操作 添加列或注释 为已存在的非分区表或分区表添加列或注释。 删除列 删除已存在的非分区表或分区表的列。 更改列数据类型 更改已存在列的数据类型。 修改列的顺序 调整表中指定列的顺序。 修改列名 为已存在的非分区表或分区表修改列名称。 修改列注释 为已存在的非分区表或分区表修改列注释。 修改列名及注释 为已存在的非分区表或分区表同时修改列名称和列注释。 修改表的列非空属性 修改非分区列的非空属性。 使用限制目前支持TINYINT、SMALLINT、INT、BIGINT、CHAR、VARCHAR和STRING数据类型的字段设为分区列。 单表分区层级最多6级。 单表分区数最多允许60000个分区。 一次最多查询分区数为10000个。 使用表结构变更(Schema Evolution)限制: 表结构变更包括对现有表新增复杂数据类型列、删除列、修改列顺序和修改列的数据类型。在下列场景中,如果执行了更改表的列顺序、添加新列并修改列顺序或删除列这三种操作,会使表的读写行为发生变化: 作业类型是MapReduce 1.0时,Graph任务无法读写修改的表。 CUPID作业只有Spark以下版本可以读表,但是不可以写表: Spark-2.3.0-odps0.34.0 Spark-3.1.1-odps0.34.0 PAI作业可以读表,但不可以写表。 Hologres作业在1.3版本之前,Hologres引用修改的表作为外部表时,无法读写该表。 表做过表结构变更操作后,不支持CLONE TABLE。 Streaming Tunnel在写入表时,不可以修改表结构,否则会发生错误。 Transaction类型的分区表不支持merge partition操作。 Delta Table类型的非分区表不支持清空操作、不支持更改表的write.bucket.num属性。 添加分区为已存在的分区表新增分区。 限制条件 MaxCompute单表支持的分区数量上限为6万个。 对于有多级分区的表,如果需要添加新的分区值,必须指明全部的分区。 仅支持新增分区值,不支持新增分区字段。 命令格式 alter table add [if not exists] partition [partition partition ...];参数说明 table_name:必填。待新增分区的分区表名称。 if not exists:可选。如果未指定if not exists而同名的分区已存在,会执行失败并返回报错。 pt_spec:必填。新增的分区,格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。分区字段不区分大小写,分区值区分大小写。 使用示例 示例1:给表sale_detail添加一个分区,用来存储2013年12月杭州地区的销售记录。 alter table sale_detail add if not exists partition (sale_date='201312', region='hangzhou');示例2:给表sale_detail同时添加两个分区,用来存储2013年12月北京和上海地区的销售记录。 alter table sale_detail add if not exists partition (sale_date='201312', region='beijing') partition (sale_date='201312', region='shanghai');示例3:给表sale_detail添加分区,仅指定一个分区字段sale_date,返回报错,需要同时指定2个分区字段sale_date和region。 alter table sale_detail add if not exists partition (sale_date='20111011');示例4:增加Delta Table表分区 --创建delta table表 create table mf_tt (pk bigint not null primary key, val bigint not null) partitioned by (dd string, hh string) tblproperties ("transactional"="true"); --添加分区 alter table mf_tt add partition (dd='01', hh='01');示例5:修改Delta Table表属性 --更新bucket数据,目前只支持分区表,不支持非分区表 alter table mf_tt3 set tblproperties("write.bucket.num"="64"); --更新retain属性 alter table mf_tt3 set tblproperties("acid.data.retain.hours"="60");删除分区为已存在的分区表删除分区。 MaxCompute支持通过条件筛选方式删除分区。如果您希望一次性删除符合某个规则条件的多个分区,可以使用表达式指定筛选条件,通过筛选条件匹配分区并批量删除分区。 限制条件 每个分区过滤子句只能访问一个分区列。 表达式用到的函数必须是内建的Scalar函数。 注意事项 删除分区之后,MaxCompute项目的存储量会降低。 您可以结合MaxCompute提供的生命周期功能,实现自动回收旧分区的能力。更多生命周期信息,请参见生命周期。 命令格式 未指定筛选条件 --一次删除一个分区。 alter table drop [if exists] partition ; --一次删除多个分区。 alter table drop [if exists] partition ,partition [,partition ....];指定筛选条件 alter table drop [if exists] partition ;参数说明 table_name:必填。待删除分区的分区表名称。 if exists:可选。如果未指定if exists且分区不存在,则返回报错。 pt_spec:必填。删除的分区。格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。分区字段不区分大小写,分区值区分大小写。 partition_filtercondition:指定筛选条件时必填。分区筛选条件,不区分大小写。格式为: partition_filtercondition : partition ( ) | partition (scalar() ) | partition ( AND|OR ) | partition (NOT ) | partition ()[,partition (), ...]partition_col:分区名称。 relational_operators:关系运算符,详情请参见运算符。 partition_col_value:分区列比较值或正则表达式,与分区列数据类型保持一致。 scalar():Scalar函数。