| 指标赋权与评价类方法总结 | 您所在的位置:网站首页 › 权重值的计算 › 指标赋权与评价类方法总结 |
指标赋权与评价类方法总结
|
指标赋权与综合评价方法
一、主观赋权1、AHP层次分析法
二、客观赋权1、主成分分析2、熵权法
三、组合赋权法四、综合评价1、Topsis2、数据包络法
五、GRA灰色关联度分析
一、主观赋权
1、AHP层次分析法
(1)模型简介 层次分析法是一种解决多目标的复杂问题的定性与定量相结合的决策分析方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的问题。 (2)步骤 建立层次结构模型构造判断矩阵 标度含义1同等重要性3稍微重要5明显重要7非常重要9极端重要2,4,6,8上述两相邻判断的中值倒数如果A与B相比如果标度为3,则B与A相比为1/3 层次单排序及一致性检验 首先需要进行一致性指标CI的计算
C
I
=
λ
m
a
x
−
n
n
−
I
CI=\frac{\lambda_{max}-n}{n-I}
CI=n−Iλmax−n当CI=0时,判断矩阵具有完全一致性。-n越大,CI越大,则判断矩阵的一致性就越差。为了检验判断矩阵是否具有满意的一致性,需要将CI与平均随机一致性指标RI进行比较。
矩阵阶数123456789RI000.580.961.121.241.321.411.45 首先需要进行一致性指标CI的计算
C
I
=
λ
m
a
x
−
n
n
−
I
CI=\frac{\lambda_{max}-n}{n-I}
CI=n−Iλmax−n当CI=0时,判断矩阵具有完全一致性。-n越大,CI越大,则判断矩阵的一致性就越差。为了检验判断矩阵是否具有满意的一致性,需要将CI与平均随机一致性指标RI进行比较。
矩阵阶数123456789RI000.580.961.121.241.321.411.45
若判断矩阵 C R = C I R I < 0.10 CR=\frac{CI}{RI}极大型指标 X i {X_i} Xi是一组中间型指标序列,且最佳的区间为 [ a , b ] [a,b] [a,b],那么正向化的公式为 M = m a x a − m i n X i , m a x X i − b M=max{a-min{X_i},max{X_i}-b} M=maxa−minXi,maxXi−b 2、对正向化矩阵进行标准化,目的是消除不同指标量纲的影响 3、计算得分 假设有n个要评价的对象,m个评价指标的标准化矩阵 (1)定义最大值 (2)定义最小值 (3)定义第i(i=1,2,…,n)个评价对象与最大值的距离 (4)定义第i(i=1,2,…,n)个评价对象与最小值的距离 因此,可以计算得出第i(i=1,2,…,n)个评价对象未归一化的得分: 很明显,当01,且越大越小,即越接近最大值 4、归一化评分 (3)案例 题目:评价表1中20条河流的水质情况 已知:含氧量越高越好;PH值越接近7越好;细菌总数越少越好;植物性营养物量介于10—20之间最佳,超过20或低于10均不好 解题思路: 1、将各项指标正向化 PH值(中间型转极大型)、细菌总数(极小型转极大型)、植物性营养物量(区间型转极大型) 2、正向化后的矩阵进行标准化 3、进行打分(20个评价对象(河流),4个评价指标(含氧量、PH值、细菌总数、植物性营养物量)) 4、分数归一化 5、分析评分,得分最高的河流水质最好,得到表2、图1所示结果 (4)学习参考资料 评价类模型——TOPSIS法(优劣解距离法)学习一 评价类模型——TOPSIS法(优劣解距离法)学习二 2、数据包络法(1)方法简介 绩效评估是评估组织或个人如何以较少的资源获得较多的产出结果的多属性评估,也称之为成本效益分析。