| 卡方分布的性质及应用 | 您所在的位置:网站首页 › 显著性水平为005的f分布表 › 卡方分布的性质及应用 |
卡方分布的性质及应用
|
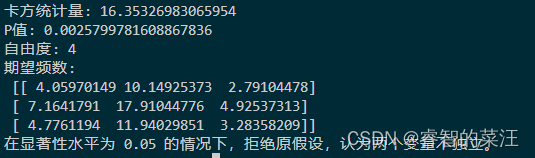
卡方分布是统计学常用的分布之一。其定义为:若N个相互独立的随机变量 卡方分布有一些比较常用的性质。 性质1:若 这个性质有比较经典的应用,在统计学中,样本均值 若该分布的期望为 所以 我们又知道, 两者又相互独立,所以, 性质2:若 证明如下:当自由度为1时,已知 X的密度函数为 那么 所以 由于 那么,由上述性质1和 性质3:若 证明如下:同样还是当自由度为1时,已知 X的密度函数为 那么 那么 所以 同样的,由于相互独立,满足 卡方分布有着比较广泛的应用,以下是4个比较常用的应用场景: 独立性检验:检验两个分类变量是否相互独立。拟合优度检验:检验实际观测值与理论分布的一致性。同质性检验:检验多个样本是否来自同一总体。相关性检验:在某些情况下,卡方分布可以用来检验变量之间的相关性 应用场景1独立性检验:假设我们想要检验教育水平和职业选择是否独立。我们收集了不同教育背景(高中以下、大学、研究生)人群的职业选择数据(蓝领、白领、自由职业者)。通过构建列联表和进行卡方独立性检验,我们可以确定教育水平是否影响职业选择。 假设我们收集了以下的数据: 教育水平\职业选择蓝领白领自由职业者总计高中及以下105217大学520530研究生115420总计16401167 步骤一:假设提出原假设 备择假设 期望频数的计算公式为 其中 比如 使用以下公式计算卡方统计量: 其中 例如: 依次对所有单元格进行上述计算求和即可。 步骤四:确定自由度这个例子中,卡方分布的自由度为行数减一乘以列数减一,即df=4,计算公式为: 选择一个合适的p值,比如0.01,再与卡方的表格进行比较即可。 这个过程可以写为python代码形式,代码如下: import numpy as np from scipy.stats import chi2_contingency # 观测频数数据,构建列联表 # 这里使用的是之前教育水平和职业选择的示例数据 data = np.array([[10, 5, 2], [5, 20, 5], [1, 15, 4]]) # 执行卡方独立性检验 chi2, p, dof, expected = chi2_contingency(data) # 输出结果 print("卡方统计量:", chi2) print("P值:", p) print("自由度:", dof) print("期望频数:\n", expected) # 做出结论 alpha = 0.05 # 显著性水平 if p < alpha: print("在显著性水平为 {:.2f} 的情况下,拒绝原假设,认为两个变量不独立。".format(alpha)) else: print("在显著性水平为 {:.2f} 的情况下,不能拒绝原假设,认为两个变量独立。".format(alpha))运行结果如下:
可以看到,在我们选定的显著性水平上拒绝了H0,也即教育水平和职业选择其实是有关系的。 应用场景2拟合优度检验:一个工厂生产了一批零件,根据历史数据,我们知道合格品和次品的比例大约是95%和5%。现在,我们随机抽取了100个零件进行检查,发现有90个合格品和10个次品。我们可以使用卡方拟合优度检验来确定实际观测结果是否与预期的95%合格品比例一致。 步骤一:假设提出原假设 备择假设 观测数据里有90个合格品和10个次品 步骤三:计算期望频数预期的合格数量为95个 预期的不合格品数量为5个 步骤四:计算卡方统计量卡方统计量为 自由度为类别数减一,总共只有合格不合格两个类别,因此自由度为1 步骤六:确定p值,得出结论根据选定的p值,比如p=0.05,判断是否拒绝原假设 这个过程可以写成如下的python代码形式 from scipy.stats import chisquare # 观测频数 observed = [90, 10] # 预期频数,基于95%和5%的比例 expected = [100 * 0.95, 100 * 0.05] # 执行卡方拟合优度检验 chi2, p = chisquare(f_obs=observed, f_exp=expected) print("卡方统计量:", chi2) print("P值:", p) # 显著性水平 alpha = 0.05 if p < alpha: print("在显著性水平为 {:.2f} 的情况下,拒绝原假设。".format(alpha)) else: print("在显著性水平为 {:.2f} 的情况下,不能拒绝原假设。".format(alpha))运行结果如下:
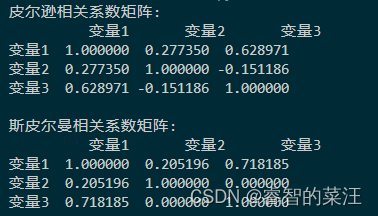
可以看到,在5%的显著性水平上拒绝了原假设。 应用场景3卡方同质性检验:假设我们有来自三个不同地区的数据,想要检验这三个地区的人口年龄分布是否相同。我们可以收集每个地区不同年龄段的人口数量,构建列联表,并使用卡方同质性检验来确定这三个地区的人口年龄分布是否具有统计学上的同质性。 步骤一:假设提出原假设 备择假设 收集每个地区不同年龄段的人口数量。例如,假设我们有四个年龄段:0-20, 21-40, 41-60, 61+。 步骤三:构建列联表创建一个列联表,行表示地区,列表示年龄段,单元格中的数值为该年龄段在对应地区的人口数量。 步骤四:计算期望频数期望频数同样由 其中 同样使用以下公式计算卡方统计量: 其中 卡方分布的自由度为行数减一乘以列数减一,计算公式为: 使用卡方分布表或统计软件,根据卡方统计量和自由度确定P值。如果P值小于显著性水平(例如0.05),则拒绝原假设,认为至少有一个地区的人口年龄分布与其他地区不同。如果P值大于或等于显著性水平,则不能拒绝原假设,认为三个地区的人口年龄分布是相同的。 应用场景4虽然卡方分布通常不直接用于测量相关性,但在某些情况下,比如列联表中两个分类变量的相关性检验,可以使用卡方统计量。例如,我们想要检验不同血型(A、B、AB、O)和某种疾病发生率之间的关系。通过收集不同血型人群的疾病发生率数据,构建列联表,并进行卡方检验,我们可以评估血型和疾病发生率之间是否存在统计学上的关联。 同样的步骤,这里不再赘述。卡方分布虽然可以做,但是这个应用场景的情况下使相关系数的方法可能会更多。相关系数矩阵打印的python方法如下: import pandas as pd from scipy.stats import pearsonr from scipy.stats import spearmanr # 创建一个示例数据集 data = { '变量1': [20, 21, 19, 20, 22], '变量2': [12, 11, 13, 14, 15], '变量3': [88, 99, 91, 92, 95] } # 将数据转换为pandas DataFrame df = pd.DataFrame(data) # 计算皮尔逊相关系数矩阵 pearson_matrix = df.corr(method='pearson') # 打印皮尔逊相关系数矩阵 print("皮尔逊相关系数矩阵:") print(pearson_matrix) # 如果需要计算斯皮尔曼相关系数矩阵 spearman_matrix = df.corr(method='spearman') # 打印斯皮尔曼相关系数矩阵 print("\n斯皮尔曼相关系数矩阵:") print(spearman_matrix)运行结果如下:
如上就是卡方分布的一些应用实例。 |

【本文地址】