Scalar函数基于输入值生成对应的标量,对分区列的值(partition_col)进行处理后再按照指定的关系运算符relational_operators与partition_col_value做比较。 分区过滤条件支持逻辑运算符NOT、AND和OR。支持通过NOT过滤条件子句,取过滤规则的补集。支持多个过滤条件子句以AND或OR的关系组成整体分区匹配规则。 支持多个分区过滤子句,当多个分区过滤子句以英文逗号(,)分隔时,每个过滤子句的逻辑以OR的关系组成整体分区匹配规则。 使用示例 未指定筛选条件 --从表sale_detail中删除一个分区,2013年12月杭州分区的销售记录。 alter table sale_detail drop if exists partition(sale_date='201312',region='hangzhou'); --从表sale_detail中同时删除两个分区,2013年12月杭州和上海分区的销售记录。 alter table sale_detail drop if exists partition(sale_date='201312',region='hangzhou'),partition(sale_date='201312',region='shanghai');指定筛选条件 --创建分区表。 create table if not exists sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned by (sale_date STRING); --添加分区。 alter table sale_detail add if not exists partition (sale_date= '201910') partition (sale_date= '201911') partition (sale_date= '201912') partition (sale_date= '202001') partition (sale_date= '202002') partition (sale_date= '202003') partition (sale_date= '202004') partition (sale_date= '202005') partition (sale_date= '202006') partition (sale_date= '202007'); --批量删除分区。 alter table sale_detail drop if exists partition(sale_date < '201911'); alter table sale_detail drop if exists partition(sale_date >= '202007'); alter table sale_detail drop if exists partition(sale_date LIKE '20191%'); alter table sale_detail drop if exists partition(sale_date IN ('202002','202004','202006')); alter table sale_detail drop if exists partition(sale_date BETWEEN '202001' AND '202007'); alter table sale_detail drop if exists partition(substr(sale_date, 1, 4) = '2020'); alter table sale_detail drop if exists partition(sale_date < '201912' OR sale_date >= '202006'); alter table sale_detail drop if exists partition(sale_date > '201912' AND sale_date '202004'); --支持多个分区过滤表达式,表达式之间是OR的关系。 alter table sale_detail drop if exists partition(sale_date < '201911'), partition(sale_date >= '202007'); --添加其他格式分区。 alter table sale_detail add IF NOT EXISTS partition (sale_date= '2019-10-05') partition (sale_date= '2019-10-06') partition (sale_date= '2019-10-07'); --批量删除分区,使用正则表达式匹配分区。 alter table sale_detail drop if exists partition(sale_date RLIKE '2019-\\d+-\\d+'); --创建多级分区表。 create table if not exists region_sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned by (sale_date STRING , region STRING ); --添加分区。 alter table region_sale_detail add IF NOT EXISTS partition (sale_date= '201910',region = 'shanghai') partition (sale_date= '201911',region = 'shanghai') partition (sale_date= '201912',region = 'shanghai') partition (sale_date= '202001',region = 'shanghai') partition (sale_date= '202002',region = 'shanghai') partition (sale_date= '201910',region = 'beijing') partition (sale_date= '201911',region = 'beijing') partition (sale_date= '201912',region = 'beijing') partition (sale_date= '202001',region = 'beijing') partition (sale_date= '202002',region = 'beijing'); --执行如下语句批量删除多级分区,两个匹配条件是或的关系,会将sale_date小于201911或region等于beijing的分区都删除掉。 