| 3. 朴素贝叶斯原理以及代码实现 | 您所在的位置:网站首页 › 朴素贝叶斯算法的原理 › 3. 朴素贝叶斯原理以及代码实现 |
3. 朴素贝叶斯原理以及代码实现
|
相关的实验代码在我的github上👉QYHcrossover/ML-numpy: 机器学习算法numpy实现 (github.com) 欢迎star⭐ 朴素贝叶斯分类器原理朴素贝叶斯分类器(Naive Bayes Classifier)是一种基于贝叶斯定理和特征条件独立假设的分类方法。它通过先验概率和条件概率来预测样本的类别。 假设有一个样本x,它有n个特征属性 x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn ,那么朴素贝叶斯分类器预测它属于第k个类别的概率可以表示为:
其中 P ( X = x ∣ Y = k ) P(X=x|Y=k) P(X=x∣Y=k) 表示在已知该样本属于第k个类别的情况下,样本具有该特征属性的概率; P ( Y = k ) P(Y=k) P(Y=k) 表示样本属于第k个类别的先验概率; P ( X = x ) P(X=x) P(X=x) 表示样本具有该特征属性的概率。 朴素贝叶斯分类器中,特征属性之间假设为条件独立,也就是说对于任意两个特征属性 x i x_i xi 和 x j x_j xj ,它们之间没有任何关联,这样可以简化计算。 特征属性的条件概率 P ( X = x ∣ Y = k ) P(X=x|Y=k) P(X=x∣Y=k) 可以通过概率密度函数来计算,朴素贝叶斯分类器通常采用高斯分布来进行建模。 iris数据集为例代码实现下面是朴素贝叶斯分类器的代码实现,我们来逐步解释代码中的逻辑。 import numpy as np class Bayes: @staticmethod def mean(X): return np.mean(X,axis=0) @staticmethod def variance(X): return np.mean((X-Bayes.mean(X))**2,axis=0)这段代码定义了一个 Bayes 类,并在其中定义了两个静态方法 mean() 和 variance(),用于计算样本的均值和方差。其中 mean() 方法使用 numpy 库的 mean() 函数计算样本的均值,variance() 方法则根据公式计算样本的方差。 def gaussian(self,x,avg,var): return (1./np.sqrt(2*np.pi*var)) * np.exp(-0.5*((x-avg)**2)/var)这个方法用于计算高斯分布的概率密度函数。其中 x 是样本的特征属性,avg 和 var 是对应特征属性的均值和方差。 fit函数用于训练朴素贝叶斯分类器,输入参数X和y分别代表特征和标签。其中,c代表标签y的类别数,Xs是一个列表,包含了每个类别对应的特征。在fit函数中,该分类器通过计算各个类别的均值、方差和所占比率,对训练数据进行拟合,从而得到相应的参数。这些参数将被用于predict函数中的预测。 def fit(self,X,y): c = len(set(y)) self.c = c Xs = [X[y==i] for i in range(c)] #各个类别的均值、方差、所占比率 self.avgs = [Bayes.mean(X) for X in Xs] self.vars = [Bayes.variance(X) for X in Xs] self.percs = [len(y[y==i])/len(y) for i in range(c)]predict函数用于进行预测。当传入一个样本时,函数先判断输入的数据是否为一个样本(即判断特征数据的维度是否为1),如果是,那么将使用单个样本的预测方法来预测该样本所属的类别;如果不是,那么将使用批量预测的方法来预测所有样本所属的类别。具体预测方法为:对于每个类别,计算该样本在该类别下的概率,并乘以该类别所占比率,最后选择概率最大的类别作为预测结果。 def predict(self,x): if len(x.shape) == 1: result = np.array(self.percs) for i in range(self.c): gaus = self.gaussian(x,self.avgs[i],self.vars[i]) for j in range(len(x)): result[i] *= gaus[j] return np.argmax(result) results = np.array([self.predict(x[i]) for i in range(len(x))]) return resultsscore函数用于对朴素贝叶斯分类器的预测结果进行评分。它接受测试集X和相应的标签y作为输入,然后使用predict函数来对测试集进行预测,最后计算预测结果与实际标签y之间的准确率。其中,准确率的计算方式为正确预测的样本数除以测试集总样本数。 def score(self,X,y): y_pred = self.predict(X) return np.sum(y_pred==y)/len(y)主函数方面首先导入了iris数据集并进行了切分,然后创建了一个自己实现的贝叶斯分类器bayes,并用训练数据对其进行训练。之后调用bayes的score函数,用测试数据进行预测并计算预测准确率。接着调用sklearn中的GaussianNB分类器,并同样用测试数据进行预测和准确率计算。 if __name__=="__main__": from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split iris = load_iris() X,y = iris["data"],iris["target"] X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=22) # print(len(X_train)) # print(len(X_test)) bayes = Bayes() bayes.fit(X_train,y_train) # print(bayes.avgs) # print(bayes.vars) print(bayes.score(X_test,y_test)) from sklearn.naive_bayes import GaussianNB clf = GaussianNB() clf.fit(X_train, y_train) print(clf.score(X_test,y_test)) 总结本篇博客主要介绍了朴素贝叶斯算法的原理及实现。朴素贝叶斯是一种常用的分类算法,它的原理是基于贝叶斯定理和条件独立假设。通过学习样本数据中的特征和对应的类别信息,建立概率模型,然后利用贝叶斯定理计算出给定特征的情况下,每个类别的概率,并选择概率最大的类别作为分类结果。 在代码实现中,定义了一个Bayes类,包括了均值、方差、高斯概率密度函数、拟合、预测和评估等方法。其中,拟合方法用于训练模型,预测方法用于根据输入的特征预测类别,评估方法用于评估模型的性能。 通过实验结果比较可以看出,自己实现的朴素贝叶斯算法与Scikit-learn中的GaussianNB算法在鸢尾花数据集上的分类准确率相近。因此,朴素贝叶斯算法在分类问题上具有较高的效率和准确性,适用于大规模的数据分类问题。 果比较可以看出,自己实现的朴素贝叶斯算法与Scikit-learn中的GaussianNB算法在鸢尾花数据集上的分类准确率相近。因此,朴素贝叶斯算法在分类问题上具有较高的效率和准确性,适用于大规模的数据分类问题。 相关的实验代码在我的github上👉QYHcrossover/ML-numpy: 机器学习算法numpy实现 (github.com) 欢迎star⭐ |
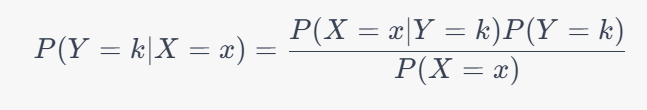
【本文地址】