| Few | 您所在的位置:网站首页 › 权重值公式 › Few |
Few
|
摘要 本文从图像区域之间的最佳匹配的新角度开发了用于少样本图像分类的方法。使用Earth Mover's Distance(EMD)作为度量来计算密集图像表示之间的结构距离,以确定图像相关性。EMD生成具有最小匹配成本的结构元素之间的最优匹配流,用于计算图像距离以进行分类。为了EMD公式中声称元素的重要权重,设计一种交叉引用机制,可以有效地减轻由杂乱北京和大的类内外观变化引起的不利影响。为了实现k-shot分类,提出一学习一个结构化的全连接层,该层可以使用EMD直接对密集图像表示进行分类。基于隐函数定理,EMD可以作为一层插入到网络中进行端到端的训练。大量实验验证了算法的有效性,该算法在5个少样本分类数据集上显著优于最先进的方法。 论文标题:DeepEMD: Differentiable Earth Mover's Distance for Few-Shot Learning论文地址:[2003.06777] DeepEMD: Differentiable Earth Mover's Distance for Few-Shot Learning (arxiv.org)1 IntroDeep neural network have achieved great success in many vision taks,typically requiring a large amount of labled data。深度血液续方法的一个缺点是样本效率低,这雨人类的学习方式形成鲜明对比。(A notorious drawback of deep learning method is that they suffer from poor sample efficiency. This is in sharp contrast to how we humans learn.) 在机器学习中,少样本学习解决的就是这个问题,这通常作为更广泛的元学习的一个特例来解决。元学习试图学习一种能够以最小的适应努力推广到新任务的模型。元学习算法最受欢迎的研究之一就是少样本图像分类,其目的是仅使用有限数量的标记训练数据对新的图像进行分类。 为了解决这个问题,文献中一系列先前工作采用了基于度量的方法,这些学习在适当的特征空间中表示数据,并使用距离函数来预测图像标签。在标准图像分类网络的公式化之后,基于度量的方法通常使用卷积神经网络来学习图像特征表示,并用距离函数(如余弦距离,欧几里得距离)替换全连接层。这样的距离函数直接用于分类的测试图像和训练图像的嵌入之间的距离,这绕过了少样本设置下学习器的困难优化问题。由于深度学习模型的大容量和足够的训练图像,然而,他几乎不可避免地在低数据状态下被放大,从而对图像分类精度产生不利影响。此外,混合全局表示将难以很好地捕捉图像结构,并且可能会丢失有用的局部特征。局部特征可以提供跨类别的区分性和可转移信息,这是少样本分类场景中图像分类的重要线索。因此,期望基于度量的算法应该能够利用局部辨别信息并最小化由不相关区域引起的干扰。 确定两个复杂结构化表示相似性的自然方法是比较它们的构建块。困难在于没有对训练过程进行通信监督,并且并非所有的building elements都能在其他结构中找到对应的内容。为了解决上述问题,将少样本分类形式转换为最佳匹配的一个实例,并建议使用两个结构之间的最佳匹配成本来表示它们的不同性,给定由两幅图像生成的局部特征表示集,使用EMD来计算它们的结构相似性。EMD是计算结构表示之间距离的度量,最初是为图像检索而提出的。给定所有元素之间的距离,EMD可以获得具有最小总距离的两个结构之间的最佳匹配流。它可以被解释为相对于另一个重结构化表示的最小成本。动机如图1所示。EMD具有运输问题的公示,通过求解线性规划问题可以获得全局最小值。为了将优化问题嵌入到端到端训练的模型中,应用隐函数定理来形成关于问题参数的最优化变量的雅可比矩阵。探索了从图像中提取局部表示的多种方法,包括完全卷积网络、图像网格和图像区域采样。