| 【玩转GPU】全面解析GPU硬件技术:显卡、显存、算力和功耗管理的核心要点 | 您所在的位置:网站首页 › 显存和共享显存 › 【玩转GPU】全面解析GPU硬件技术:显卡、显存、算力和功耗管理的核心要点 |
【玩转GPU】全面解析GPU硬件技术:显卡、显存、算力和功耗管理的核心要点
|
摘要:本文将全面探讨GPU硬件技术,从硬件架构到性能评估,深入揭示显卡、显存、算力和功耗管理等关键要点。了解GPU硬件技术对于优化应用性能、加速计算任务以及推动科学研究具有重要意义。 一、GPU硬件架构:GPU硬件架构中最核心的组件是图形处理核心(CUDA core),一个GPU通常包含数百到数千个CUDA core,并拥(Multiprocessors)以支持高度并行计算。每个CUDA core能够系列指令,实现高效并行计算。此外,GPU还包括纹理单元、光栅化器和存储控制器等功能模块。 GPU的图形(处理)流水线完成如下的工作:(并不一定是按照如下顺序): 顶点处理:这阶段GPU读取描述3D图形外观的顶点数据并根据顶点数据确定3D图形的形状及位置关系,建立起3D图形的骨架。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的VertexShader(定点着色器)完成。光栅化计算:显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。纹理帖图:顶点单元生成的多边形只构成了3D物体的轮廓,而纹理映射(texturemapping)工作完成对多变形表面的帖图,通俗的说,就是将多边形的表面贴上相应的图片,从而生成“真实”的图形。TMU(Texturemapping unit)即是用来完成此项工作。像素处理:这阶段(在对每个像素进行光栅化处理期间)GPU完成对像素的计算和处理,从而确定每个像素的最终属性。在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Pixel Shader(像素着色器)完成最终输出,由ROP(光栅化引擎)最终完成像素的输出,1帧渲染完毕后,被送到显存帧缓冲区。在GPU出现之前,CPU一直负责着计算机中主要的运算工作,包括多媒体的处理工作。CPU的架构是有利于X86指令集的串行架构,CPU从设计思路上适合尽可能快的完成一个任务。 但是如此设计的CPU在多媒体处理中的缺陷也显而易见:多媒体计算通常要求较高的运算密度、多并发线程和频繁地存储器访问,而由于X86平台中CISC(Complex Instruction Set Computer)架构中暂存器数量有限,CPU并不适合处理这种类型的工作。 以Intel为代表的厂商曾经做过许多改进的尝试,从1999年开始为X86平台连续推出了多媒体扩展指令集SSE(Streaming SIMD Extensions)的一代到四代版本,但由于多媒体计算对于浮点运算和并行计算效率的高要求,CPU从硬件本身上就难以满足其巨大的处理需求,仅仅在软件层面的改并不能起到根本效果。 对于GPU来说,它的任务是在屏幕上合成显示数百万个像素的图像,也就是同时拥有几百万个任务需要并行处理,因此GPU被设计成可并行处理很多任务,而不是像CPU那样完成单任务。 因此CPU和GPU架构差异很大,CPU功能模块很多,能适应复杂运算环境;GPU构成则相对简单,目前流处理器和显存控制器占据了绝大部分晶体管。 CPU中大部分晶体管主要用于构建控制电路(比如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。