|
下文使用代码: 链接:pan.baidu.com/s/1sR2bt_Iu89M3h_8XMPjEuQ 提取ey3q
分类算法朴素贝叶斯、决策树、SVM、人工神经网络+汽车分类实战
一、 实验目的二、 实验的硬件、软件平台三、 实验算法原理(一) 朴素贝叶斯算法(二) 决策树算法(三) 支持向量机(四) 人工神经网络
四、 数据分析与预处理1. 了解文本数据集的情况并阅读算法代码说明文档;2. 读取并处理数据,将上面的字符串数据转换为整型数字来简化操作3. 分类算法的总体流程
五、 算法系统设计1. 朴素贝叶斯算法实现2. 决策树(ID3算法)3. 支持向量机(SVM)4. 人工神经网络
六、 相关思考1. 朴素贝叶斯算法2. 决策树算法3. 支持向量机算法4. 人工神经网络
一、 实验目的
巩固4种基本的分类算法的算法思想:朴素贝叶斯算法,决策树算法,人工神经网络,支持向量机;能够使用现有的分类器算法代码进行分类操作学习如何调节算法的参数以提高分类性能;
二、 实验的硬件、软件平台
硬件:计算机软件:操作系统:WINDOWS应用软件:python
三、 实验算法原理
(一) 朴素贝叶斯算法
简介 朴素贝叶斯分类器是贝叶斯分类器中最简单,也是最常见的一种分类方法。朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。并且,朴素贝叶斯算法仍然是流行的十大挖掘算法之一,该算法是有监督的学习算法,解决的是分类问题基础 朴素贝叶斯分类算法是基于贝叶斯定理与特征条件独立假设的分类方法,因此想要了解朴素贝叶斯分类算法背后的算法原理,就不得不用到概率论的一些知识。 2.1. 先验概率:是指根据以往经验和分析得到的概率。 2.2. 后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小。 2.3. 全概率公式: 若事件B1,B2,…,Bn两两互不相容,并且其概率和为1。那么对于任意一个事件C都满足 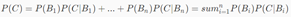
2.4. 贝叶斯公式: 已知事件已经发生了,但想要计算引发该事件的各种原因的概率时,需要用到贝叶斯公式,贝叶斯公式定义如下,其中A表示已经发生的事件,Bi为导致事件A发生的第i个原因: 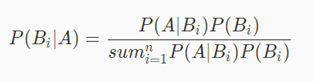
如果我们对贝叶斯公式进行一个简单的数学变换(两边同时乘以分母,再两边同时除以P(Bi))。就能够得到如下公式: 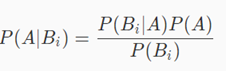 (朴素贝叶斯分类算法的核心数学公式) 3. 朴素贝叶斯正式定义: 朴素贝叶斯分类的正式定义如下: (朴素贝叶斯分类算法的核心数学公式) 3. 朴素贝叶斯正式定义: 朴素贝叶斯分类的正式定义如下:  (计算出上面的结果值,拥有最大概率的值的yk就是他的分类,这个很好理解,在X条件下,那个分类类型概率高就属于哪个分类。) (计算出上面的结果值,拥有最大概率的值的yk就是他的分类,这个很好理解,在X条件下,那个分类类型概率高就属于哪个分类。)
(二) 决策树算法
简介 决策树,就是一个类似于流程图的树形结构,树内部的每一个节点代表的是对一个特征的测试,树的分支代表该特征的每一个测试结果,而树的每一个叶子节点代表一个类别。树的最高层是就是根节点。概念 2.1. 一棵决策树的生成过程主要分为以下3个部分:
特征选择:特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。 2.2. 特征挑选方法(ID3算法是信息增益法) 选择具有最高信息增益的特征作为测试特征,利用该特征对节点样本进行划分子集,会使得各子集中不同类别样本的混合程度最低,在各子集中对样本划分所需的信息(熵)最少;  2.3. 决策树剪枝 产生的决策树可能存在过拟合的现象。树枝修剪就是通过统计学的方法删除不可靠的分支,使得整个决策树的分类速度和分类精度得到提高。 (1)预剪枝:边建立决策树边进行剪枝的操作(更实用) (2)后剪枝:当建立完决策树后来进行剪枝操作
常用算法(这里只介绍ID3) ID3算法是最早提出的一种决策树算法,ID3算法的核心是在决策树各个节点上应用信息增益准则来选择特征,递归的构建决策树。
(三) 支持向量机
简介 支持向量机(SVM)是按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM可以通过核方法进行非线性分类,是常见的核学习方法之一。原理概念 2.3. 决策树剪枝 产生的决策树可能存在过拟合的现象。树枝修剪就是通过统计学的方法删除不可靠的分支,使得整个决策树的分类速度和分类精度得到提高。 (1)预剪枝:边建立决策树边进行剪枝的操作(更实用) (2)后剪枝:当建立完决策树后来进行剪枝操作
常用算法(这里只介绍ID3) ID3算法是最早提出的一种决策树算法,ID3算法的核心是在决策树各个节点上应用信息增益准则来选择特征,递归的构建决策树。
(三) 支持向量机