还研究了特征层和图像层的金字塔结构,以捕获不同尺度的局部表示。 EMD公式中一个重要的特定于问题的参数是每个元素的权重,权重较大的元素会生成更多的匹配流,从而对总距离有更大的贡献。理想情况下,算法应该具有灵活性,为不相关区域分配较少的权重,从而无论它们与那个元素匹配对总距离的贡献都较小。为了实现这一目标,提出一个交叉引用机制来确定元素的重要性。在所提出的交叉引用机制中,通过将每个节点与其他结构的全局统计信息进行比较来确定每个节点的权重。直观地说(Intuitively)与另一幅图像表现出更大相关性的图像区域更有可能是对象区域,应该分配更大的权重,而在计算时,应该尽可能消除两幅图像中不同时出现的高方差背景区域和对象部分权重的匹配成本。在呈现的多个support image的k-shot设置中,建议学习一个结构化的全连接层作为分类器进行分类,以利用不断增加的训练图像数量。结构化FC是标准全连接层的扩展,因为它用矢量集之间的EMD函数代替矢量之间的点积运算,使得结构化FC可以直接对特征图进行分类,结构化FC层还可以解释为学习由每个类别的匹配的dummy图像生成prototype嵌入,是的测试图像可以与他们中的每一个匹配以进行分类。 为了验证在多个数据集上进行了广泛实验,主要贡献总结如下: 提出一种交叉参考机制来生成EMD公式中元素的权重,这可以有效减少图像中不相关背景区域引入的噪声。建议学习k-shot设置中的结构化全连接层,该层能够使用EMD距离直接对图像的结构化表示进行分类。在5个流行的少样本分类基准数据集上的实验表明,在1-shot和5-shot上都显著由于基线方法,并实现最新性能。还证明了该方法可以有效改进图像检索任务重的许多深度度量方法。2 Related workFew-Shot Learning. 关于小样本学习的研究文献显示出极大的多样性,在维数不多的few-shot分类文献中,有两个主流,基于度量的方法和基于优化的方法。基于优化的方法是的模型参数适应low-shot regime。例如MAML及其许多变体旨在学习一个良好的模型初始化,该模型可以快速适应具有有限优化步骤的新任务。基于度量的方法旨在在表示适当的特征空间中的样本,其中不同类别的数据可以用距离度量来区分,为了实现这一目标,大多数方法将整个图像表示为特征空间中的数据点。还有一些作品利用局部特征进行预测,例如直接对每个局部特征进行预测,并融合其结果。或采用k-NN融和局部距离。交叉注意力网络使用注意力机制来凸显目标对象区域,并为少样本分类生成辨别特征。CrossTransformer计算query中的空间对应特征与few-shot分类的标记样本之间的距离。对k-shot问题的解决方案还与基于优化的方法相联系。本文学习一种分类器,该分类器可以直接使用推土机距离对结构化表示进行分类,并可以从不断增加的support样本中受益。 除了两种流行的方法外,还提出了许多有前途的方法来解决少样本分类问题,例如基于图论的工作、强化学习、可微SVM、生成模型、转换学习、地柜模型、自监督学习和最近的胶囊网络、时间卷积,对于其他计算机视觉任务,如图像分割,物体检测也很少研究过少样本学习。 Earth Mover's Distance. EMD最初提出作为基于纹理和颜色的图像检索的度量。EMD具有线性规划中研究的很好的运输问题的公式,因此可以通过求解线性规划来找到全局最优匹配。EMD有几个理想的特性,使其成为比较结构化表示的流行方法。手续爱你,EMD可以在没有明确对齐信息的情况下生成结构相似性。它将单个元素之间的距离扩展到集合和分布之间的距离;第二,集合中元素的数量可以变化。例如使用EWD测量两个文档之间的相似度,这计算了将文档中的单词嵌入转移到另一个文档中进行文档分类的最小成本。还有研究提出用超像素表示手的纹理和形状,并使用EMD来测量手势之间的差异,以进行手势识别。还有人将图形数据表示为与顶点相应的一组向量,并使用EMD确定两个图像的相似性以进行图形比较。 Parameterized optimization. 参数优化问题具有依赖于输入数据的参数化对象函数和约束。许多先前的工作都通过argmin算子研究了微分。