alter table region_sale_detail drop if exists partition(sale_date < '201911'),partition(region = 'beijing'); --如果删除sale_date小于201911且region等于beijing的分区,可以使用如下方法。 alter table region_sale_detail drop if exists partition(sale_date < '201911', region = 'beijing');批量删除多级分区时,在一个partition过滤子句中,不能根据多个分区列编写组合条件匹配分区,如下语句会报错FAILED: ODPS-0130071:[1,82] Semantic analysis exception - invalid column reference region, partition expression must have one and only one column reference。 --分区过滤子句只能访问一个分区列,如下语句报错。 alter table region_sale_detail drop if exists partition(sale_date < '201911' AND region = 'beijing');修改分区的更新时间MaxCompute SQL提供touch操作,用于修改分区表中分区的LastModifiedTime。此操作会将LastModifiedTime修改为当前时间。此时,MaxCompute会认为数据有变动,重新计算生命周期。 使用限制 对于有多级分区的表,必须指明全部的分区。 命令格式 alter table touch partition ();参数说明 table_name:必填。待修改分区更新时间的分区表名称。如果表不存在,则返回报错。 pt_spec:必填。需要修改更新时间的分区信息。格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。如果指定的分区字段或分区值不存在,则返回报错。 使用示例 --修改表sale_detail的分区sale_date='201312', region='shanghai'的LastModifiedTime。 alter table sale_detail touch partition (sale_date='201312', region='shanghai');修改分区值MaxCompute SQL支持通过rename操作更改分区表的分区值。 使用限制 不支持修改分区列的列名,只能修改分区列对应的值。 对于有多级分区的表,必须指明全部的分区。 命令格式 alter table partition () rename to partition ();参数说明 table_name:必填。待修改分区值的表名称。 pt_spec:必填。需要修改分区值的分区信息。格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。如果指定的分区字段或分区值不存在,则返回报错。 new_pt_spec:必填。修改后的分区信息。格式为(partition_col1 = new_partition_col_value1, partition_col2 = new_partition_col_value2, ...)。partition_col是分区字段,new_partition_col_value是新分区值。 使用示例 --修改表sale_detail的分区值。 alter table sale_detail partition (sale_date = '201312', region = 'hangzhou') rename to partition (sale_date = '201310', region = 'beijing');合并分区MaxCompute SQL提供merge partition对分区表的分区进行合并,即将同一个分区表下的多个分区合并成一个分区,同时删除被合并的分区维度的信息,把数据移动到指定分区。 使用限制 不支持外部表,聚簇表合并后的分区会消除聚簇属性。 一次性合并分区数量限制为4000个。 命令格式 alter table merge [if exists] partition () [, partition() ...] overwrite partition () [purge];参数说明 table_name:必填。待合并分区的分区表名称。 if exists:可选。如果未指定if exists,且分区不存在,会执行失败并返回报错。如果指定if exists后不存在满足merge条件的分区,则不生成新分区。如果运行过程中出现源数据被并发修改(包括insert、rename或drop)时,即使指定if exists也会报错。 predicate:必填。筛选待合并分区需要满足的条件。 fullpartitionSpec:必填。目标分区信息。 purge:可选关键字。选择该字段,则会清理session目录,默认清理3天内的日志。详情请参见Purge。 使用示例 示例1:合并满足指定条件的分区到目标分区。 --查看分区表的分区。 show partitions intpstringstringstring; ds=20181101/hh=00/mm=00 ds=20181101/hh=00/mm=10 ds=20181101/hh=10/mm=00 ds=20181101/hh=10/mm=10 --合并所有满足hh='00'的分区到hh='00',mm='00'中。 alter table intpstringstringstring merge partition(hh='00') overwrite partition(ds='20181101', hh='00', mm='00'); --查看合并后的分区。 show partitions intpstringstringstring; ds=20181101/hh=00/mm=00 ds=20181101/hh=10/mm=00 ds=20181101/hh=10/mm=10示例2:合并指定的多个分区到目标分区。 --合并多个指定分区。 alter table intpstringstringstring merge if exists partition(ds='20181101', hh='00', mm='00'), partition(ds='20181101', hh='10', mm='00'), partition(ds='20181101', hh='10', mm='10') overwrite partition(ds='20181101', hh='00', mm='00') purge; --查看分区表的分区。 