数据包络分析是 A.Charnes, W.W.Copper 和 E.Rhodes 在 1978 年提出的评价多指标输入输出,衡量系统有效性的方法。将属性划分为投入项、产出项(成本型、效益型指标),不预先设定权重,只关心总产出与总投入,以其比率作为相对效率。数据包络分析有多种模式,主要为:CCR 模式,BBC 模式、交叉模式、A&P 模式。 (2)步骤 1、构建决策单元 要点:确定“投入”和“产出” (3)优缺点 优点 同时考虑多项的投入与产出属性,来评估决策单位和方案的相对效率,不依赖于人为选择权重,对于决策问题中不可度量糅合的属性具有天然的优势。对测量单位的改变不敏感,具有较强的鲁棒性。模型依赖于线性规划问题的基本算法,求解速度快。 缺点 评估结果是相对效率而非绝对效率,因此效率为 1 只能说明在当前资源下不同方案同等有效,并不代表没有改进之处,模型不依赖于权重的选择,将所有的投入、产出资源认为同等重要,一定程度上损失模型的可靠性。 (4)参考资料 方法详细介绍 DEA(数据包络分析)介绍(python实现) RSR(秩和比综合评价法)介绍(python实现) 一个案例(lingo实现) 五、GRA灰色关联度分析(1)简介 灰色关联度分析(Grey Relation Analysis,GRA),是一种多因素统计分析的方法。简单来讲,就是在一个灰色系统中,我们想要了解其中某个我们所关注的某个项目受其他的因素影响的相对强弱,再直白一点,就是说:我们假设以及知道某一个指标可能是与其他的某几个因素相关的,那么我们想知道这个指标与其他哪个因素相对来说更有关系,而哪个因素相对关系弱一点,依次类推,把这些因素排个序,得到一个分析结果,我们就可以知道我们关注的这个指标,与因素中的哪些更相关。 (2)具体算法 1、确定母序列 母序列即参考序列,这里要找到子序列和参考序列的关联程度。 2、归一化(无量纲化) 减少数据的绝对数值的差异,将它们统一到近似的范围内,然后重点关注其变化和趋势。主要方法有初值化和均值化。 初值化:把这一个序列的数据统一除以最开始的值,由于同一个因素的序列的量级差别不大,所以通过除以初值就能将这些值都整理到1这个量级附近。 均值化:把这个序列的数据除以均值,由于数量级大的序列均值比较大,所以除掉以后就能归一化到1的量级附近。 3、计算灰色关联系数 4、计算关联系数均值,形成关联序 (4)算法优缺点 1、优点 此方法的优点在于思路明晰,可以在很大程度上减少由于信息不对称带来的损失,并且对数据要求较低,工作量较少。 2、缺点 其主要缺点在于要求需要对各项指标的最优值进行现行确定,主观性过强,同时部分指标最优值难以确定。 (5)参考文献 灰色关联度分析原理详解(matlab) 灰色关联分析的理论及应用(这个详细 matlab、python) |
 2、建立DEA效率评估模型(CCR模式) 决策单元k的效益评价指数为:
2、建立DEA效率评估模型(CCR模式) 决策单元k的效益评价指数为: 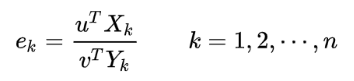 从投入资源的角度来看,在当前产出的水准下,比较投入资源的使用情况,以此作为效益评价的依据,这种模式称为“投入导向模式”。但这种模型不是传统的线性规划模型, 难以求最优解, 因此将其线性化后, 取对偶模型,为如下模型(评价决策单元k效益的CCR模式线性规化模型):
