| 朴素贝叶斯 | 您所在的位置:网站首页 › 朴素贝叶斯算法的原理分析 › 朴素贝叶斯 |
朴素贝叶斯
|
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、什么是贝叶斯?二、西瓜数据集实例1.西瓜数据集2.数据处理——计算先验概率1、什么是先验概率2、如何计算 3.数据处理——计算条件概率1、什么是条件概率2、如何计算 4.贝叶斯分类器实现1、什么是后验概率2、如何计算 5.样本预测分类 总结 前言提示:这里可以添加本文要记录的大概内容: 朴素贝叶斯分类是一种基于贝叶斯定理和特征条件独立假设的监督学习分类算。它广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。本文将通过一个简单的西瓜数据集为例,介绍朴素贝叶斯分类算法的基本原理和实现过程。 提示:以下是本篇文章正文内容,下面案例可供参考 一、什么是贝叶斯?英国数学家贝叶斯提出了贝叶斯公式用来描述两个条件概率之间的关系,抛出公式如下: 公式指出了在事件B发生的情况下事件A发生的概率,通过贝叶斯公式转换可以利用右边的P(A)和P(B|A)以及P(B)反推出我们的结果P(A|B),而P(B|A)和P(A)以及P(B)则可以通过我们已知的数据集进行统计计算得到,于是P(A|B)的结果得到。 二、西瓜数据集实例 1.西瓜数据集我们使用的数据集是一个简单的西瓜数据集,包含了西瓜的各种特征信息和对应的分类标签(好瓜/坏瓜)。数据集中的特征包括色泽、根蒂、敲声、纹理、脐部、触感等,标签为好瓜或坏瓜。 代码如下(示例): #西瓜数据集 def DataSet(): data = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460], ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376], ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264], ['青绿', '蜷缩', '沉闷', '模糊', '凹陷', '硬滑', 0.608, 0.318], ['浅白', '蜷缩', '浊响', '模糊', '凹陷', '硬滑', 0.556, 0.215], ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.481, 0.149], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.437, 0.211], ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091], ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.243, 0.267], ['浅白', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.247, 0.057], ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.345, 0.099], ['浅白', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.635, 0.161], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.650, 0.198], ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.361, 0.370], ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.593, 0.041], ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.100]] labels = ['好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜'] return data, labels 2.数据处理——计算先验概率 1、什么是先验概率在贝叶斯统计学中,先验概率是在考虑任何数据(观测值)之前,我们对事件概率的主观信念或经验性估计。它是基于以往的知识和经验对事件概率的预设,通常用P(θ)表示,其中θ表示事件。在朴素贝叶斯分类中,先验概率指的是在没有其他信息的情况下,对每个类别出现的概率的估计。