还有研究提出通过只有等式约束的优化问题进行微分的方法。另外,还有根据凸维程序中的系数计算解的梯度,该方法可以扩展到大型问题。描述使用隐函数定理和内点方法计算问题参数的解的雅可比一般情况。利用相同的理论,设计一个批量二次规划求解器,作为一个可以集成到神经网络中进行端到端训练的层。还有人提出一种可微凸优化层,该层可以通过严格的凸程序进行区分,并允许用户以自然语法定义问题,而无需将问题转换为规范形式。还有人将组合构建块引入神经网络,端到端可训练网络可以通过组合求解器的任何黑盒实现生成信息性后向梯度。基于这些构建块设计一个端到端的网络,该网络结合了一个组合求解器来解决凸匹配问题。 3 Preliminary首先介绍晒样本分类文献中的一些初步概念。通用元学习算法旨在学习跨任务的可转移知识,其中在训练任务中学习的知识可以用于解决只有少量训练数据的新任务。在few-shot分类场景中,任务 \mathcal{J}_i 是对一组采样类进行分类,其特征是缺乏训练图像。具体来说,N-way K-shot任务表示在N个类上的分类,每个类中有K个训练样本。为了获得跨任务的泛化能力,模型的训练和测试通常与情景范式相一致。在情景范式中,批量任务被采用用于训练或评估。对于每个采样任务,训练集 S=\{(x_1^s, y_1^s), \dots, (x_{NK}^s, y_{NK}^s)\} 成为support set和测试集 S=\{(x_1^q, y_1^q), \dots, (x_{NK}^q, y_{NK}^q)\} 称为query set。其中 x_i 是图像, y_i \in \{ 1, \dots, N\} , K_Q 是每个类的测试图像数。在训练时,query set的真实标签提供学习监督,在推理时,重复地对任务进行抽样评估,并记录器平均准确性。 4 Method首先简要回顾推土机距离,并描述如何将one-shot分类公式化端到端训练的最佳匹配问题。然后,描述交叉引用机制来生成每个节点的权重,这是EMD公式中的一个重要参数,最后,演示了如何使用EMD来解决结构化全连接层的k-shot学习,框架概述如图2所示。  4.1 Revisiting the Earth Mover's Distance 4.1 Revisiting the Earth Mover's Distance推土机距离是两组加权目标或分布之间的距离度量,它基于单个物体之间的基本距离和每个元素的权重,它具有从线性规划中研究得很好的运输问题的形式。具体地,假设需要一组sources or suppliers \mathcal{S}=\{s_i | i=1,2,\dots,m\} 将货物运输到另一目的地或需求方 \mathcal{D}=\{d_j | j=1,2,\dots,k\} ,其中 s_i 表示供方 i 和 d_j 表示第 j 个需求方。从供应 i 到需求 j 的单位成本用 c_{ij} 表示。运输的单位数量用 x_{ij} 表示。运输问题的目标是找打一个最小从供应到需求方flow \tilde{{\mathcal{X}}} =\{\tilde{x_{ij}}| i=1,\dots,m,j=1,\dots,k\} \begin{array}{ll} \underset{x_{i j}}{\operatorname{minimize}} & \sum_{i=1}^{m} \sum_{j=1}^{k} c_{i j} x_{i j} \\ \text { subject to } & x_{i j} \geqslant 0, i=1, \ldots, m, j=1, \ldots, k \\ & \sum_{j=1}^{k} x_{i j}=s_{i}, \quad i=1, \ldots m \\ & \sum_{i=1}^{m} x_{i j}=d_{j}, \quad j=1, \ldots k \end{array} 可以在不影响总运输成本的情况下切换供方和需方的校色,这里的 s_i,d_j 也称为节点的权重,它控制每个节点生成的总匹配流,EMD寻求供方与需方之间的最佳匹配,以使得总体匹配成本最小化。