简介 支持向量机(SVM)是按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM可以通过核方法进行非线性分类,是常见的核学习方法之一。原理概念 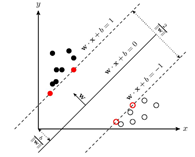 2.1. 线性可分性(linear separability) 在分类问题中给定输入数据和学习目标: 2.1. 线性可分性(linear separability) 在分类问题中给定输入数据和学习目标: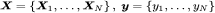 ,其中输入数据的每个样本都包含多个特征并由此构成特征空间: ,其中输入数据的每个样本都包含多个特征并由此构成特征空间:  ,而学习目标为二元变量 表示两种类别。 ,而学习目标为二元变量 表示两种类别。  若输入数据所在的特征空间存在作为决策边界的超平面将学习目标按正类和负类分开,则称该分类问题具有线性可分性,参数w,b分别为超平面的法向量和截距。 位于间隔边界上的正类和负类样本为支持向量,支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关。 满足该条件的决策边界实际上构造了2个平行的超平面作为间隔边界以判别样本的分类。线性可分问题我们进行参数学习以得到间隔最大的超平面即可。 2.2. 损失函数 在一个分类问题不具有线性可分性时,使用超平面作为决策边界会带来分类损失,即部分支持向量不再位于间隔边界上,而是进入了间隔边界内部,或落入决策边界的错误一侧。损失函数可以对分类损失进行量化, 2.3. 核方法 若输入数据所在的特征空间存在作为决策边界的超平面将学习目标按正类和负类分开,则称该分类问题具有线性可分性,参数w,b分别为超平面的法向量和截距。 位于间隔边界上的正类和负类样本为支持向量,支持向量机的一个重要性质:训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关。 满足该条件的决策边界实际上构造了2个平行的超平面作为间隔边界以判别样本的分类。线性可分问题我们进行参数学习以得到间隔最大的超平面即可。 2.2. 损失函数 在一个分类问题不具有线性可分性时,使用超平面作为决策边界会带来分类损失,即部分支持向量不再位于间隔边界上,而是进入了间隔边界内部,或落入决策边界的错误一侧。损失函数可以对分类损失进行量化, 2.3. 核方法  (四) 人工神经网络
简介 人工神经网络,是一种模仿生物神经网络结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。神经网络包含多个层次,相邻层之间的神经元相互联接构成网络,即”神经网络”。数据信息顺着网络正向传播,误差信息逆着网络方向反向传播。原理 2.1. 基本结构
(四) 人工神经网络
简介 人工神经网络,是一种模仿生物神经网络结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。神经网络包含多个层次,相邻层之间的神经元相互联接构成网络,即”神经网络”。数据信息顺着网络正向传播,误差信息逆着网络方向反向传播。原理 2.1. 基本结构 
神经元模型基本上包括多个输入(类似突触),这些输入分别被不同的权值相乘(收到的信号强度不同),然后被一个数学函数用来计算决定是否激发神经元。还有一个函数计算人工神经元的输出。人工神经网络把这些人工神经元融合一起用于处理信息。 权值越大表示输入的信号对神经元影响越大。权值可以为负值,意味着输入信号收到了抑制。通过调整权值可以得到固定输入下需要的输出值。 人工神经网络由3个要素组成:拓扑结构、连接方式和学习规则。人工神经网络包含三种层类型: 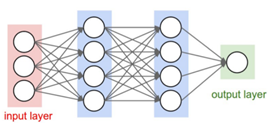 • 输入层:输入层神经元可以接受多种类型的数据输入(文字、声音和图像等)。 • 输出层:输出层输出分类或其他决策信息。 • 隐藏层:输入层和输出层之间包含多个隐藏层。 2.2. 算法步骤 人工神经网络分类算法的核心步骤如下: • 输入层:输入层神经元可以接受多种类型的数据输入(文字、声音和图像等)。 • 输出层:输出层输出分类或其他决策信息。 • 隐藏层:输入层和输出层之间包含多个隐藏层。 2.2. 算法步骤 人工神经网络分类算法的核心步骤如下:
数据清洗:数据规范化, 了解数据的基本特征;构建神经网络的拓扑结构确定神经网络的连接方式通过训练样本的校正,得到神经网络的权值矩阵值 神经元权重的学习修正过程: • 在神经网络中随机初始化权重 • 我们将第一组输入值发送给神经网络,使其传播通过网络并得到输出值。 • 我们将输出值和期望的输出值进行比较,并使用成本函数计算误差。 • 我们将误差传播回网络,并根据这些信息设置权重(反向传播)。 • 对于训练集中的每个输入值,重复2至4的步骤。 • 当整个训练集都发送给了神经网络,我们就完成了一个epoch, 之后重复多次epochs。 2.3. 反向传播训练算法 反向传播算法本质上是梯度下降法。人工神经网络的参数多,梯度计算比较复杂。 训练集中的样本形如: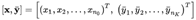 输入包含n0个值,目标值包含nk个值,分别对应神经网络的输入/输出维度。训练这样进行:将神经网络对样本输入X计算输出Y,然后计算样本目标值与输出的平方和误差: 输入包含n0个值,目标值包含nk个值,分别对应神经网络的输入/输出维度。训练这样进行:将神经网络对样本输入X计算输出Y,然后计算样本目标值与输出的平方和误差: 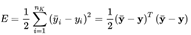 视输入X为固定值,把 E 当作全体权值 的函数。求 E 的梯度 ,然后用下式更新全体权值: 视输入X为固定值,把 E 当作全体权值 的函数。求 E 的梯度 ,然后用下式更新全体权值: 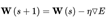 该式子就是梯度下降法的更新式。梯度矩阵由 E 对每一个权重 的偏导数 构成。式子 等价于对每一个权重进行更新: 该式子就是梯度下降法的更新式。梯度矩阵由 E 对每一个权重 的偏导数 构成。式子 等价于对每一个权重进行更新: 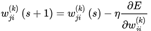 对每一个提交给神经网络的样本用上式对全体权值进行一次更新,直到所有样本的误差值都小于一个预设的阈值,此时训练完成。