而GPU的控制相对简单,且对Cache的需求小,所以大部分晶体管可以组成各类专用电路、多条流水线,使得GPU的计算速度有了突破性的飞跃,拥有了更强大的处理浮点运算的能力。 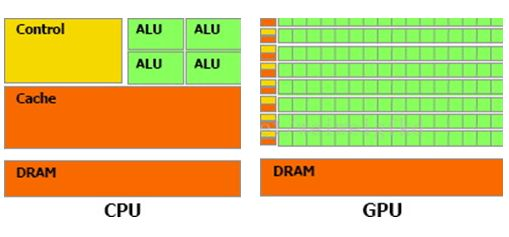 从硬件设计上来讲,CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。 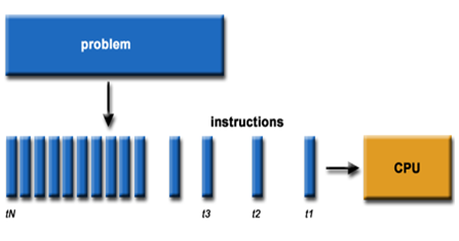 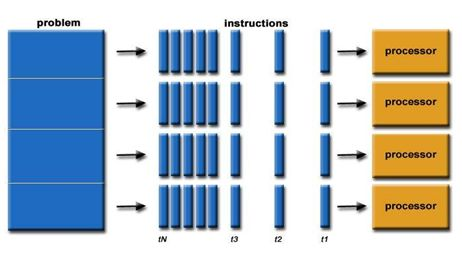 通过上图我们可以较为容易地理解串行运算和并行运算之间的区别。传统的串行编写软件具备以下几个特点:要运行在一个单一的具有单一中央处理器(CPU)的计算机上;一个问题分解成一系列离散的指令;指令必须一个接着一个执行;只有一条指令可以在任何时刻执行。 而并行计算则改进了很多重要细节:要使用多个处理器运行;一个问题可以分解成可同时解决的离散指令;每个部分进一步细分为一系列指示;每个部分的问题可以同时在不同处理器上执行。提高了算法的处理速度。 为充分利用GPU的计算能力,NVIDIA在2006年推出了CUDA(ComputeUnifiedDevice Architecture,统一计算设备架构)这一编程模型。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员现在可以使用C语言来为CUDA架构编写程序。 通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的QuadroGPU进行计算。以GeForce 8800 GTX为例,其核心拥有128个内处理器。利用CUDA技术,就可以将那些内处理器串通起来,成为线程处理器去解决数据密集的计算。而各个内处理器能够交换、同步和共享数据。 从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。 开发库是基于CUDA技术所提供的应用开发库。CUDA的1.1版提供了两个标准的数学运算库:CUFFT (离散快速傅立叶变换)和CUBLAS(离散基本线性计算)的实现。这两个数学运算库所解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。开发人员在开发库的基础上可以快速、方便的建立起自己的计算应用。此外,开发人员也可以在CUDA的技术基础上实现出更多的开发库。 运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(HostCode),一种是运行在GPU上的设备代码(Device Code)。 不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在GPGPU开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。 由于目前存在着多种GPU版本的NVIDIA显卡,不同版本的GPU之间都有不同的差异,因此驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。由于体系结构中硬件抽象层的存在,CUDA今后也有可能发展成为一个通用的GPU标准接口,兼容不同厂商的GPU产品。 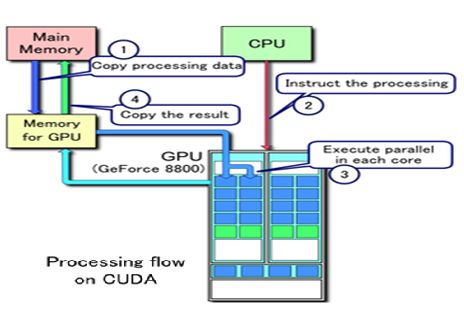 对于软件开发者来说,使用Cuda平台调用Cuda的加速库使用的语言包括:C、C++和Fortran。C/C++编程者使用UDAC/C++并用nvcc进行编译。 Nvidia的LLVM库是基于C/C++编译器的。Fortran的开发者能够使用CUDA Fortran,编译使用PGI CUDA Fortran。当然CUDA平台也支持其他的编程接口,包括OpenCL,微软的DirectCompute、OpenGL ComputeShaders和 C++ AMP。第三方的开发者也可以使用Python、Perl、Fortran、Java、Ruby、Lua、Haskell、R、MATLAB、IDL由曼赛马提亚原生支持。 二、显存技术:显存(Graphics Memory)是GPU中重要的组成部分,用于存储图像、计算结果、模型参数等数据。主流的显存技术有GDDR(Graphics Double Data Rate)和HBM(High Bandwidth Memory)。GDDR具有较大的容量和较低的成本,适用于大规模图形处理;而HBM则具有更高的带宽和更低的功耗,适用于高性能计算和深度学习等任务。 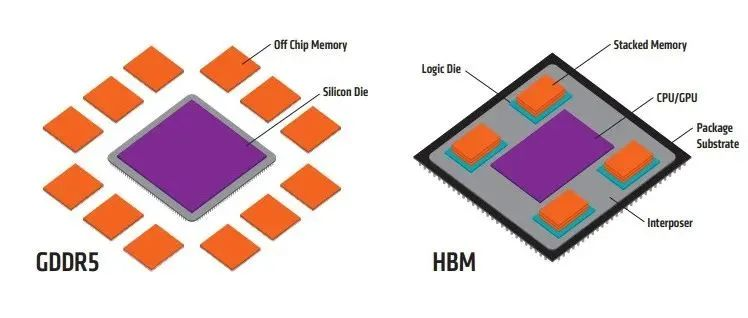 存储器子系统的主要功能是在云计算和人工智能 (AI)、汽车和移动等广泛应用中尽可能快速可靠地为主机(CPU 或 GPU)提供必要的数据或指令。片上系统 (SoC) 设计人员可以选择多种类型的存储器技术,每种技术都具有不同的特性和高级功能。双数据速率 (DDR) 同步动态随机存取存储器 (SDRAM) 已成为主系统存储器最主流的存储器技术,因为它使用电容器作为存储元件来实现高密度和简单架构、低延迟和高性能、无限存取耐力和低功耗。 DDR DRAM标准设计人员不断为他们的 SoC 添加更多内核和功能;然而在保持低功耗和较小硅尺寸的同时提高性能仍然是一个至关重要的目标。DDR SDRAM(简称 DRAM)通过在双列直插式存储模块 (DIMM) 或分立式 DRAM 解决方案中提供密集、高性能和低功耗的存储器解决方案,以满足此类存储器要求。JEDEC 定义并开发了以下三种 DRAM 标准类别,帮助设计人员满足目标应用的功耗、性能和规格要求: 标准 DDR 面向服务器、云计算、网络、笔记本电脑、台式机和消费类应用,支持更宽的通道宽度、更高的密度和不同的形状尺寸。自 2013 年以来,DDR4 一直是这一类别中最常用的标准;预计 DDR5 设备会在不久的将来上市。移动 DDR 面向移动和汽车这些对规格和功耗非常敏感的领域,提供更窄的通道宽度和多种低功耗运行状态。今天最主流的标准是 LPDDR4,预计在不久的将来会推出 LPDDR5 设备。图形 DDR 面向需要极高吞吐量的数据密集型应用程序,例如图形相关应用程序、数据中心加速和 AI。图形 DDR (GDDR) 和高带宽存储器 (HBM) 是这一类型的标准。上述三种 DRAM 类别使用相同的 DRAM 阵列进行存储,以电容器作为基本存储元件。但是,每个类别都提供独特的架构功能,旨在最好地满足目标应用程序的要求。这些功能包括数据速率和数据宽度自定义、主机和 DRAM 之间的连接选项、电气规格、I/O(输入/输出)端接方案、DRAM 电源状态、可靠性特性等。图 1 展示了 JEDEC 的三类 DRAM 标准。 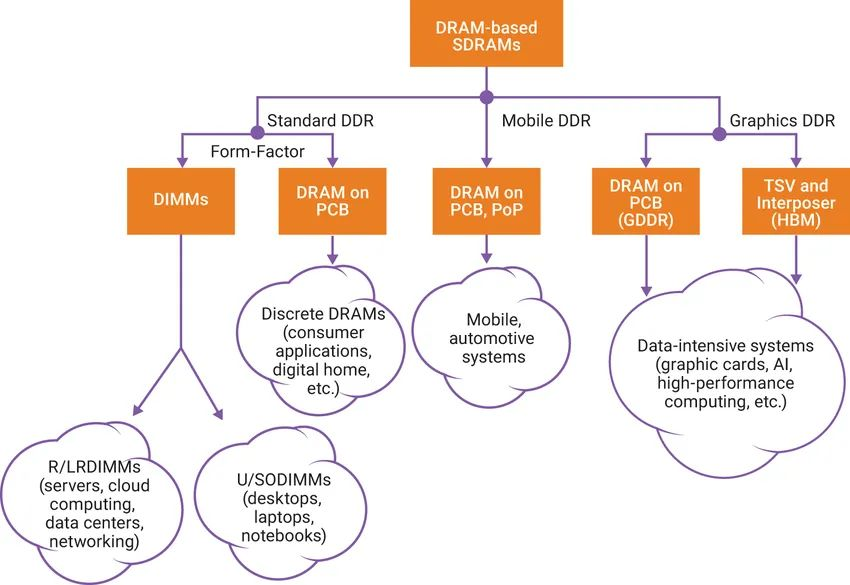 标准 DDR 标准 DDR标准 DDR DRAM 在企业服务器、数据中心、笔记本电脑、台式机和消费类应用等应用领域随处可见,可提供高密度和高性能。DDR4 是这一类别中最常用的标准,与其前代产品 DDR3 和 DDR3L(DDR3 的低功耗版本)相比具有多项性能优势: 与运行速度最高为 2133Mbps 的 DDR3 相比,它的数据速率更高,最高可达 3200Mbps工作电压更低(相较于 DDR3 的 1.5V 和 DDR3L 的 1.35V,它只有 1.2V)性能更高(例如存储体组)、功耗更低(例如数据总线反转),并且可靠性、可用性和可维护性 (RAS) 特性更优(例如包装后修复和数据循环冗余检查)由于各个 DRAM 晶圆尺寸从 4Gb 增加到 8Gb 和 16Gb,因此密度更高正在 JEDEC 开发的 DDR5 预计将在 1.1V 的工作电压下将运行数据速率提高到 4800Mbps。DDR5 新增多种架构和 RAS 特性,可有效处理这些高速运行,同时尽量缩短因存储器错误导致的系统停机时间。模块上的集成稳压器、更好的刷新方案、旨在提高通道利用率的架构、DRAM 上的内部纠错码 (ECC)、用于提高性能的更多存储体组以及更高的容量只是 DDR5 的一小部分关键特性。 移动 DDR与标准 DDR DRAM 相比,移动 DDR(也称为低功耗 DDR (LPDDR) DRAM)具有一些可以降低功耗的附加功能,而降低功耗正是移动/电池供电应用(如平板电脑、移动电话和汽车系统,以及 SSD 卡)的核心要求。LPDDR DRAM 可以比标准 DRAM 运行得更快,以实现高性能并提供低功耗状态,帮助提高电源效率和延长电池寿命。 与标准 DDR DRAM 通道(64 位宽)相比,LPDDR DRAM 通道通常为 16 位或 32 位宽。与标准 DRAM 产品一样,每个连续的 LPDDR 标准产品都瞄准了比其前代产品更高的性能和更低的功耗目标,并且任何两个 LPDDR 产品都不会彼此兼容。 LPDDR4 是这个类别中最常用的标准,在 1.1V 的工作电压下的数据速率最高可达 4267Mbps。LPDDR4 DRAM 通常是双通道设备,支持两个 x16(16 位宽)通道。各个通道都是独立的,因此具有自己的专用命令/地址 (C/A) 引脚。双通道架构为系统架构人员提供了灵活性,同时将 SoC 主机连接到 LPDDR4 DRAM。 LPDDR4X 是 LPDDR4 的一种变体,与 LPDDR4 完全相同,只是能够通过将 I/O 电压 (VDDQ) 从 1.1 V 降低到 0.6 V 来额外降低功耗。LPDD4X 设备也可以实现高达 4267Mbps 的速率。 LPDDR5 是 LPDDR4/4X 的后续产品,预计运行速率高达 6400Mbps,并且正在 JEDEC 进行积极开发。LPDDR5 DRAM 有望提供许多新的低功耗和可靠性特性,使其成为移动和汽车应用的理想选择。其中一种重要特性就是用于延长电池寿命的“深度睡眠模式”,有望显著节省空闲条件下的功耗。此外,还有一些新的架构特性使 LPDDR5 DRAM 能够以低于 LPDDR4/4X 的工作电压在此类高速条件下无缝运行。 图形 DDR针对高吞吐量应用(例如显卡和 AI)的两种不同的存储器架构是 GDDR 和 HBM。 GDDR 标准 GDDR DRAM 是专为图形处理器 (GPU) 和加速器设计的。数据密集型系统(如显卡、游戏控制台和高性能计算,包括汽车、AI 和深度学习)是 GDDR DRAM 设备常用的一些应用。GDDR 标准 (GDDR6/5/5X) 被架设为点对点 (P2P) 标准,能够支持高达 16Gbps 的速率。GDDR5 DRAM 一直用作离散的 DRAM 解决方案,能够支持高达 8Gbps 的速率,经过配置后可在设备初始化期间检测到的 ×32 模式或 ×16(折叠)模式下运行。 GDDR5X 的目标是每个引脚的传输速率为 10 到 14Gbps,几乎是 GDDR5 的两倍。GDDR5X 和 GDDR5 DRAM 的主要区别在于 GDDR5X DRAM 拥有的预加载为 16N,而不是 8N。与 GDDR5 每个芯片使用 170 个引脚相比,GDDR5X 每个芯片使用 190 个引脚。因此,GDDR5 和 GDDR5X 标准需要不同的 PCB。GDDR6 是最新的 GDDR 标准,支持在 1.35V 的较低工作电压下运行高达 16Gbps 的更高数据速率,而 GDDR5 需要 1.5V 才能达到该速率。 HBM/HBM2 标准 HBM 是 GDDR 存储器的替代品,可用于 GPU 和加速器。GDDR 存储器旨在以较窄的通道提供更高的数据速率,进而实现必要的吞吐量,而 HBM 存储器通过 8 条独立通道解决这一问题,其中每条通道都使用更宽的数据路径(每通道 128 位),并以 2Gbps 左右的较低速度运行。因此,HBM 存储器能够以更低的功耗提供高吞吐量,而规格上比 GDDR 存储器更小。HBM2 是目前该类别中最常用的标准,支持高达 2.4Gbps 的数据速率。 HBM2 DRAM 最多可叠加 8 个 DRAM 晶圆(包括一个可选的底层晶圆),可提供较小的硅片尺寸。晶圆通过 TSV 和微凸块相互连接。通常可用的密度包括每个 HBM2 封装 4 或 8GB。 除了支持更多的通道外,HBM2 还提供了一些架构更改,以提高性能并减少总线拥塞。例如,HBM2 具有“伪通道”模式,该模式将每个 128 位通道分成两个 64 位的半独立子通道。它们共享通道的行和列命令总线,却单独执行命令。增加通道数量可以通过避免限制性时序参数(例如 tFAW)以在每单位时间激活更多存储体,从而增加整体有效带宽。标准中支持的其他功能包括可选的 ECC 支持,可为每 128 位数据启用 16 个错误检测位。 预计 HBM3 将在几年内上市,并提供更高的密度、更大的带宽 (512GB/s)、更低的电压和更低的成本。表 1 显示了 GDDR6 和 HBM2 DRAM 的高级别比较结果: 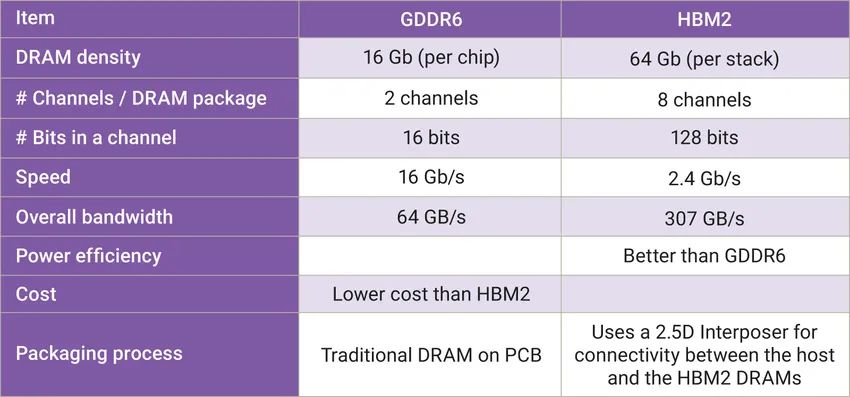 AMD认为GDDR5无法跟上GPU性能的增长速度,同时,GDDR5不断上升的功耗可能很快就会大到阻止图形性能的增长。相比之下,GDDR5需要更多的芯片和电路电压才能达到高带宽。 AMD认为GDDR5无法跟上GPU性能的增长速度,同时,GDDR5不断上升的功耗可能很快就会大到阻止图形性能的增长。相比之下,GDDR5需要更多的芯片和电路电压才能达到高带宽。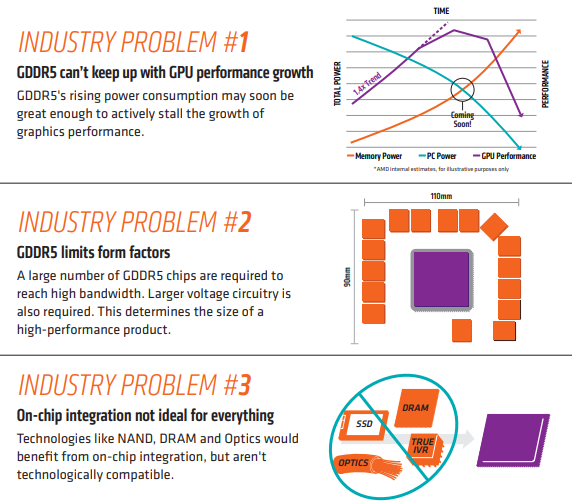 NAND、DRAM和Optics等技术将受益于片上集成技术,而且在技术上并不兼容。HBM是一种低功耗、超宽带通信通道的新型存储芯片。它使用垂直堆叠的存储芯片,通过被称为“硅透”(TSV)的线相互连接,HBM突破了现有的性能限制。 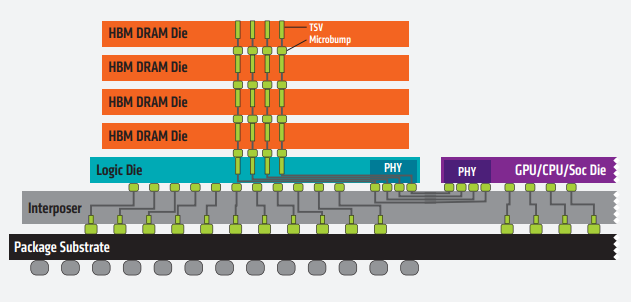 此外,HBM相比GDDR5,减少了通信成本,单位带宽能耗更低,制作工艺更高,所以极大减少晶元空间。  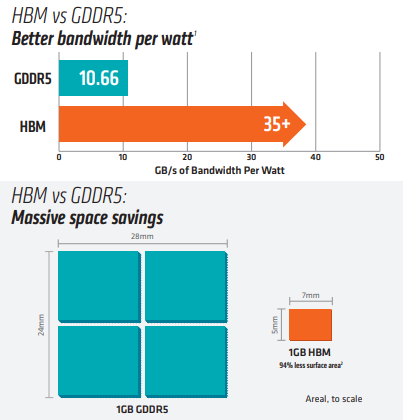 为了提供具有独特功能和优势的各种 DRAM 技术,JEDEC 为 DDR 定义并制定了三大类标准:标准 DDR、移动 DDR 和图形 DDR。标准 DDR 面向服务器、数据中心、网络、笔记本电脑、台式机和消费类应用,支持更大的通道宽度、更高的密度和不同的外形尺寸。移动 DDR 或 LPDDR 面向非常注重规格和功耗的移动和汽车应用,提供更窄的通道宽度和几种低功耗 DRAM 状态。图形 DDR 面向需要极高吞吐量的数据密集型应用。JEDEC 已将 GDDR 和 HBM 定义为两种图形 DDR 标准。SoC 设计人员可以在各种存储器解决方案或标准中挑选,以满足其目标应用的需求。选定的存储器解决方案会影响其 SoC 的性能、功耗和规格要求。 三、算力与性能评估:算力是衡量GPU性能的关键指标之一,表示每秒执行的浮点运算次数。常用的衡量单位是FLOPS(Floating Point Operations Per Second)。除了算力,显存带宽、核心频率和内存带宽等因素也GPU性能。性能评估可以通过基准测试(Benchmarking)来完成,常用的测试套件包括3DMark、SPECviewperf和DeepBench等。这些测试可以衡量GPU在图形渲染、科学计算和机器学习等领域的性能表现。 GPU主要性能指标 GPU的性能主要由以下几个参数构成: 计算能力(吞吐量):通常关心的是32位浮点计算能力。16位浮点训练也开始流行,如果只做预测的话也可以用8位整数。 显存大小:当模型越大,或者训练时的批量越大时,所需要的GPU内存就越多。 显存位宽:位数越大则瞬间所能传输的数据量越大 显存带宽:只有当内存带宽足够时才能充分发挥计算能力。 对于大部分用户来说,只要考虑计算能力就可以了。GPU内存尽量不小于4GB。但如果GPU要同时显示图形界面,那么推荐的内存大小至少为6GB。内存带宽通常相对固定,选择空间较小。 计算能力(吞吐量) 一个非常重要的性能指标就是计算吞吐量,单位为GFLOP/s,算力指标 Giga-FLoating-point OPerations per second 表示每秒的浮点操作数量。 每秒浮点运算量,是衡量GPU硬件计算能力的指标。  例如:现在intel purley platform的旗舰skylake 8180是[email protected],支持AVX512,其理论双精度浮点性能是:28Core2.5GHZ32FLOPs/Cycle=2240GFLPs=2.24TFLOPs 四、功耗管理技术:随着GPU性能的不断提升,功耗管理变得越来越重要。GPU功耗管理技术旨在平衡性能和功耗之间的关系。动态频率调整(Dynamic Frequency Scaling)是一种常见的功耗管理技术,它可以根据工作负载的变化调整核心频率,从而实现节能效果。此外,GPU还采用硬件执行单元的休眠技术(Idle Unit Technology),在计算不需要时关闭部分执行单元以降低功耗。缓存设计和数据预取面理解对于优化应用性能、加速计算任务以及推动科学研究具有重要意义。 DVFS(Dynamic Voltage And Frequency Scaling)动态电压和频率调节,这里主要研究GPU频率动态的调节。 和CPU采用cpufreq框架动态调节频率类似,GPU这块采用了Linux devfreq框架。 Devfreq有四种对频率的管理策略governor: 1、 performance:GPU会固定工作在其支持的最高频率上,以追求最高性能。 2、 powersave:GPU会固定工作在其支持的最低频率上,以追求最低的功耗。 3、 userspace:早期的管理策略,系统将变频策略的决策交给了用户态应用程序,并提供相应的接口供其使用。 4、 ondemand:userspace 是用户态的检测,效率低,而 ondemand 则是一个完全在内核态下工作并且能够以更加细粒度的时间间隔对系统负载情况进行采样分析的 governor 。 Devfreq只提供了实现变频的框架,只是机制,而具体如何决定变频的策略则是各硬件厂商根据其硬件特性来决定的。 Qualcomm的GPU则使用的是他们自己的governor:msm-adreno-tz,他和ondemand有点相似,是在内核态根据GPU的负载来动态决定如何变频的。 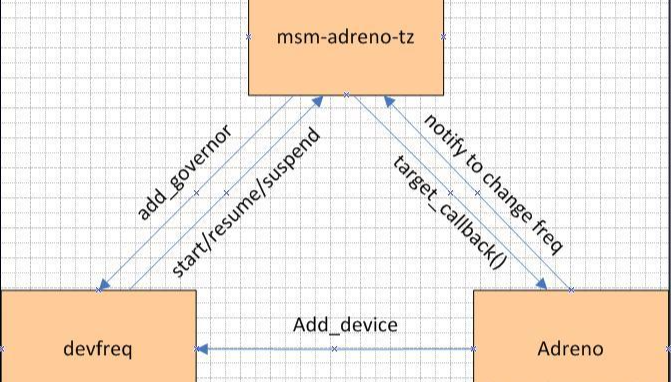 我们来看一下他们的实现机制。 首先在初始化的过程中,msm-adreno-tz先调用devfreq_add_governor(),向devfreq框架中添加一个governor。 随后,Adreno在初始化的过程中调用devfreq_add_device(“msm-adreno-tz”),并选定其使用的governor,它同时像devfreq框架提供了几个回调函数,这些函数在devfreq_dev_profile结构体中: .target =kgsl_devfreq_target;//设置调整后的频率 .get_dev_status= kgsl_devfreq_get_dev_status;//获得GPU的负载 .get_cur_freq= kgsl_devfreq_get_cur_freq;//获得GPU当前的频率值 在匹配完成后,devfreq框架发送DEVFREQ_GOV_START消息到msm-adreno-tz,这样msm-adreno-tz就会注册notifier到Adreno,这样 Adreno就可以使用msm-aderno-tz来动态调整频率了。 在msm-adreno-tz初始化阶段,会向Adreno注册一个回调函数tz_notify(),这样Adreno就可以通过tz_notify来通知msm-adreno-tz动态调整频率了,具体流程是: adreno_dispatcher_work -->kgsl_pwrscale_idle -->queue_work(devfreq_notify_ws) -->do_devfreq_notify(ADRENO_DEVFREQ_NOTIFY_RETIRE) -->tz_notify() -->update_devfreq(devfreq) -->profile->get_dev_status() -->profile.target() adreno_dispatcher_work()相当于是一个分配任务的回调接口,可以理解是个Loop,这样流程就可以串起来了。 msm-adreno-tz动态调整频率使用devfreq框架提供的update_devfreq()函数,该函数通过get_target_freq()回调函数来获得要调整的频率值。在performance中,get_target_freq()返回的是max_freq,在powersave中返回的是min_freq,在我们的msm-adreno-tz中,则会调用profile->get_dev_status()回调函数,从Adreno驱动中获取GPU的负载,并通过一定算法(__secure_tz_entry3??)来计算出频率值,并通过profile->target()回调函数,改变Adreno的频率,至此一个Loop就完成了,接下来就是一直Loop直至系统待机。 高通给的可以手动调节GPU频率的接口为: echo1 > /sys/class/kgsl/kgsl-3d0/force_clk_on echo 10000000 > /sys/class/kgsl/kgsl-3d0/idle_timer echo performance > /sys/class/kgsl/kgsl-3d0/devfreq/governor echo > /sys/class/kgsl/kgsl-3d0/gpucl 具体理解为是: 1、echo 1 > force_clk_on是设置KGSL_PWRFLAGS_CLK_ON这个power_flags。使用echo freq > gpuclk时,是通过kgsl_pwrctrl_pwrlevel_change设置频率,它会判断KGSL_PWRFLAGS_CLK_ON这个power_flags,如果没有这个flag,可能就不会真正的设置频率,不过我测试了一下,即使不用这个命令,在大多数情况下也是可以工作的。也就是说,它会强制使得接下来第@4步的设置生效。 2、echo 10000000 > idle_timer,,设置interval_timeout,默认值是80ms。 当系统启动的时候,会初始化一个idle_timer-->kgsl_timer,这个timer会执行kgsl_idle_check()用于检测GPU是否处于idle状态,如果是,则会调用: kgsl_pwrctrl_sleep() -->devfreq_suspend_device() -->governor->event_handler(DEVFREQ_GOV_SUSPEND) -->msm-adreno-tz/performance,stop 接下来如果有系统调用至KGSL,则会唤醒Adreno: kgsl_pwrscale_wake() --> devfreq_resume_device() -->governor->event_handler(DEVFREQ_GOV_RESUME) -->msm-adreno-tz/performance,start 而在governor restart的过程中,会重新初始化GPU所对应的频率,这样即使我们设置了我们想要的频率,最后也很快就被冲掉了,所以要把该interval_timeout设置为很大。 3、echo performance > devfreq/governor, 这时devfreq会为Adreno重新选择governor,也就是performance。这时它会使用GPU所支持的最大频率,而不考虑系统的负载。 默认的msm-adreno-tz机制会不停的动态更新频率,即使我们设置过频率也会被覆盖掉,这就是为什么直接设置频率无效的原因。 而如果改成performance机制,这样它会使得Adreno动态的调整机制无效,我们的设置才会生效。 4、echo freq > gpuclk,简单的设置GPU的频率,一般是在200000 000, 320 000 000和450 000 000之间,如果不对,就会就近选择这三者之一。 在前面设置做铺垫的情况下,idle_interval被设置成了很大,这样边不会suspend、resume,我们设置的gpuclk才不会被重新设置,并且do_devfreq_notify()也不起了作用,所以可以用我们设置的频率进行功耗及跑分测试了。 在本文中,我们深入探索了GPU硬件技术的核心要点,包括硬件架构、显存技术、算力与性能评估以及功耗管理。通过深入理解这些关键概念,开发者和研究人员可以更好地利用GPU的潜力,推动计算机图形渲染、机器学习、科学计算等领域的创新和发展。 |
【本文地址】