全局匹配流 \tilde{{\mathcal{X}}} 可以通过求解线性规划问题来实现。 4.2 EMD for few-shot classification在少样本分类任务中,基于度量的方法旨在找到一个良好的距离度量和数据表示,以计算图像之间的距离,这些距离用于比较图像进行分类。与执行图像级嵌入之间的距离计算的先进方法不同,本文提倡使用有区别的局部信息,直觉上,作为少样本学习的目标直接生成对应于新类别的类别级嵌入时困难的。另一方面,将一个对象分解为一组可能在训练过程中看到的部分。例如车轮可以是跨类别的共享元素。如果在训练期间学习到这种表示,则对未看到的车辆类别进行分类可能很有用。因此,局部判别性表示可能提供更多跨类别的可转移信息。在本文提出的框架中,将图像分解为一组局部表示,通过为两个图像的局部嵌入分配适当的权重,使用它们之前的最佳匹配成本表示它们的不同姓,探索了从图像生成局部表示的三种策略,如图2所示。 1)Fully Convolutional Networks. 部署全卷网络FCN来生成图像的密集表示 \mathbf{U} \in \mathbb{R}^{H \times W\times C} ,其中H和W表示特征图的空间大小,C表示特征维度。每个图像表示包含局部特征向量 \{\mathbf{u}_1,\mathbf{u}_2,\dots,\mathbf{u}_{HW} \} 的几何,并且每个向量 \mathbf{u}_i 可以被视为几何中的节点,因此,两个图像的不相似性可以表示为两组向量之间的最佳匹配成本。2) Dividing the input image into grids. 将输入图像划分为网格,将图像均匀地裁剪成 H \times W 网格,然后将其馈送到CNN,网格单元中每个图像块都由CNN单独编码并生成特征向量,由所有patch生成的特征向量构成图像的嵌入集。3)Random sampling of image patches. 这里不是通过网络生成patch,而是在不同大小和纵横比的图像中随机采样M个块,然后将随机采样的patch重新缩放到相同的输入大小,并由CNN进行编码。这些采样patch的嵌入构成了图像的嵌入集。分别通过DeepEMD FCN,DeepEMD Grid和DeepEMD-sampling表示采用上述三种策略的网格。由于深度EMD玩个够中网格的大小和深度EMD采样中patch的数量是网络中的超参数,在第5.3节中进行了各种实验来研究这些参数的影响。还研究了图像层次和特征层次的金字塔结构,以在多个尺度上捕获局部表示,如图3所示。具体来说,将特征金字塔结构添加到DeepEMD FCN,并将图像金字塔添加至DeepEMD-Grid。特征金字塔将ROI池化应用于FCN生成的特征图,生成的特征向量与原始特征向量一起构成嵌入集。对于图像金字塔,只需要根据不同的网格大小裁剪patch,并将所有patch发送到CNN以生成嵌入集。 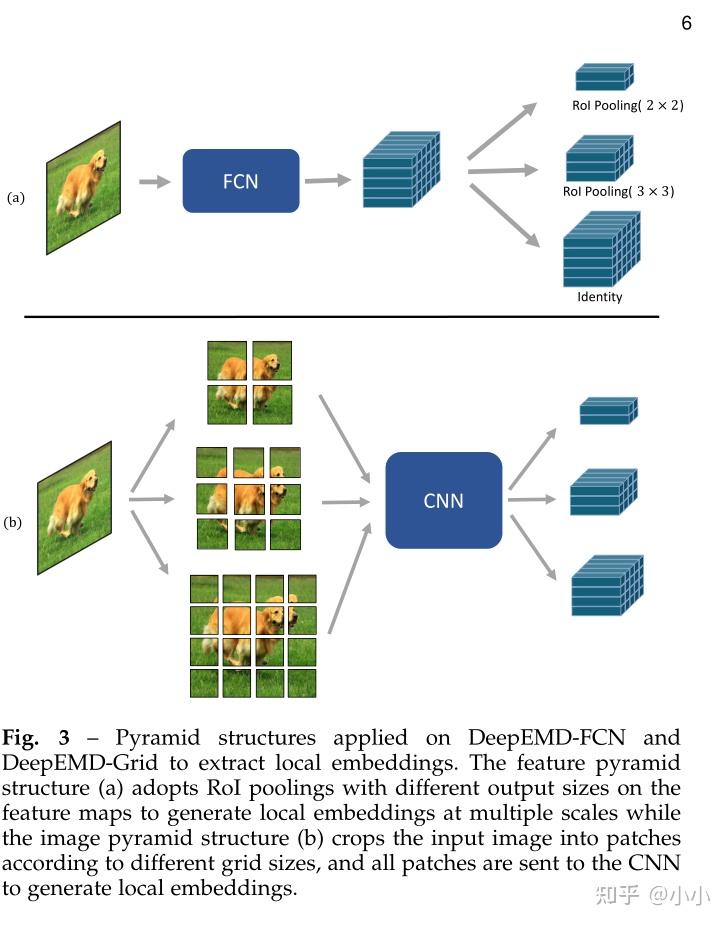 在获取两个图像的嵌入集后,遵循方程1中的原始EMD公式计算距离。具体来说,假设每个集合中有 H \times W 个向量,则通过计算嵌入节点之间的成对距离来获得单位成本: c_{ij} = 1- \frac{\mathbf{u_i}^T \mathbf{v}_i}{\parallel \mathbf{u_i} \parallel \parallel \mathbf{v_j} \parallel } 其中,具有相似表示的节点倾向于彼此之间产生小的匹配成本。关于权重 s_i,d_j 的生成,在第4.4节说明。一旦获得了最佳匹配流 \mathcal{X} ,就可以使用一下公式计算图形表示之间的相似性分数s: s(\mathbf{U}, \mathbf{V})=\sum_{i=1}^{H W} \sum_{j=1}^{H W}\left(1-c_{i j}\right) \tilde{x}_{i j} \\ 4.3 End-to-End Training为了将最佳匹配问题嵌入神经网络进行端到端的训练,重要的事使最佳匹配的解\mathcal{X}相对于问题参数 \theta 可微。