从投入资源的角度来看,在当前产出的水准下,比较投入资源的使用情况,以此作为效益评价的依据,这种模式称为“投入导向模式”。但这种模型不是传统的线性规划模型, 难以求最优解, 因此将其线性化后, 取对偶模型,为如下模型(评价决策单元k效益的CCR模式线性规化模型): 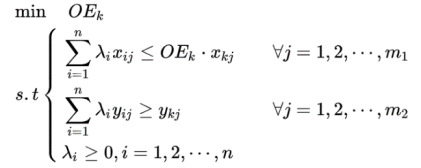 为加速模型求解及分析产能效应,为上述方程引入松弛变量,。其中 称为差额变数,表示该决策单元为达到 “DEA 有效” 应减少的投入量,称为超额变数,代表为达到 “DEA 有效” 应增加的产出量。引入非阿基米德数 ε (non-Archimedean constant) CCR 模式线性规划模型化为:
为加速模型求解及分析产能效应,为上述方程引入松弛变量,。其中 称为差额变数,表示该决策单元为达到 “DEA 有效” 应减少的投入量,称为超额变数,代表为达到 “DEA 有效” 应增加的产出量。引入非阿基米德数 ε (non-Archimedean constant) CCR 模式线性规划模型化为:  3、分层序列法求解 使用分层序列法进行求解。第一阶段求解OEk的最小值,在第二阶段求解两项和的最大值,即
3、分层序列法求解 使用分层序列法进行求解。第一阶段求解OEk的最小值,在第二阶段求解两项和的最大值,即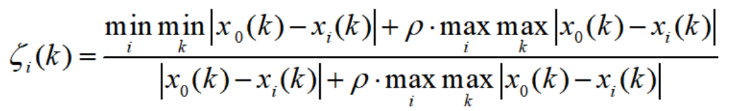 对公示的简单理解: 当ρ取0的时候,该式分子表示所有因素的维度中,与参考序列距离最近的维度上的距离;分母相当于归一化。 当ρ不取0的时候,相当于分子分母同时增加相同的数(实际上是添加溶质的溶液的问题)。 总之,ρ是控制灰色关联系数区分度的一个系数,ρ取值从0到1,ρ越小,区分度越大,一般取0.5较为合适。而灰色关联系数取值落在0到1之间。
对公示的简单理解: 当ρ取0的时候,该式分子表示所有因素的维度中,与参考序列距离最近的维度上的距离;分母相当于归一化。 当ρ不取0的时候,相当于分子分母同时增加相同的数(实际上是添加溶质的溶液的问题)。 总之,ρ是控制灰色关联系数区分度的一个系数,ρ取值从0到1,ρ越小,区分度越大,一般取0.5较为合适。而灰色关联系数取值落在0到1之间。 (3)算法总结 GRA算法本质上来讲就是提供了一种度量两个向量之间距离的方法,对于有时间性的因子,向量可以看成一条时间曲线,而GRA算法就是度量两条曲线的形态和走势是否相近。为了避免其他干扰,凸出形态特征的影响,GRA先做了归一化,将所有向量矫正到同一个尺度和位置,然后计算每个点的距离。最后,通过min min 和max max 的矫正,使得最终输出的结果落在0到1之间,从而符合系数的一般定义。rho调节不同关联系数之间的差异,换句话说,就是输出的分布,使其可以变得更加稀疏或者紧密。以数学角度要言之,该算法即度量已归一化的子向量与母向量的每一维度的l1-norm距离的倒数之和,并将其映射到0~1区间内,作为子母向量的关联性之度量的一种策略。
(3)算法总结 GRA算法本质上来讲就是提供了一种度量两个向量之间距离的方法,对于有时间性的因子,向量可以看成一条时间曲线,而GRA算法就是度量两条曲线的形态和走势是否相近。为了避免其他干扰,凸出形态特征的影响,GRA先做了归一化,将所有向量矫正到同一个尺度和位置,然后计算每个点的距离。最后,通过min min 和max max 的矫正,使得最终输出的结果落在0到1之间,从而符合系数的一般定义。rho调节不同关联系数之间的差异,换句话说,就是输出的分布,使其可以变得更加稀疏或者紧密。以数学角度要言之,该算法即度量已归一化的子向量与母向量的每一维度的l1-norm距离的倒数之和,并将其映射到0~1区间内,作为子母向量的关联性之度量的一种策略。【本文地址】