四、 数据分析与预处理
1. 了解文本数据集的情况并阅读算法代码说明文档; 对每一个提交给神经网络的样本用上式对全体权值进行一次更新,直到所有样本的误差值都小于一个预设的阈值,此时训练完成。
四、 数据分析与预处理
1. 了解文本数据集的情况并阅读算法代码说明文档;
我们需要做一个汽车分类的分类器。 文本数据共有三个文件:  通过分析可以发现其中dataset含有所有的数据,而test和predict分别为dataset划分的训练集与测试集; 其中dataset共有1728条数据,而训练集test含有前1350条、测试集predict含有后378条; 接下来的过程里通过测试集test中的数据对分类算法的参数进行学习,通过测试机predict中的数据进行测试分类器的准确率。 而数据集中每一条数据格式如下: 通过分析可以发现其中dataset含有所有的数据,而test和predict分别为dataset划分的训练集与测试集; 其中dataset共有1728条数据,而训练集test含有前1350条、测试集predict含有后378条; 接下来的过程里通过测试集test中的数据对分类算法的参数进行学习,通过测试机predict中的数据进行测试分类器的准确率。 而数据集中每一条数据格式如下: 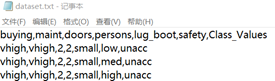 汽车的状态类型和特征类型如下描述。 车辆的状态分为四类: 汽车的状态类型和特征类型如下描述。 车辆的状态分为四类:
unacc (Unacceptable 状况很差) acc (Acceptable 状况一般) good (Good 状况好) vgood (Very good 状况非常好)
那我们又是通过什么来判断这辆车的状态好坏呢?
buying (购买价: vhigh, high, med, low) maint (维护价: vhigh, high, med, low) doors (几个门: 2, 3, 4, 5more) persons (载人量: 2, 4, more) lug_boot (贮存空间: small, med, big) safety (安全性: low, med, high)
如果展示出这些数据, 我们就能清楚的看到这些数据的表示形式了,如dataset.txt中的前几行数据为:  那么这样的话对数据的读取就变得简单了。 那么这样的话对数据的读取就变得简单了。
2. 读取并处理数据,将上面的字符串数据转换为整型数字来简化操作
2.1. 读取数据  使用了非常简单的read_csv读取列表数据的方法,此时读取出来的数据打印如下: 使用了非常简单的read_csv读取列表数据的方法,此时读取出来的数据打印如下: 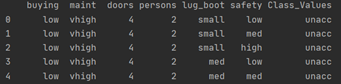 2.2. 处理数据(转换为数字形式) 2.2. 处理数据(转换为数字形式) 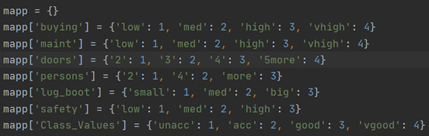 如图,用mapp字典的方式,将特征属性的值对应为数字,如buying这个属性的四个取值’low’、’med’、’high’、’vhigh’分别与1、2、3、4相对应; 如图,用mapp字典的方式,将特征属性的值对应为数字,如buying这个属性的四个取值’low’、’med’、’high’、’vhigh’分别与1、2、3、4相对应;   接下来如上图所示,使用一个循环将我们读入的训练集和测试集的值更改为它们对应的数字; 接下来如上图所示,使用一个循环将我们读入的训练集和测试集的值更改为它们对应的数字;  最后将数据输出到.csv文件中,保存备用; 最后将数据输出到.csv文件中,保存备用;
3. 分类算法的总体流程
算法思路: 第一阶段——准备工作阶段,主要工作是依据详细情况确定特征属性,并对每一个特征属性进行适当划分,然后由人工对一部分待分类项进行分类。形成训练样本集合。这一阶段的输入是全部待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一须要人工完毕的阶段,其质量对整个过程将有重要影响。分类器的质量非常大程度上由特征属性、特征属性划分及训练样本质量决定。 第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器。主要工作是计算每一个类别在训练样本中的出现频率及每一个特征属性划分对每一个类别的条件概率预计,并将结果记录。其输入是特征属性和训练样本。输出是分类器。 这一阶段是机械性阶段,依据前面讨论的公式能够由程序自己主动计算完毕。 第三阶段——预测阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完毕。 (上述三个阶段也是所有机器学习算法的一个大致过程)
五、 算法系统设计
1. 朴素贝叶斯算法实现
1.1. 数据读取与划分 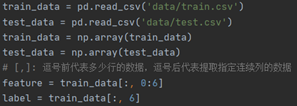 将数字数据从上面的csv文件中读取出来,保存在数组中,同时将数据的特征集与标签划分分为两个数组; 1.2. 模型参数定义 将数字数据从上面的csv文件中读取出来,保存在数组中,同时将数据的特征集与标签划分分为两个数组; 1.2. 模型参数定义 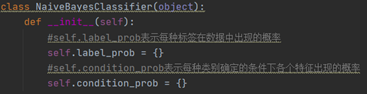 朴素贝叶斯分类算法主要是每种标签出现的概率P(Ai)、以及在Ai标签确定值情况下的所有特征B的各个取值b的概率P(Bi=b|Ai=a),分别保存在label_prob、condition_prob字典当中; 只要我们在训练的过程中确定了这两个字典的取值,那么对于要预测的变量就可以通过公式 朴素贝叶斯分类算法主要是每种标签出现的概率P(Ai)、以及在Ai标签确定值情况下的所有特征B的各个取值b的概率P(Bi=b|Ai=a),分别保存在label_prob、condition_prob字典当中; 只要我们在训练的过程中确定了这两个字典的取值,那么对于要预测的变量就可以通过公式 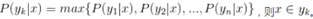 来确定标签; 1.3. 模型训练 来确定标签; 1.3. 模型训练  首先是直接计算它的label_prob来得到每个标签出现的概率;直接通过累加某标签出现的次数来计算出现的概率,其中加入拉普拉斯平滑来进行处理,防止出现零概率。 首先是直接计算它的label_prob来得到每个标签出现的概率;直接通过累加某标签出现的次数来计算出现的概率,其中加入拉普拉斯平滑来进行处理,防止出现零概率。  接着这一部分的前一个双重循环累加得到了每个特征Bi的各个取值b在后面确定的标签Ai=a的情况下出现的次数;后面的for循环就是进行整个P(Bi=b|Ai=a)的概率的计算过程; 其中因为是字典来记录每个值,因此在直接进行遍历累加之前需要先进行构建condition_prob中的值(如下图中的Key键值);首先构建标签(也就是[key])的键值,初始为空字典。接下来遍历每一个特征向量Bi,对key键值情况下的某个特征[key][i]进行初始化,依然初始为空字典,最后就是遍历该特征Bi的所有取值k,对[key][i][k]进行初始化为1,这里不初始化为0的原因是我们需要进行拉普拉斯平滑,在这里初始为1之后后面就不用再加1了,至此condition_prob就构建完成了,condition_prob[key][i][k]的含义就是在标签A=key的时候特征Bi=k的数目; 接着这一部分的前一个双重循环累加得到了每个特征Bi的各个取值b在后面确定的标签Ai=a的情况下出现的次数;后面的for循环就是进行整个P(Bi=b|Ai=a)的概率的计算过程; 其中因为是字典来记录每个值,因此在直接进行遍历累加之前需要先进行构建condition_prob中的值(如下图中的Key键值);首先构建标签(也就是[key])的键值,初始为空字典。接下来遍历每一个特征向量Bi,对key键值情况下的某个特征[key][i]进行初始化,依然初始为空字典,最后就是遍历该特征Bi的所有取值k,对[key][i][k]进行初始化为1,这里不初始化为0的原因是我们需要进行拉普拉斯平滑,在这里初始为1之后后面就不用再加1了,至此condition_prob就构建完成了,condition_prob[key][i][k]的含义就是在标签A=key的时候特征Bi=k的数目; 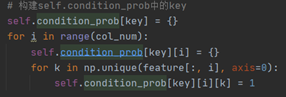 最后用这个累加完成的数目除于分母就可以得到所有P(Bi=k | A=key)的值了; 1.4. 数据预测 最后用这个累加完成的数目除于分母就可以得到所有P(Bi=k | A=key)的值了; 1.4. 数据预测 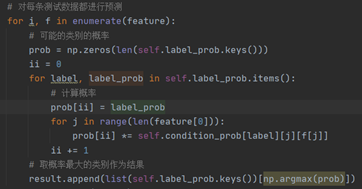 数据预测很简单,对于每一条数据我们都根据以下公式进行计算,然后选出使得结果最大的标签作为我们的结果: 数据预测很简单,对于每一条数据我们都根据以下公式进行计算,然后选出使得结果最大的标签作为我们的结果: 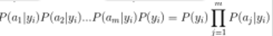 这里的话就是将存储在condition_prob中的数据即P(Bi=k | A=key)根据需要(即我们要预测的数据的特征向量取值)进行该公式的计算,保存每一个标签的计算结果,最后进行大小的比较即可。 1.5. 结果 这里的话就是将存储在condition_prob中的数据即P(Bi=k | A=key)根据需要(即我们要预测的数据的特征向量取值)进行该公式的计算,保存每一个标签的计算结果,最后进行大小的比较即可。 1.5. 结果   可以看到其运行结果是train训练集训练后的得到了第一行4个标签出现的P,以及第二行对应的P(Bi=k | A=key)和正确率; 第一行的四个标签的概率很明显,第二行因为太长没有显示完,其中第一个就是代表标签为1时的0号特征取值为1时的P=0.03983,取值为2时是0.269等等。 第三行的正确率为0.6816,可以看出朴素贝叶斯效果其实并不算太好; 1.6. 时间/空间复杂度分析 根据代码的实现可以简单的进行分析,假设样本数据规模是N,而特征数目为m,那么其实无论是condition_prob还是label_prob,我们通过遍历一次样本以及样本的每个特征就可以计算出来了(这只是一个简单的计算贝叶斯公式得过程),因此训练的过程时间复杂度是O(mN)的,而空间复杂度更低,因为我们只需要存储P(Ai)以及P(Bi=b|Ai=a)的所忧取值即可,如果设所有特征的平均取值为a,标签的取值为b,那么空间复杂度为O(abm); 1.7. 性能说明 朴素贝叶斯的时空复杂度都很低,对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练。 但也因此有很多缺点,朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。 可以看到其运行结果是train训练集训练后的得到了第一行4个标签出现的P,以及第二行对应的P(Bi=k | A=key)和正确率; 第一行的四个标签的概率很明显,第二行因为太长没有显示完,其中第一个就是代表标签为1时的0号特征取值为1时的P=0.03983,取值为2时是0.269等等。 第三行的正确率为0.6816,可以看出朴素贝叶斯效果其实并不算太好; 1.6. 时间/空间复杂度分析 根据代码的实现可以简单的进行分析,假设样本数据规模是N,而特征数目为m,那么其实无论是condition_prob还是label_prob,我们通过遍历一次样本以及样本的每个特征就可以计算出来了(这只是一个简单的计算贝叶斯公式得过程),因此训练的过程时间复杂度是O(mN)的,而空间复杂度更低,因为我们只需要存储P(Ai)以及P(Bi=b|Ai=a)的所忧取值即可,如果设所有特征的平均取值为a,标签的取值为b,那么空间复杂度为O(abm); 1.7. 性能说明 朴素贝叶斯的时空复杂度都很低,对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练。 但也因此有很多缺点,朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
2. 决策树(ID3算法)
注:后面两个算法的数据划分与上面朴素贝叶斯的方法相同,不再赘述。 2.1. 数据读取  将测试集的标签与特征划分,而train_data无需划分(在建树的过程中方便一些) 2.2. 计算香农熵并选择信息增益最大的特征 ①计算训练数据集中的标签Y随机变量的香农熵 将测试集的标签与特征划分,而train_data无需划分(在建树的过程中方便一些) 2.2. 计算香农熵并选择信息增益最大的特征 ①计算训练数据集中的标签Y随机变量的香农熵  根据香农熵的公式H§ -sum (pi * log2(pi)),我们首先需要计算Pi,即这里直接先计算出各个标签出现的次数(一个循环实现),接着直接边进行香农熵公式的计算边计算各个取值的P,最后返回它的香农熵; ②计算x_i给定的条件下,Y的条件熵 根据香农熵的公式H§ -sum (pi * log2(pi)),我们首先需要计算Pi,即这里直接先计算出各个标签出现的次数(一个循环实现),接着直接边进行香农熵公式的计算边计算各个取值的P,最后返回它的香农熵; ②计算x_i给定的条件下,Y的条件熵 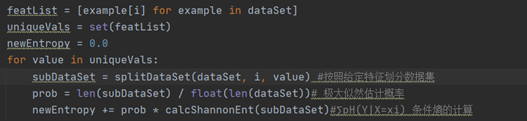 这一部分较为简单,首先按照给定的特征进行数据集的划分,只留下特征i = value的所有数据,接着进行极大似然估计得到p后根据∑pH(Y|X=xi) 条件熵的计算公式计算条件熵。 ③计算信息增益,选择最好的数据集划分 这一部分较为简单,首先按照给定的特征进行数据集的划分,只留下特征i = value的所有数据,接着进行极大似然估计得到p后根据∑pH(Y|X=xi) 条件熵的计算公式计算条件熵。 ③计算信息增益,选择最好的数据集划分  此部分最简单,就是选择一个最大的信息增益进行返回即可。 2.3. 递归建树 ①递归边界 此部分最简单,就是选择一个最大的信息增益进行返回即可。 2.3. 递归建树 ①递归边界 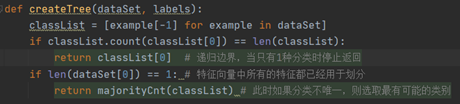 两种情况,一种是当只剩下一种分类时,直接返回该类别;当所有的特征向量都分过一次后还是有1个以上的类别,那么选择出现最多的类别返回,实现如下: 两种情况,一种是当只剩下一种分类时,直接返回该类别;当所有的特征向量都分过一次后还是有1个以上的类别,那么选择出现最多的类别返回,实现如下: 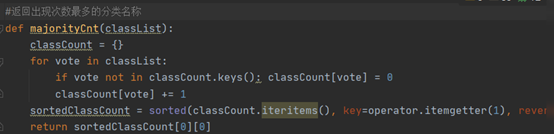 这里用了一个排序,当然也可以遍历一次即可,返回排序后次数最多的类别返回。 ②递归建树 这里用了一个排序,当然也可以遍历一次即可,返回排序后次数最多的类别返回。 ②递归建树 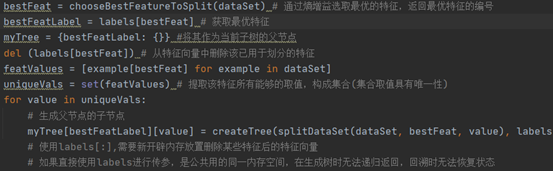 这里如果不是叶子结点,那么就需要根据某一个特征进行划分,这里的特征选择依靠的就是上面实现的选择信息增益最大的特征;需要注意的就是建树的结构的字典,因此选出最优划分特征后要将该特征作为键,将子树(后面通过遍历该特征的值得到)作为值来生成字典的键值对作为一个树结点; 而使用labels[:],需要新开辟内存放置删除某些特征后的特征向量,如果直接使用labels进行传参,是公共用的内存空间,在生成树时无法递归返回,因此下一子树的建立会出现错误。 这里如果不是叶子结点,那么就需要根据某一个特征进行划分,这里的特征选择依靠的就是上面实现的选择信息增益最大的特征;需要注意的就是建树的结构的字典,因此选出最优划分特征后要将该特征作为键,将子树(后面通过遍历该特征的值得到)作为值来生成字典的键值对作为一个树结点; 而使用labels[:],需要新开辟内存放置删除某些特征后的特征向量,如果直接使用labels进行传参,是公共用的内存空间,在生成树时无法递归返回,因此下一子树的建立会出现错误。  因此同样的,建树的函数传入的也不能是固定的内存空间而应该是一个存放在栈中的变量。 ③返回结点 因此同样的,建树的函数传入的也不能是固定的内存空间而应该是一个存放在栈中的变量。 ③返回结点  当该树结点的键值对字典层层递归返回建立完毕过后就可以将该结点递归返回到上一层作为上一层特征的值(子结点)。 2.4. 预测 当该树结点的键值对字典层层递归返回建立完毕过后就可以将该结点递归返回到上一层作为上一层特征的值(子结点)。 2.4. 预测  上面也提到过树的结构是依靠字典实现的,那么这里我们的测试数据在决策树中层层下降的过程其实就是根据键(特征)值(字树)对层层到当前特征的子结点(字典)中,直到遇到叶子结点后返回该分类即可。 2.5. 分类结果 上面也提到过树的结构是依靠字典实现的,那么这里我们的测试数据在决策树中层层下降的过程其实就是根据键(特征)值(字树)对层层到当前特征的子结点(字典)中,直到遇到叶子结点后返回该分类即可。 2.5. 分类结果   可以看到对train训练集训练后得到的决策树预测测试机test的正确率为0.61008 2.6. 时间/空间复杂度分析 建树的过程与查询的过程需要分别分析,假设特征数为a,平均特征取值数为b,样本数目为n; 其中,建树的过程平均时间复杂度为O(n*log(n)*a),而查询的时间复杂度就是树的深度O(d);而空间复杂度因为没有剪枝,因此这里空间复杂度是O(ab),需要ab个左右的结点来存储树; 2.7. 性能说明 决策树算法中学习简单的决策规则建立决策树模型的过程非常容易理解, 决策树模型可以可视化,非常直观 应用范围广,可用于分类和回归,而且非常容易做多类别的分类。 但是它同样也还有很多不足:ID3算法采用信息增益来选择最优划分特征,然而人们发现,信息增益倾向与取值较多的特征,对于这种具有明显倾向性的属性,往往容易导致结果误差;ID3算法没有考虑连续值,对与连续值的特征无法进行划分; 可以看到对train训练集训练后得到的决策树预测测试机test的正确率为0.61008 2.6. 时间/空间复杂度分析 建树的过程与查询的过程需要分别分析,假设特征数为a,平均特征取值数为b,样本数目为n; 其中,建树的过程平均时间复杂度为O(n*log(n)*a),而查询的时间复杂度就是树的深度O(d);而空间复杂度因为没有剪枝,因此这里空间复杂度是O(ab),需要ab个左右的结点来存储树; 2.7. 性能说明 决策树算法中学习简单的决策规则建立决策树模型的过程非常容易理解, 决策树模型可以可视化,非常直观 应用范围广,可用于分类和回归,而且非常容易做多类别的分类。 但是它同样也还有很多不足:ID3算法采用信息增益来选择最优划分特征,然而人们发现,信息增益倾向与取值较多的特征,对于这种具有明显倾向性的属性,往往容易导致结果误差;ID3算法没有考虑连续值,对与连续值的特征无法进行划分;
3. 支持向量机(SVM)
注:这个算法包括后面的人工神经网络都是通过调库的方式实现,且数据的读取与第一个算法朴素贝叶斯的方式相同 3.1. 数据加载 同朴素贝叶斯算法; 3.2. 训练模型   这里使用LinearSVC模型,LinearSVC实现了线性分类支持向量机,它是给根据liblinear实现的,可以用于二类分类,也可以用于多类分类。 它的默认参数极多,其中最值得注意的就是multi_class这一个参数,该参数指明多分类时的方式; SVM处理多分类的方法主要有两种,一种是这里的默认参数osr(one vs rest),即训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。另一种常用的就是ovo(one vs one),其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM,当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。 3.3. 参数说明 这里只挑一些在算法原理中出现的比较重要的参数进行说明; ①loss:string, ‘hinge’ or ‘squared_hinge’ (default=’squared_hinge’) loss指定使用哪一个损失函数。 “hinge”是标准的SVM损失(例如由SVC类使用), 而“squared_hinge”是hinge损失的平方。 ②tol : float, optional (default=1e-4) 参数迭代更新的停止阈值,小于该值则停止更新参数。 ③multi_class: string, ‘ovr’ or ‘ovo’ (default=’ovr’) 指定多分类策略(上面解释了ovr和ovo的实现原理) ④max_iter:int, (default=1000) 指定最大迭代次数,实际上当小于阈值后同样不会再迭代了 3.4. 测试结果 这里使用LinearSVC模型,LinearSVC实现了线性分类支持向量机,它是给根据liblinear实现的,可以用于二类分类,也可以用于多类分类。 它的默认参数极多,其中最值得注意的就是multi_class这一个参数,该参数指明多分类时的方式; SVM处理多分类的方法主要有两种,一种是这里的默认参数osr(one vs rest),即训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。另一种常用的就是ovo(one vs one),其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM,当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。 3.3. 参数说明 这里只挑一些在算法原理中出现的比较重要的参数进行说明; ①loss:string, ‘hinge’ or ‘squared_hinge’ (default=’squared_hinge’) loss指定使用哪一个损失函数。 “hinge”是标准的SVM损失(例如由SVC类使用), 而“squared_hinge”是hinge损失的平方。 ②tol : float, optional (default=1e-4) 参数迭代更新的停止阈值,小于该值则停止更新参数。 ③multi_class: string, ‘ovr’ or ‘ovo’ (default=’ovr’) 指定多分类策略(上面解释了ovr和ovo的实现原理) ④max_iter:int, (default=1000) 指定最大迭代次数,实际上当小于阈值后同样不会再迭代了 3.4. 测试结果  直接调用LinearSVC的predict函数即可根据输入的特征向量得到测试标签。 直接调用LinearSVC的predict函数即可根据输入的特征向量得到测试标签。  直接通过LinearSVC的score函数实现,该函数可以根据输入的特征向量得到测试标签,然后与输入的真实标签相对比,进而得到正确的预测率。 直接通过LinearSVC的score函数实现,该函数可以根据输入的特征向量得到测试标签,然后与输入的真实标签相对比,进而得到正确的预测率。  它在训练集上的测试结果为0.837,而在测试集上的结果是0.650,说明训练出来的SVM并不具有很好的泛化性; 3.5. 性能分析 它在训练集上的测试结果为0.837,而在测试集上的结果是0.650,说明训练出来的SVM并不具有很好的泛化性; 3.5. 性能分析
支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量;SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。 SVM算法对大规模训练样本难以实施,由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算,将耗费大量的机器内存和运算时间。 ovr多分类方法需要训练k个分类器,个数较少,其分类速度相对较快。但是因为每个分类器的训练都是将全部的样本作为训练样本,这样在求解二次规划问题时,训练速度会随着训练样本的数量的增加而急剧减慢。
4. 人工神经网络
4.1. 数据读取 同朴素贝叶斯算法的读取方式,当然也可以使用one-hot编码方式实现。 4.2. 模型训练 MLPClassifier是一个监督学习算法,MLP又名多层感知机,也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐藏层,如果没有隐藏层即可解决线性可划分的数据问题,模型的训练就依靠python的sklearn库中的MLPClassifier实现。  MLPClassifier的参数也有很多,接下来分析在算法远离中出现过的最重要的一些参数; 4.3. 参数分析 ①activation :激活函数,{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认relu logistic:其实就是sigmod,f(x) = 1 / (1 + exp(-x)). ②hidden_layer_sizes :指定隐藏层的设置,例如hidden_layer_sizes=(10, 10),表示有两层隐藏层,第一层隐藏层有10个神经元,第二层也有10个神经元。 ③solver: {‘lbfgs’, ‘sgd’, ‘adam’}, 默认adam,用来优化权重 adam:机遇随机梯度的优化器 adam优化算法是一种对随机梯度下降法的扩展。 ④max_iter: int,可选,默认200,最大迭代次数。 这里200次远远无法收敛(隐藏层设置的太简单了),因此需要加大迭代次数; MLPClassifier的参数也有很多,接下来分析在算法远离中出现过的最重要的一些参数; 4.3. 参数分析 ①activation :激活函数,{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认relu logistic:其实就是sigmod,f(x) = 1 / (1 + exp(-x)). ②hidden_layer_sizes :指定隐藏层的设置,例如hidden_layer_sizes=(10, 10),表示有两层隐藏层,第一层隐藏层有10个神经元,第二层也有10个神经元。 ③solver: {‘lbfgs’, ‘sgd’, ‘adam’}, 默认adam,用来优化权重 adam:机遇随机梯度的优化器 adam优化算法是一种对随机梯度下降法的扩展。 ④max_iter: int,可选,默认200,最大迭代次数。 这里200次远远无法收敛(隐藏层设置的太简单了),因此需要加大迭代次数;   当设置为1000时可以看到明显的提升,正确率从0.5提高到了0.8,但是当继续增加迭代次数时test测试集的准确率下降了,说明出现了过拟合现象; ⑤tol:float,optional,默认1e-4 优化的容忍度,容差优化。当n_iter_no_change连续迭代的损失或分数没有提高至少tol时,除非将learning_rate设置为’adaptive’,否则认为会达到收敛并且训练停止。 ⑥beta_1、beta_2:float,optional,默认值为0.9、0.999,估计一阶矩向量的指数衰减率应为[0,1)。仅在solver ='adam’时使用; 我这里在将beta_1、beta_2调小一些之后可以得到更好的预测正确率。 4.4. 测试结果 当设置为1000时可以看到明显的提升,正确率从0.5提高到了0.8,但是当继续增加迭代次数时test测试集的准确率下降了,说明出现了过拟合现象; ⑤tol:float,optional,默认1e-4 优化的容忍度,容差优化。当n_iter_no_change连续迭代的损失或分数没有提高至少tol时,除非将learning_rate设置为’adaptive’,否则认为会达到收敛并且训练停止。 ⑥beta_1、beta_2:float,optional,默认值为0.9、0.999,估计一阶矩向量的指数衰减率应为[0,1)。仅在solver ='adam’时使用; 我这里在将beta_1、beta_2调小一些之后可以得到更好的预测正确率。 4.4. 测试结果 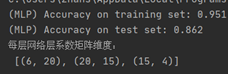 如图所示,我们通过MLP训练后的模型效果还不错,在训练集上的预测正确率为0.951,减少了过拟合的可能,在测试集上的预测正确率为0.862,有较好的泛化性。 而我输出的每层权重矩阵维度,直接输出MLPClassifier的coefs_变量就可以得到,其中列表中的第i个元素表示第 i 层和第 i+1 层之间的权重的权重矩阵,整个神经网络有四层,因此含有三个矩阵。 4.5. 性能分析 通过测试结果可以看出相比于支持向量机,神经网络的对于我们的汽车分类的数据有更好的泛化性,这可能是因为支持向量机本质上是二分类的,因此处理多分类问题表现不好。 神经网络的处理能力可以说好于其它的机器学习算法,它模拟人脑的信息传播与处理过程使得它几乎可以处理复杂的非线性函数,并且能发现不同输入间依赖关系。神经网络也允许增量式训练,并且通常不要求大量空间来存储训练模型,因为它们需要保存的仅仅是一组代表突触权重的数字而已。 神经网络的主要缺点在于它是一种黑盒方法。在现实中,一个网络也许会有数百个节点和上千个突触,这使我们很难确知网络如何得到最终的答案。在训练数据的比率及与问题相适应的网络规模方面,没有明确的规则可以遵循。最终的决定往往需要依据大量的试验。 如图所示,我们通过MLP训练后的模型效果还不错,在训练集上的预测正确率为0.951,减少了过拟合的可能,在测试集上的预测正确率为0.862,有较好的泛化性。 而我输出的每层权重矩阵维度,直接输出MLPClassifier的coefs_变量就可以得到,其中列表中的第i个元素表示第 i 层和第 i+1 层之间的权重的权重矩阵,整个神经网络有四层,因此含有三个矩阵。 4.5. 性能分析 通过测试结果可以看出相比于支持向量机,神经网络的对于我们的汽车分类的数据有更好的泛化性,这可能是因为支持向量机本质上是二分类的,因此处理多分类问题表现不好。 神经网络的处理能力可以说好于其它的机器学习算法,它模拟人脑的信息传播与处理过程使得它几乎可以处理复杂的非线性函数,并且能发现不同输入间依赖关系。神经网络也允许增量式训练,并且通常不要求大量空间来存储训练模型,因为它们需要保存的仅仅是一组代表突触权重的数字而已。 神经网络的主要缺点在于它是一种黑盒方法。在现实中,一个网络也许会有数百个节点和上千个突触,这使我们很难确知网络如何得到最终的答案。在训练数据的比率及与问题相适应的网络规模方面,没有明确的规则可以遵循。最终的决定往往需要依据大量的试验。
六、 相关思考
如何在参数学习或者其他方面提高算法的分类性能?
1. 朴素贝叶斯算法
朴素贝叶斯算法原理方面十分简单,速度也很快,但是却存在很多缺点,朴素贝叶斯的基本假设是每个特征对结果做出独立且平等的贡献但条件独立性假设在现实中很难满足,导致其性能有所下降。 因此对于朴素贝叶斯的改进,我觉得可以通过挖掘数据中的关联规则和该规则的置信度对不同的特征赋予不同的权重,进而在保持朴素贝叶斯简单性的基础上有效提高它的分类性能,当然这种方法需要加入数据学习的部分,可能会降低速度。
2. 决策树算法
我实现的决策树算法是最简单的ID3,并且没有任何的剪枝处理。从这一角度出发它的 优化方法很多,首先最为简单的就是加入剪枝,预剪枝与后剪枝都可以剪掉树中没有必要或者说过拟合的部分。在决策树生成分支的过程,利用统计学的方法对即将分支的节点进行判断,如果分支后使得子集的样本统计特性不满足规定的阈值,则停止分支在决策树充分生长后,修剪掉多余的分支。 或者在决策树充分生长后,修剪掉多余的分支。 除了剪枝之外,我的决策树算法还可以通过改变特征选择的准则来改进算法,比如ID3使用的是信息增益作为选择准则,但是存在归纳偏置问题(选择类别较多的属性),因此可以使用信息增益率来作为特征选择准则。
3. 支持向量机算法
从SVM的参数中可以很明显的看出一种改进方法,即增加迭代次数或者减小学习率 确保损失函数收敛,当然这样肯定会影响到算法速度,但却可以得到更好的学习结果。 此外,因为SVM本质是二分类的,要想进行样本的四分类只有构建多个分类器进而划分,那么如果我们改进算法,使其可以对四分类问题一次性构建两个分类超平面,在同一个分类问题中求解出两个超平面的表达式进而将数据进行四分类,这样可以明显减少分类器的数目(对于2k分类问题同样适用)。
4. 人工神经网络
首先就是在上面提到的学习率与迭代次数,此外对于人工神经网络来说还可以通过改进 神经网络的结构,即修改它的隐藏层神经元个数与层数以及各层之间的拓扑结构等方式。更多的我就没有涉及到了。
|