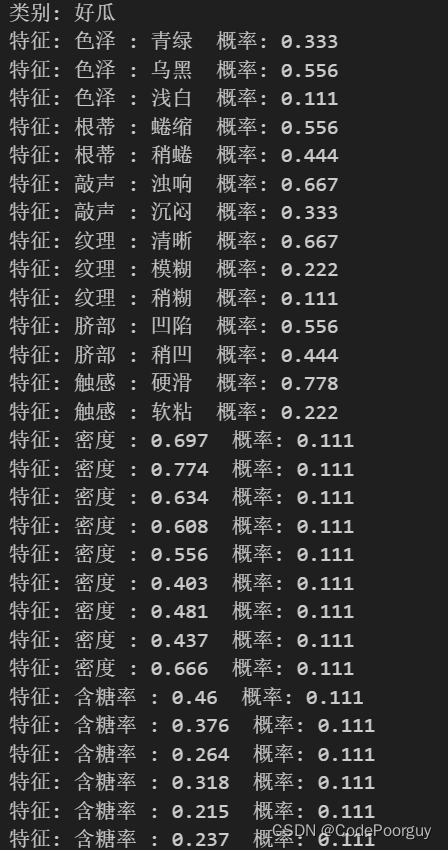
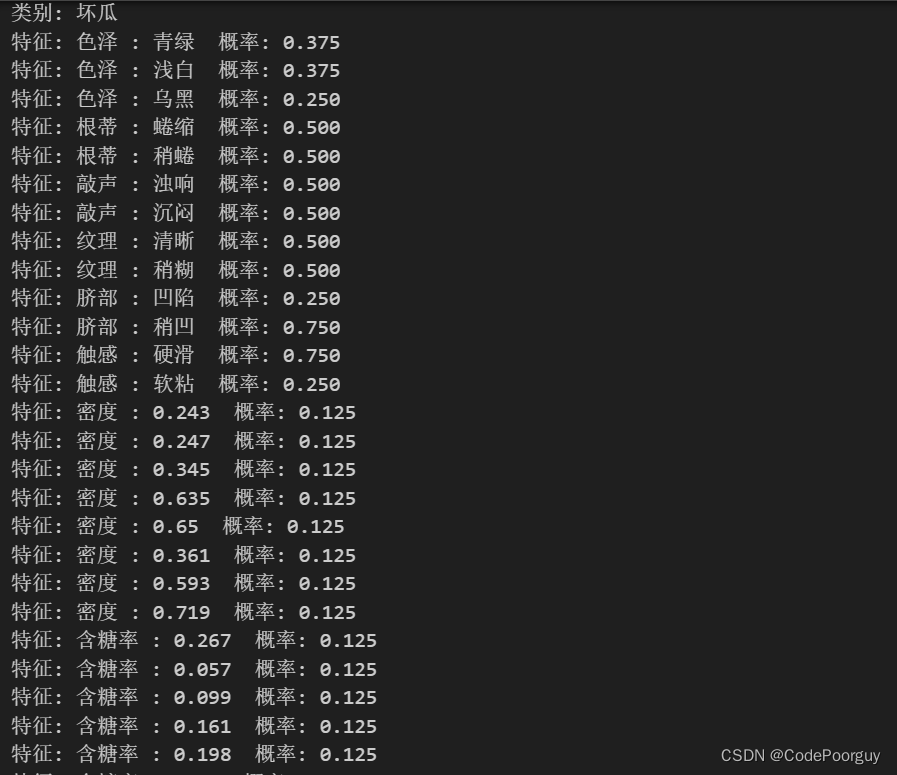
计算先验概率的方法很简单,通常可以通过以下步骤进行: 统计训练集中每个类别出现的次数,得到每个类别的频次。 根据频次计算每个类别的先验概率,即该类别在训练集中出现的概率。 先验概率计算公式:P(类别) = 类别出现次数 / 训练样本总数 代码如下(示例): # 统计类别标签的频次 # 统计类别标签的频次 label_freq = {} for label in labels: # 如果标签已经存在于label_freq中,增加其频次 if label in label_freq: label_freq[label] += 1 # 否则,创建一个新的键值对 else: label_freq[label] = 1 # 计算先验概率 prior_prob = {} total_samples = len(labels) for label, freq in label_freq.items(): # 计算每个类别的先验概率 prior_prob[label] = freq / total_samples # 输出先验概率 for label, prob in prior_prob.items(): print("先验概率: 类别 {} - 概率 {:.4f}".format(label, prob))结果如下: 条件概率是指在已知某一事件发生的条件下,另一事件发生的概率。一用P(A|B)表示,在事件B发生的条件下事件A发生的概率。在朴素贝叶斯分类中,条件概率的是在给定类别的情况下,特征出现的概率。 公式: 计算条件概率的方法是在已知类别的条件下,统计样本中每个特征值出现的频次,并将频次除以总样本数得到概率。朴素贝叶斯分类器中,个特征的条件率是相互独立的,因此可以将每个特征单独看待,计算各特征值在每个类别下的概率 代码如下 # 获取数据集 feature, data, labels = DataSet() # 根据类别分割数据集 data_by_label = {} # 遍历data中的每个数据项 for i in range(len(data)): # 获取当前数据项的标签 label = labels[i] # 如果当前标签已经存在于data_by_label中 if label in data_by_label: # 将当前数据项添加到对应标签的列表中 data_by_label[label].append(data[i]) else: # 如果当前标签不存在于data_by_label中 # 则创建一个以当前标签为键,数据项为值的新列表 data_by_label[label] = [data[i]] # 计算条件概率 conditional_prob = {} for label in data_by_label: conditional_prob[label] = {} # 初始化条件概率字典 samples = data_by_label[label] # 获取该类别的样本 total_samples = len(samples) # 该类别的样本数量 # 计算每个特征的条件概率 # 遍历每个特征 for feature_index in range(len(samples[0])): # 获取每个样本该特征的值 feature_values = [sample[feature_index] for sample in samples] # 统计每个特征值的出现频率 feature_freq = {} for value in feature_values: # 如果特征值已经在字典中,频率加1 if value in feature_freq: feature_freq[value] += 1 else: # 否则,添加特征值到字典中,频率为1 feature_freq[value] = 1 # 计算条件概率 for value, freq in feature_freq.items(): conditional_prob[label][(feature_index, value)] = round(freq / total_samples, 3) # 保留3位小数 # 输出条件概率 for label, prob_dict in conditional_prob.items(): print("类别:", label) for feature_value, prob in prob_dict.items(): print("特征: {} : {} 概率: {:.3f}".format(feature[feature_value[0]], feature_value[1], prob))结果如下: 后验概率是指在观察到某些先验条件或证据后,根据贝叶斯定理计算得到的某个事件发生的概率。在统计学和机器学习中,后验概率指的是在给定特征信息的条件下,某个类别或假设成立的概率。计算后验概率是通过先验概率和似然度来得到的。 2、如何计算
代码如下: # 贝叶斯分类器 def classify(sample, prior_prob, conditional_prob, alpha=1): max_prob = -1 best_label = None post_prob = {} for label, prior in prior_prob.items(): # 初始化概率变量prob prob = prior # 遍历样本中的每一个特征 for feature_index, feature_value in enumerate(sample): # 如果条件概率不为空 if (feature_index, feature_value) in conditional_prob[label]: # 乘以条件概率 prob *= conditional_prob[label][(feature_index, feature_value)] else: # 拉普拉斯修正 prob *= alpha / (sum(conditional_prob[label].values()) + alpha) post_prob[label] = prob # 存储后验概率 if prob > max_prob: max_prob = prob best_label = label # 输出后验概率 for label, prob in post_prob.items(): print("类别: {}, 后验概率: {:.6f}".format(label, prob)) return best_label 5.样本预测分类 # 测试样本 test_sample = ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460] # 进行分类 predicted_label = classify(test_sample, prior_prob, conditional_prob) print("测试样本为:",test_sample) print("预测的类别为:", predicted_label)结果如下:
贝叶斯实验是基于贝叶斯定理的一种统计实验方法,用于更新我们对事件概率的估计。通过实验结果,我们可以根据先验概率和样本数据来计算后验概率,从而对事件的发生概率进行更新和调整。 以下是对贝叶斯实验的总结: 先验概率:在进行实验之前,我们对事件的发生概率有一个先验的估计。这个估计可以基于已有的知识、经验或者主观判断。先验概率可以影响最终的后验概率结果。 似然函数:在贝叶斯实验中,似然函数表示观察到一组数据的概率。它反映了事件在给定实验数据下发生的可能性。似然函数的选择通常依赖于具体的问题和实验设计。 后验概率:通过应用贝叶斯定理,我们可以根据先验概率和观察到的实验数据来计算后验概率。后验概率是在考虑了实验数据的基础上更新后的概率,它反映了实验结果对事件概率的影响。 贝叶斯定理:贝叶斯定理是贝叶斯实验的核心理论基础。它描述了如何根据先验概率和观察到的数据来计算后验概率。贝叶斯定理可以帮助我们在证据和先验知识之间进行合理的权衡,并进行概率更新。 |
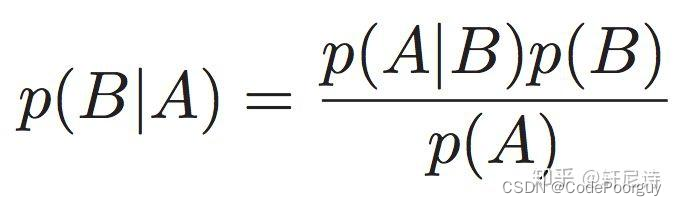



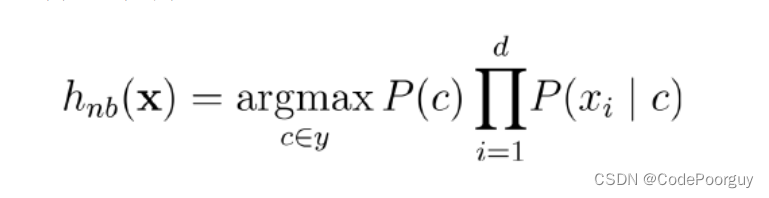 也就是上面这个式子,就把之前计算到的数据都代入进去,即可
也就是上面这个式子,就把之前计算到的数据都代入进去,即可 因此可以得到预测结果。
因此可以得到预测结果。【本文地址】