show partitions intpstringstringstring; ds=20181101/hh=00/mm=00清空分区数据清空分区表中指定分区的数据。 MaxCompute支持通过条件筛选方式清空分区数据。如果您希望一次性删除符合某个规则条件的一个或多个分区,可以使用表达式指定筛选条件,通过筛选条件匹配分区并批量清空分区数据。 命令格式 未指定筛选条件 truncate table partition [, partition ....];指定筛选条件 truncate table partition ;参数说明 table_name:必填。待清空分区数据的分区表名称。 pt_spec:必填。待清空数据的分区。格式为(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。partition_col是分区字段,partition_col_value是分区值。分区字段不区分大小写,分区值区分大小写。 partition_filtercondition:指定筛选条件时必填。分区筛选条件,不区分大小写。格式为: partition_filtercondition : partition ( ) | partition (scalar() ) | partition ( AND|OR ) | partition (NOT ) | partition ()[,partition (), ...]partition_col:分区名称。 relational_operators:关系运算符,详情请参见运算符。 partition_col_value:分区列比较值或正则表达式,与分区列数据类型保持一致。 scalar():Scalar函数。Scalar函数基于输入值生成对应的标量,对分区列的值(partition_col)进行处理后再按照指定的关系运算符relational_operators与partition_col_value做比较。 分区过滤条件支持逻辑运算符NOT、AND和OR。支持通过NOT过滤条件子句,取过滤规则的补集。支持多个过滤条件子句以AND或OR的关系组成整体分区匹配规则。 支持多个分区过滤子句,当多个分区过滤子句以英文逗号(,)分隔时,每个过滤子句的逻辑以OR的关系组成整体分区匹配规则。 使用示例 未指定筛选条件 --从表sale_detail中清空一个分区,清空2013年12月杭州地域的销售记录。 truncate table sale_detail partition(sale_date='201312',region='hangzhou'); --从表sale_detail中同时清空两个分区,清空2013年12月杭州和上海地域的销售记录。 truncate table sale_detail partition(sale_date='201312',region='hangzhou'), partition(sale_date='201312',region='shanghai');指定筛选条件 --从表sale_detail中清空多个分区,清空杭州地域下sale_date以2013开头的销售记录。 truncate table sale_detail partition(sale_date like '2013%' and region='hangzhou');清空Delta Table非分区表 --清空非分区表,表类型必须为非分区表, 否则报错 truncate table mf_tt2; 添加列或注释为已存在的非分区表或分区表添加列或注释。 说明MaxCompute已支持添加STRUCT类型的列,例如struct、map。如果需要开通此功能,请设置以下参数,同时请注意使用限制,修改该参数需要等待10分钟后才会生效: setproject odps.schema.evolution.enable=true;设置项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。 命令格式 ALTER TABLE ADD columns [if not exists] ( comment [''] [, comment ''...] );参数说明 table_name:必填。待新增列的表名称。添加的新列不支持指定顺序,默认在最后一列。 col_name:必填。新增列的名称。 type:必填。新增列的数据类型。 col_comment:可选。新增列的注释。 使用示例 示例1:给表sale_detail添加两个列。 ALTER TABLE sale_detail ADD columns if not exists(customer_name STRING, education BIGINT);示例2:给表sale_detail添加两个列并同时添加列注释。 ALTER TABLE sale_detail ADD columns (customer_name STRING comment '客户', education BIGINT comment '教育' );示例3:给表sale_detail添加一个复杂数据类型列。 ALTER TABLE sale_detail ADD columns (region struct);示例4:增加Delta Table的列。 ALTER TABLE mf_tt ADD columns (val2 bigint);示例5:给表sale_detail增加ID列SQL会返回成功,但实际并不会重复增加。 --返回成功,但实际并不会重复增加ID列 ALTER TABLE sale_detail ADD columns if not exists(id bigint);删除列为已存在的非分区表或分区表删除指定的单个或多个列。 说明如果需要开通此功能,请设置以下参数,同时请注意使用限制,修改该参数需要等待10分钟后才会生效: setproject odps.schema.evolution.enable=true;设置项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。 命令格式 alter table drop columns [, ...];参数说明 table_name:必填。待删除列的表名称。 col_name:必填。待删除的列名称。 示例:删除表的列 --删除表sale_detail的列customer_id。输入yes确认后,即可删除列。 alter table sale_detail drop columns customer_id; --删除表sale_detail的列shop_name和customer_id。输入yes确认后,即可删除列。 alter table sale_detail drop columns shop_name, customer_id;更改列数据类型为已存在的列更改数据类型。 