在最优性KKT条件上应用隐函数定理来获得雅可比。为了完整性,将方程1的优化转换为紧凑矩阵形式:  这里 x \in \mathbb{R}^n 是优化变量,其中 n=m\times k 表示 \mathcal{X} 中匹配流的总数, \theta 是可微方程与早期层相关的问题参数。具体而言,为了构建原始优化的紧凑矩阵形式,为等式约束建立以下约束矩阵:   接下来是拉格朗日,KKT条件,看不懂了。得回重新学习高数!!!严重超出我的理解范围!~ 4.4 Weight Generation正如EMD公式中可以观察到的,一个重要的问题参数是每个节点的权重例如 s_i 它控制来自它的总匹配流 \sum_{j=1}^kx_{ij} 。直观地说,权重较大的节点在两个集合的比较重扮演着更重要的角色,而权重较小无论连接到哪个节点,小权重几乎不会影响总距离。采用EMD进行基于颜色的图像检索的开创性工作中,使用直方图作为基本特征,并对所有像素执行特征聚类以生成节点。每个节点的权重被设置为相应簇的大小,这是有意义的,因为为具有更多的像素的主要颜色分配较大的权重,这样检索的图像可以在视觉上接近query图像。然而,对于分类的特征通常包含高级语义信息的few-shot分类任务,像素的数量不一定反映重要性,通常在分类数据中中高具有目标对象更大背景区域的图像数据。因此,在匹配算法中,应为前景对象区域赋予较大的权重。然后可能很难定义前景区域,特别是单个图像中存在多个对象类别时,在不同情况下,对象既可以是前景,也可以是北京。因此,对于few-shot分类任务,两幅图像中共同出现的区域更有可能是前景,而不是通过单独检查单个图像来确定权重,应该通过比较两侧的节点来生成节点特征的权重。为了实现这一目标,提出交叉引用机制,该机制使用接待您特征和其他结构中的平均节点特征之间的点积来生成现相关性得分作为权重值:  其中, \mathbf{u}_i, \mathbf{v}_j, 表示两个特征图的向量,函数 \max (\cdot) 确保权重始终为非负。最后,将结构化中的所有权重标准化,以使两侧具有相同总权重进行匹配:  为了简单期间,这里以 s_i 为例, d_i 可以以相同的方式获得。交叉参考机制的目的是在两幅图像中对高方差北京区域赋予较少的权重,而对共同出现的目标区域赋予更多的权重。这也可以减少在两个图像中不同时出现的对象幕布的权重,从而在一定程度上允许部分匹配。所提出的距离度量仅基于高响应的质心区域和置信特征。 4.5 Structured Fully Connected LayerFC层的学习可以看做是为每个类别找到一个prototype向量,标准FC层如图4a所示。使用相同的公式,采用EMD作为距离函数的结构化全连接层,以直接对结构化特征进行分类。每个类的可学习参数编程一组向量,而不是一个向量,因此可以使用结构距离函数EMD进行图像分类,这也可以解释为学习由每个类的dummy图像生成的prototype特征图,结构化FC见图4b。固定网络主干,使用SGD通过从support集中采样数据来学习结构化全连接层中的参数,经过几次优化迭代后,通过计算query图像和SFC中每个prototype之间大的EMD来生成类别分数。  5 Experiments5.1 Implementation Details 5 Experiments5.1 Implementation Details网络为了和之前的作品进行公平比较,使用12层ResNet作为模型主干,这在少样本分类中被广泛使用。对于EMD网络和深度EMD采样,移除ResNet中的全连接,这样网络为输入图像块生成一个向量,对于DeepEMD FCN进一步去除全局平均池化,从而将网络转换为全卷积网络。具体而言,给定84×84的图像,模型生成大小为5×5×512的特征图,即25个特征向量。对于DeepEMD网络,将网格中局部pathc的区域稍作放大2被,以合并上下文信息,这有助于生成局部表示。 
|
【本文地址】