| 翻译:L0 Norm, L1 Norm, L2 Norm & L | 您所在的位置:网站首页 › 最大值英文怎么表示 › 翻译:L0 Norm, L1 Norm, L2 Norm & L |
翻译:L0 Norm, L1 Norm, L2 Norm & L
|
Norm_(mathematics)
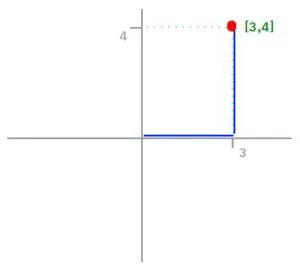
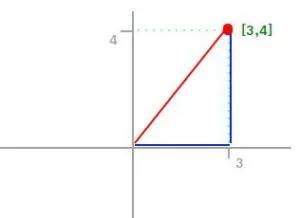
First of all, what is a Norm? In Linear Algebra, a Norm refers to the total length of all the vectors in a space. There are different ways to measure the magnitude of vectors, here are the most common: L0 Norm: It is actually not a norm. (See the conditions a norm must satisfy here【维基百科关于norm的定义】). Corresponds to the total number of nonzero elements in a vector. For example, the L0 norm of the vectors (0,0) and (0,2) is 1 because there is only one nonzero element. A good practical example of L0 norm is the one that gives Nishant Shukla, when having two vectors (username and password). If the L0 norm of the vectors is equal to 0, then the login is successful. Otherwise, if the L0 norm is 1, it means that either the username or password is incorrect, but not both. And lastly, if the L0 norm is 2, it means that both username and password are incorrect. L1 Norm: Also known as Manhattan Distance or Taxicab norm. L1 Norm is the sum of the magnitudes of the vectors in a space. It is the most natural way of measure distance between vectors, that is the sum of absolute difference of the components of the vectors. In this norm, all the components of the vector are weighted equally. Having, for example, the vector X = [3,4]: The L1 norm is calculated by As you can see in the graphic, the L1 norm is the distance you have to travel between the origin (0,0) to the destination (3,4), in a way that resembles how a taxicab drives between city blocks to arrive at its destination. L2 norm: Is the most popular norm, also known as the Euclidean norm. It is the shortest distance to go from one point to another.
As you can see in the graphic, L2 norm is the most direct route. There is one consideration to take with L2 norm, and it is that each component of the vector is squared, and that means that the outliers have more weighting, so it can skew results. L-infinity norm: Gives the largest magnitude among each element of a vector.给出向量的每个元素中的最大幅度。 Having the vector X= [-6, 4, 2], the L-infinity norm is 6. In L-infinity norm, only the largest element has any effect. So, for example, if your vector represents the cost of constructing a building, by minimizing L-infinity norm we are reducing the cost of the most expensive building. 其他资料:范数(norm) 范数(norm)是数学中的一种基本概念。在泛函分析中,它定义在赋范线性空间中,并满足一定的条件,即①非负性;②齐次性;③三角不等式。它常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。 p范数: ║ x ║ p = ( ∣ x 1 ∣ p + ∣ x 2 ∣ p + … + ∣ x n ∣ p ) 1 / p ║x║_p=(|x1|^p+|x2|^p+…+|xn|^p)^{1/p} ║x║p=(∣x1∣p+∣x2∣p+…+∣xn∣p)1/p 当p取 的时候分别是以下几种最简单的情形: 1-范数: ║ x ║ 1 = │ x 1 │ + │ x 2 │ + … + │ x n │ ║x║_1=│x1│+│x2│+…+│xn│ ║x║1=│x1│+│x2│+…+│xn│ 2-范数: ║ x ║ 2 = (│ x 1 │ 2 + │ x 2 │ 2 + … + │ x n │ 2 ) 1 / 2 ║x║_2=(│x1│^2+│x2│^2+…+│xn│^2)^{1/2} ║x║2=(│x1│2+│x2│2+…+│xn│2)1/2 ∞-范数: ║ x ║ ∞ = m a x (│ x 1 │,│ x 2 │, … ,│ x n │) ║x║_∞=max(│x1│,│x2│,…,│xn│) ║x║∞=max(│x1│,│x2│,…,│xn│) L0范数是指向量中非0的元素的个数 L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization),又称曼哈顿距离,最小绝对偏差(LAD),最小绝对误差(LAE),又叫做 taxicab-norm 或者 Manhattan-norm。这基本上是将目标值(Yi)与估计值 (f(xi)) 之间的绝对差(S)的总和最小化:
OK,来个一句话总结:L1范数和L0范数可以实现稀疏,L1因具有比L0更好的优化求解特性而被广泛应用。 好,到这里,我们大概知道了L1可以实现稀疏,但我们会想呀,为什么要稀疏?让我们的参数稀疏有什么好处呢?这里扯两点: 1)特征选择(Feature Selection): 大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。 2)可解释性(Interpretability): 另一个青睐于稀疏的理由是,模型更容易解释。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:y=w1x1+w2x2+…+w1000x1000+b(当然了,为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的w就只有很少的非零元素,例如只有5个非零的wi,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。但如果1000个wi都非0,医生面对这1000种因素,累觉不爱。 L2范数: ||W||2。它也不逊于L1范数,它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”,欧几里德距离,最小二乘。它基本上是最小化目标值(Y i)与估计值(f(x i)之间的差(S)的平方和的平方根 翻译原文:https://montjoile.medium.com/l0-norm-l1-norm-l2-norm-l-infinity-norm-7a7d18a4f40c |
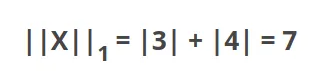
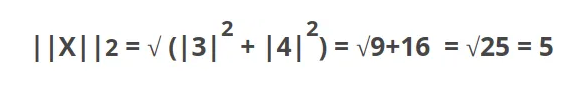
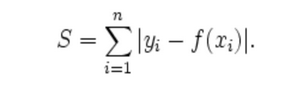
【本文地址】