说明如果需要开通此功能,请设置以下参数,同时请注意使用限制,修改该参数需要等待10分钟后才会生效: setproject odps.schema.evolution.enable=true;设置项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。 命令格式。 alter table change [column] ;参数说明。 table_name:必填。待修改列数据类型的表名称。 old_column_name:必填。待修改列数据类型的列名称。 new_column_name:必填。修改列数据类型后的列名称。old_column_name可以与new_column_name保持一致,表示不修改列名称。但是new_column_name不能与除old_column_name之外的列名称相同。 new_data_type:必填。待修改的列修改后的数据类型。 使用示例。 --将mf_evol_t3表的id字段由int转化为bigint alter table mf_evol_t3 change id id bigint; --将mf_evol_t3表的id字段类型由bigint转化为string alter table mf_evol_t3 change column id id string;数据类型支持转换表。 说明Y表示支持转换;N表示不支持转换;-表示不涉及;Y()表示满足括号内的条件支持转换。
为已存在的非分区表或分区表修改列顺序。 说明如果需要开通此功能,请设置以下参数,同时请注意使用限制,修改该参数需要等待10分钟后才会生效: setproject odps.schema.evolution.enable=true;设置项目空间的Project级属性,需操作账号为项目的Owner或者账号被赋予了项目级别的Super_Administrator或Admin角色,操作详情请参见为用户赋予内置管理角色。 命令格式 alter table change after ;参数说明 table_name:必填。待修改列顺序的表名称。 old_column_name:必填。待修改顺序的列的原始名称。 new_col_name:必填。修改后的列名称。new_col_name可以与old_column_name保持一致,表示不修改列名称。但new_col_name不能与除old_column_name的之外的列名称相同。 column_type:必填。待修改的列的原始数据类型。不可修改。 column_name:必填。将待调整顺序的列调整至column_name之后。 使用示例 --修改表sale_detail的列customer_id为customer并位于total_price之后。 alter table sale_detail change customer_id customer string after total_price; --修改表sale_detail的列customer_id位于total_price之后,不修改列名称。 alter table sale_detail change customer_id customer_id string after total_price;修改列名为已存在的非分区表或分区表修改列名称。 命令格式 alter table change column rename to ;参数说明 table_name:必填。待修改列名的表名称。 old_col_name:必填。待修改的列名称。old_col_name必须是已存在的列。 new_col_name:必填。修改后的列名称。表中不能有名为new_col_name的列。 使用示例 --修改表sale_detail的列名customer_name为customer。 alter table sale_detail change column customer_name rename to customer;修改列注释为已存在的非分区表或分区表修改列注释。 语法格式 alter table change column comment '';参数说明 table_name:必填。待修改列注释的表名称。 col_name:必填。待修改注释的列名称。col_name必须是已存在的列。 col_comment:必填。修改后的注释信息。注释内容为长度不超过1024字节的有效字符串,否则报错。 使用示例 --修改表sale_detail的列customer的注释。 alter table sale_detail change column customer comment 'customer';修改列名及注释修改非分区表或分区表的列名或注释。 命令格式 alter table change column comment '';参数说明 table_name:必填。需要修改列名以及注释的表名称。 old_col_name:必填。需要修改的列名称。old_col_name必须是已存在的列。 new_col_name:必填。新的列名称。表中不能有名为new_col_name的列。 column_type:必填。列的数据类型。 col_comment:可选。修改后的注释信息。内容最长为1024字节。 使用示例 --修改表sale_detail的列名customer_name为customer_newname,注释“客户”为“customer”。 alter table sale_detail change column customer_name customer_newname STRING comment 'customer';修改表的列非空属性修改表的非分区列的非空属性。即如果表的非分区列值禁止为NULL,您可以通过本命令修改分区列值允许为NULL。 您可以通过desc extended table_name;命令查看Nullable属性值,判断列的非空属性。如果Nullable为true,表示允许为NULL;如果Nullable为false,表示禁止为NULL。 使用限制 修改分区列值允许为NULL后,不可回退,不支持再修改分区列值禁止为NULL,请谨慎操作。 命令格式 alter table change column null;参数说明 table_name:必填。待修改列非空属性的表名称。 old_col_name:必填。待修改的非分区列的名称。old_col_name必须是已存在的非分区列。 使用示例 --创建一张分区表,id列禁止为NULL。 create table null_test(id int not null, name string) partitioned by (ds string); --修改id列允许为NULL。 alter table null_test change column id null;相关文档更多关于表操作的命令请参见表操作。 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |