| 最强伴奏与人声分离工具:UVR5 (Ultimate Vocal Remover GUI v5.5.0) | 您所在的位置:网站首页 › 明天你好伴奏消音 › 最强伴奏与人声分离工具:UVR5 (Ultimate Vocal Remover GUI v5.5.0) |
最强伴奏与人声分离工具:UVR5 (Ultimate Vocal Remover GUI v5.5.0)
|
UVR5 (Ultimate Vocal Remover GUI v5.5.0) 在页面最下面有介绍,以下内容还是之前的5.4.0的文案,请注意。 UVR5 (Ultimate Vocal Remover GUI v5.4.0) 是一款功能强大的伴奏制作/人声提取工具,比RX9,RipX和SpectraLayers 9都要好,UVR5提取出来的伴奏已经无限接近原版立体声。
本程序使用了最先进的音源分离模型,以去除音频文件中的人声。UVR 的核心开发人员训练了这个软件包中提供的所有模型(除了 Demucs 的辅助模型)。 核心开发者 Anjok07 aufr33 安装 UVR5 (Ultimate Vocal Remover GUI v5.4.0)的安装,需要一些先决条件,有一些是必要,有一些是辅助。 请注意: 该安装程序适用于 Windows 10 或更高版本。 不保证在 Windows 7 或更低版本时的应用功能。 不保证英特尔奔腾和赛扬 CPU 的应用功能。安装NVIDIA显卡的CUDA驱动 UVR5对伴奏与人声分离,严重依赖NVIDIA显卡,目前主流的就是GeForce GTX10、RTX20、RTX 30 系列,通过CUDA并行计算技术,以NVIDIA的图形处理器 (GPU) 的处理能力,加速应用程序。因此,你必须要有一块GeForce显卡,并且在安装显卡驱动的时候,安装了CUDA驱动,为了保险起见,您可以再单独下载安装一遍NVIDIA的CUDA驱动。 检查显卡的CUDA Toolkit版本 在Windows里的“运行”,输入cmd,在弹出的命令行界面输入:nvidia-smi,回车,得到下图表格,通过表格右上角的CUDA Version来确定你应该下载的CUDA Toolkit驱动版本
NVIDIA的CUDA驱动下载页面: CUDA Toolkit Archive: https://developer.nvidia.com/cuda-toolkit-archive 安装CUDA Toolkit驱动: 在安装选项选择“自定义”,然后全选,这样不容易落掉内容:
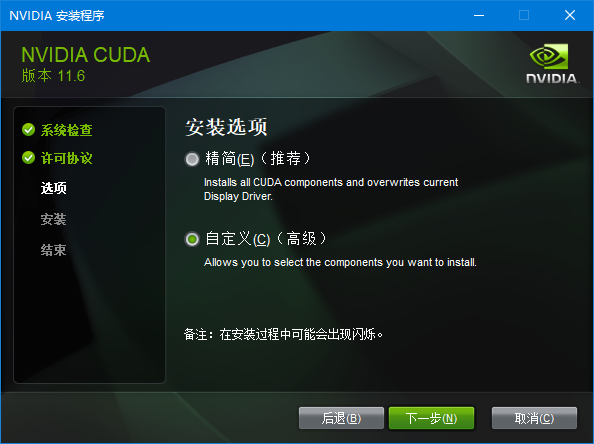
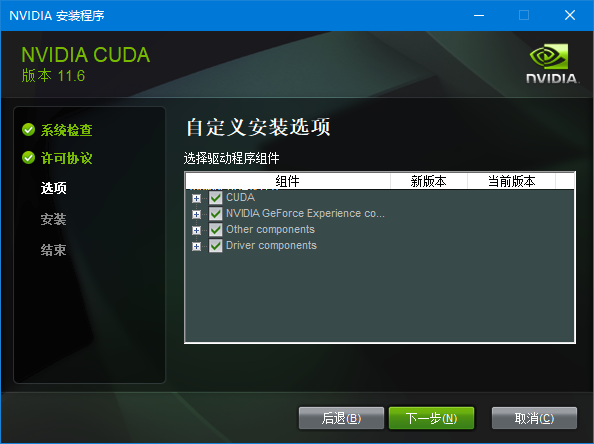
我的电脑在安装过过程中出了一点问题,它提示我没有安装微软的Visual Studio,可以强制跳过继续,但是我还是安装了一下Visual Studio:
Visual Studio下载页面,我安装的是第一个版本Visual Studio Community 2022。只安装环境,不安装应用,大概是1.09GB: https://visualstudio.microsoft.com/zh-hans 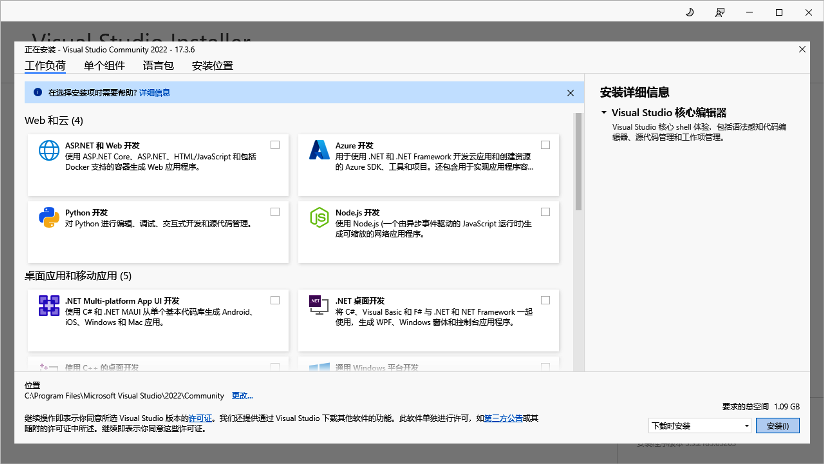
Visual Studio安装完毕,CUDA安装就很顺利了: 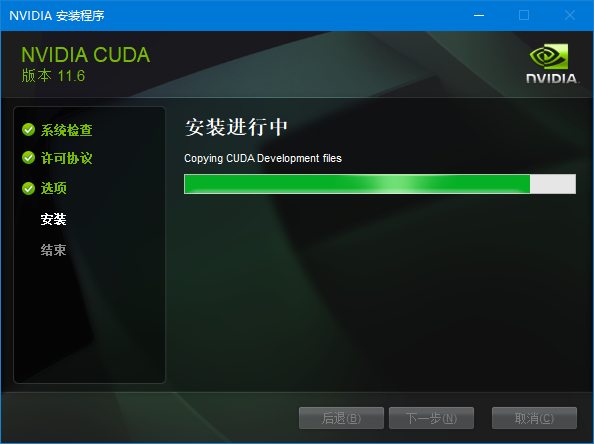
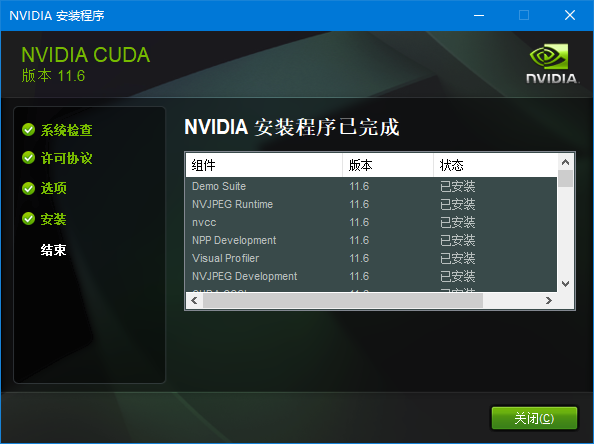
安装ffmpeg 为了在分离音频的时候,能够支持更多的音频格式,我们还需额外在Windows系统里面安装ffmpeg,其实也不是安装,而是指定路径。 先把下载回来的ffmpeg解压,放在一个适当的文件夹里,我选择的是D:\Program Files\ffmpeg-5.1.2-full_build 指定给Windows的路径是ffmpeg里面一层,最终是这样的: D:\Program Files\ffmpeg-5.1.2-full_build\bin
下载页面 FFmpeg Builds binaries for Windows ffmpeg-release-full.7zrelease builds latest release version: 5.1.2 2022-09-26https://www.gyan.dev/ffmpeg/builds
操作方法: 1. 在Win10开始菜单按钮上鼠标右键单击,弹出菜单选择“系统”
2. 在“系统”界面,选择右边的“高级系统设置”
3. 在对话框中,点击右下角的“环境变量”按钮
4. 选择上面用户变量的Path一行,然后点击下面的“编辑”按钮
5. 点“新建”按钮,把刚才的“D:\Program Files\ffmpeg-5.1.2-full_build\bin”路径复制进去,然后确定。
6. 重启电脑,再验证刚才两项内容是否已经运行。 检查CUDA核心有没有输出: 在Windows里的“运行”,输入cmd,在弹出的命令行界面输入:nvcc -V,回车; 检查FFmpeg: 在Windows里的“运行”,输入cmd,在弹出的命令行界面输入:ffmpeg,回车;如果刚才两项内容分别得到下面图片中的类似内容,说明安装成功:
安装UVR5 (Ultimate Vocal Remover GUI v5.4.0) 双击安装文件UVR_v5.4.0_setup.exe,需要安全同意。如果有Windows的安全筛选,就选择更多,仍坚持运行。 UVR5所占硬盘空间不小,再加上后面要下载的现成的算法文件,将近10GB,所以我安装在了D盘。 当一切安装好之后,第一次双击运行没有动静。再一次双击运行,才可以。相关算法文件可以在软件的设置页面的Download Center下载。(国内用户可能连不上服务器,为了方便,我下载了一些,一起分享了) 请把我给准备的文件,复制到Main_Models文件夹里面,我电脑上的路径是(因人而异): D:\Program Files\Ultimate Vocal Remover\models\Main_Models
应用手册 一般选项
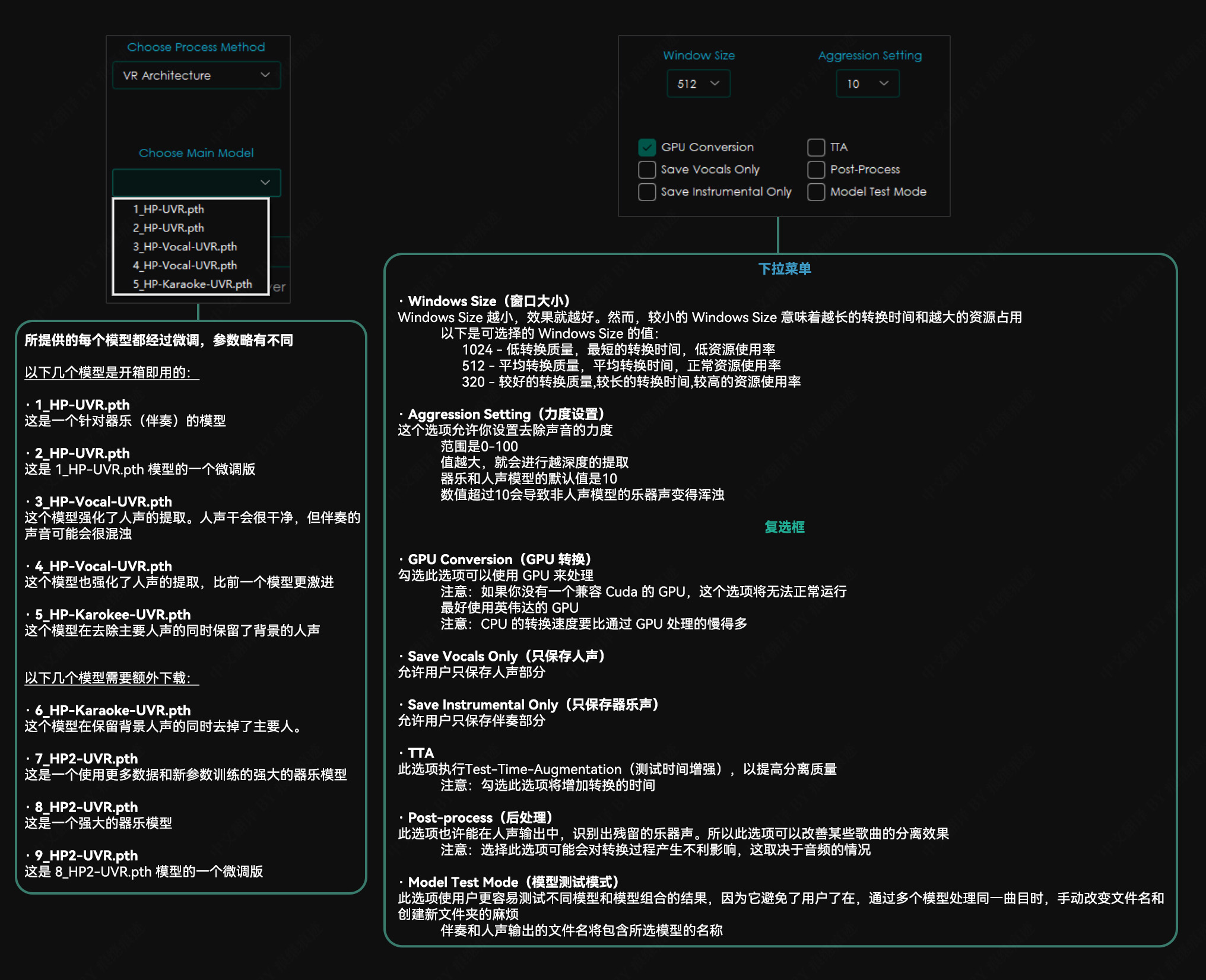
VR 架构选项
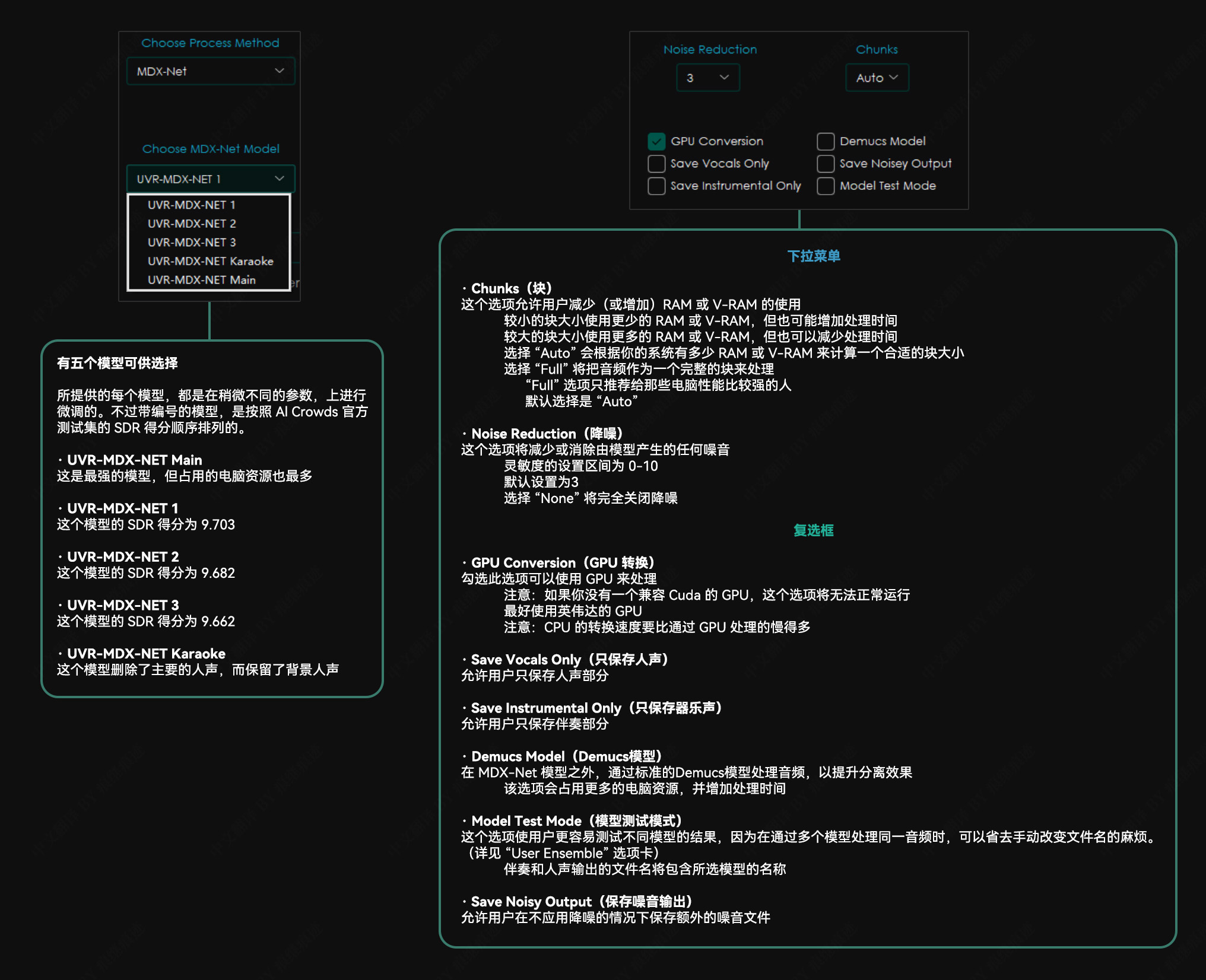
MDX-Net 选项
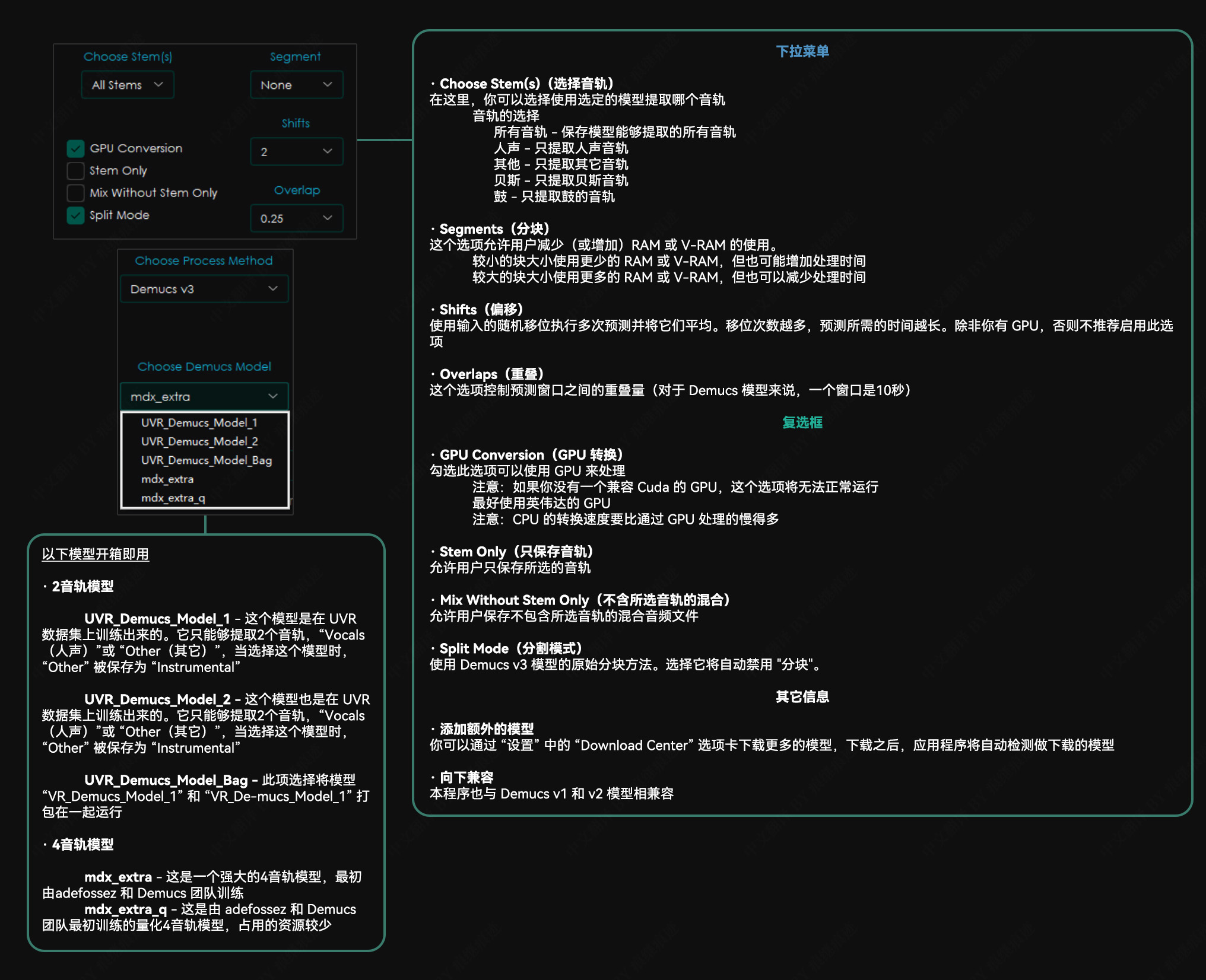
Demucs v3 选项
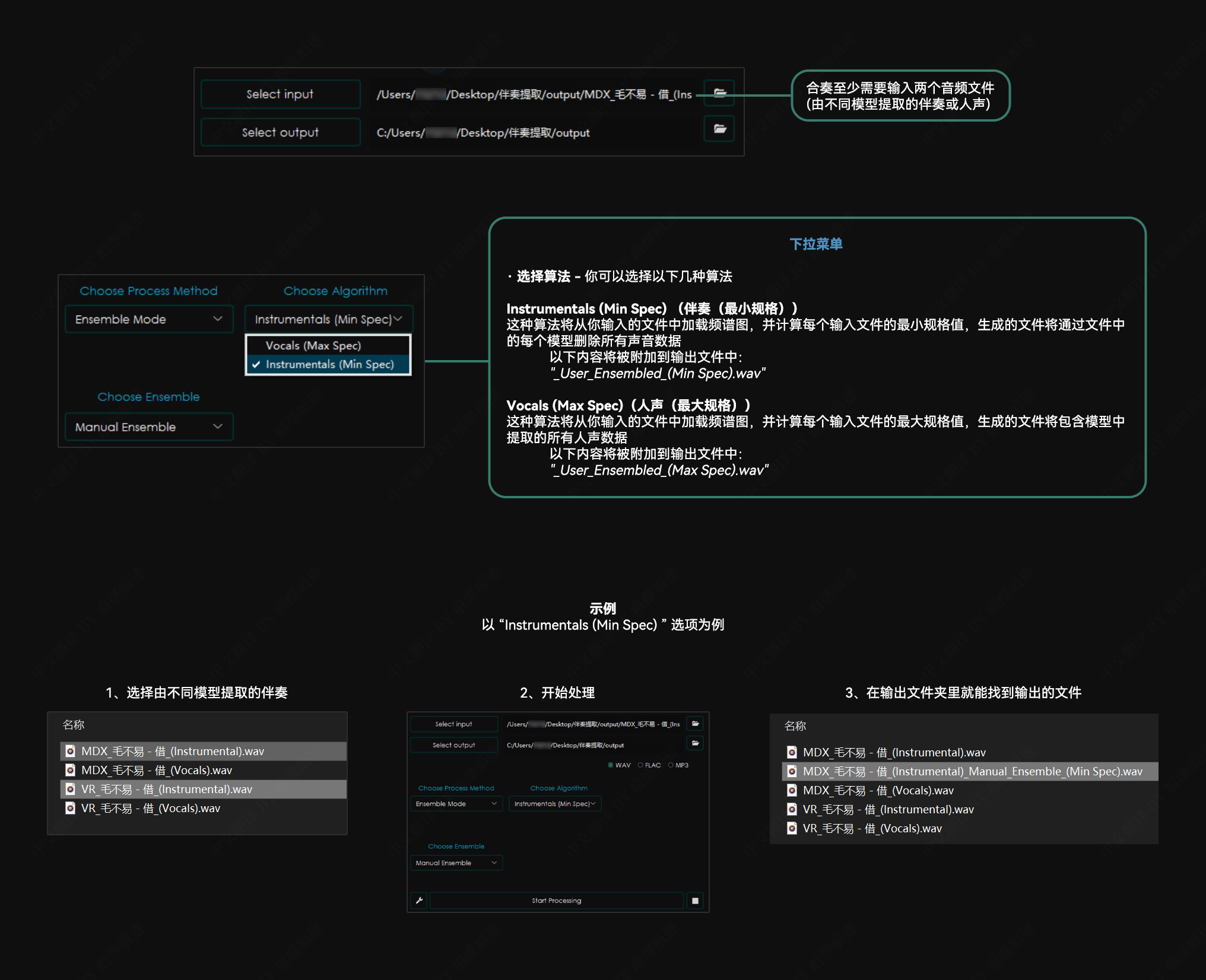
合奏选项
手动合奏
其他应用说明 建议使用至少有 8GB 显存的 nVidia GPU。该应用程序只兼容 64 位平台。该应用程序依赖于 Sox – Sound Exchange 的降噪。该应用程序依赖于 FFmpeg 来处理非 wav 格式的音频文件。应用程序将在关闭时自动记住你的设置。转换时间将在很大程度上取决于你的硬件。程序所采用的模型是计算密集型的,请谨慎行事,并在程序运行时时刻关注你的电脑,确保它不会过热。我们不对任何硬件损坏负责。 故障排除 若没有正确安装并配置 FFmpeg,并试图转换一个非 WAV 文件,本程序将抛出一个错误。内存分配错误通常可以通过降低“Chunk Size” (分块大小)来解决。
These bundles contain the UVR interface, Python, PyTorch, and other dependencies needed to run the application effectively. No prerequisites are required. Windows InstallationPlease Note: This installer is intended for those running Windows 10 or higher. Application functionality for systems running Windows 7 or lower is not guaranteed. Application functionality for Intel Pentium & Celeron CPUs systems is not guaranteed. You must install UVR to the main C:\ drive. Installing UVR to a secondary drive will cause instability.Download the UVR installer for Windows via the link below. Update Package instructions for those who have UVR already installed: If you already have UVR installed you can install this package over it or download it straight from the application. (如果你已经安装了5.4.0版本,那么直接下载5.5.0版本的安装程序“UVR_v5.5.0_setup.exe”,双击安装就替换旧版本自然升级了。或者在就程序5.4.0里面的Settings Guide) Other Application Notes Nvidia RTX 1060 6GB is the minimum requirement for GPU conversions. Nvidia GPUs with at least 8GBs of V-RAM are recommended. AMD Radeon GPUs are not supported at this time. This application is only compatible with 64-bit platforms. This application relies on the Rubber Band library for the Time-Stretch and Pitch-Shift options. This application relies on FFmpeg to process non-wav audio files. The application will automatically remember your settings when closed. Conversion times will significantly depend on your hardware. These models are computationally intensive. Change Log Fixes & Changes: The progress bar is now fully synced up with every process in the application. Drag-n-drop feature should now work every time. Users can now drop large batches of files and directories as inputs. When directoriesare dropped, the application will search for any file with an audioextension and add it to the list of inputs. Fixed low resolution icon. Added the ability to download models manually if the application can’t connect to the internet on it’s own. Various bug fixes for the Download Center. Various design changes. Performance: Model load times are faster. Importing/exporting audio files is faster. New Options: “Select Saved Settings” option – Allows the user to save the current settings of the whole application. You can also load a saved setting or reset them to the default. “Right-click” menu – Allows for quick access to important options. “Help Hints” option – When enabled, users can hover over options to see pop-up text that describes that option. The right-clicking option also allows copying the “Help Hint” text. Secondary Model Mode – This option is an expanded version of the “Demucs Model” option that was only available to MDX-Net. Except now, this option is available in all three AI Networks and for any stem. Any model can now be Secondary, and the user can choose the amount of influence it has on the final result. Robust caching for ensemble mode, allowing for much faster processing times. Clicking the “Input” field will pop-up a new window that allows the user to go through all of the selected audio inputs. Within this menu, users can: Remove inputs. Verify inputs. Create samples of selected inputs. “Sample Mode” option – Allows the user to process only part of a track to sample settings or a model without running a full conversion. The number in the parentheses is the current number of seconds the generated sample will be. You can choose the number of seconds to extract from the track in the “Additional Settings” menu. VR Architecture: Ability to toggle “High-End Processing.” Support for the latest VR architecture Crop Size and Batch Size are specifically for models using the latest architecture only. MDX-NET: “Denoise Output” option – When enabled, this option results in cleaner results, but the processing time will be longer. This option has replaced Noise Reduction. “Spectral Inversion” option – This option uses spectral inversion techniques for a cleaner secondary stem result. This option may slow down the audio export process. Secondary stem now has the same frequency cut-off as the main stem. Demucs: Demucs v4 models are now supported, including the 6 stem model. Ability to combine remaining stems instead of inverting selected stem with the mixture only when a user does not select “All Stems”. A “Pre-process” model that allows the user to run an inference through a robust vocal or instrumental model and separate the remaining stems from its generated instrumental mix. This option can significantly reduce vocal bleed in other Demucs-generated non-vocal stems. The Pre-process model is intended for Demucs separations for all stems except vocals and instrumentals. Ensemble Mode: Ensemble Mode has been extended to include the following: “Averaging” is a new algorithm that averages the final results. Unlimited models in the ensemble. Ability to save different ensembles. Ability to ensemble outputs for all individual stem types. Ability to choose unique ensemble algorithms. Ability to ensemble all 4 Demucs stems at once.
本站帮您消音制作伴奏 本站发布了伴奏与人声分离工具:UVR5,但是有一些朋友只想做一首歌的伴奏,下载、安装、调试费时费力,或者有的朋友的办公电脑硬件水平不够理想,这样您可以留言或私信给我,我帮您将人声和伴奏分离  本站帮您消音制作伴奏
本站帮您消音制作伴奏
下载权限查看 ¥ 免费下载 评论并刷新后下载 登录后下载 查看演示 {{attr.name}}: 您当前的等级为 登录后免费下载登录 小黑屋反思中,不准下载! 评论后刷新页面下载评论 支付¥以后下载 请先登录 您今天的下载次数(次)用完了,请明天再来 支付积分以后下载立即支付 支付以后下载立即支付 您当前的用户组不允许下载升级会员 您已获得下载权限 您可以每天下载资源次,今日剩余次 |
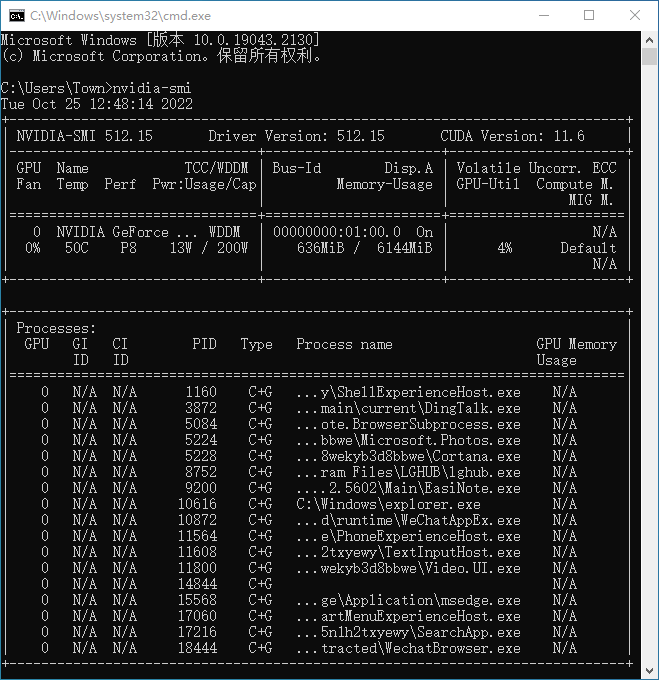 通过表格右上角的CUDA Version来确定你应该下载的CUDA Toolkit驱动版本
通过表格右上角的CUDA Version来确定你应该下载的CUDA Toolkit驱动版本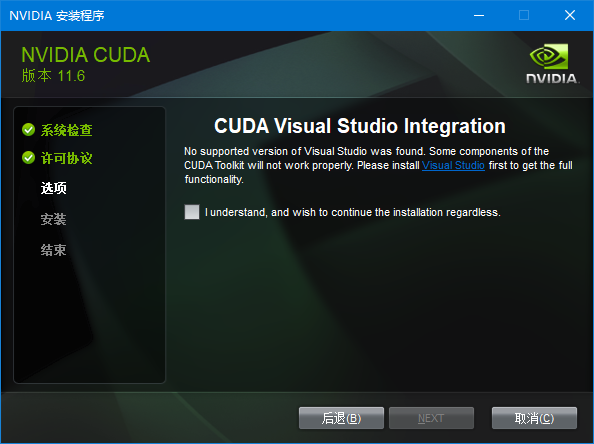
 选择“系统”
选择“系统” 选择“高级系统设置”
选择“高级系统设置” 点击“环境变量”按钮
点击“环境变量”按钮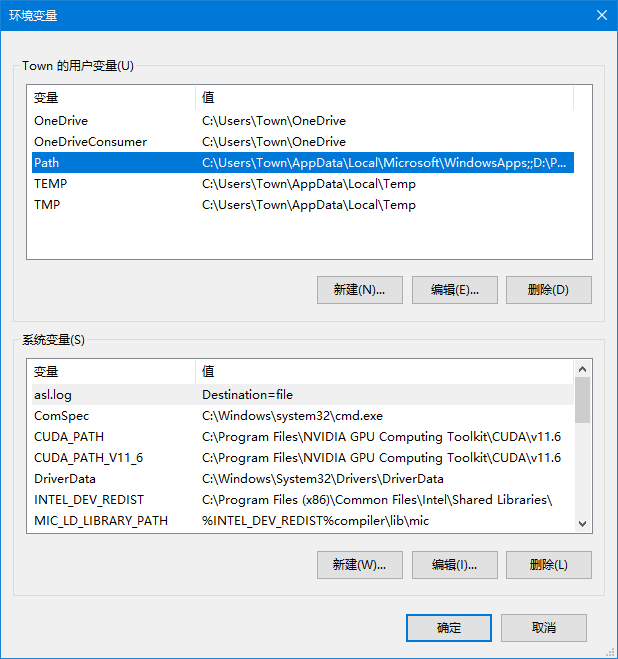 “编辑”
“编辑”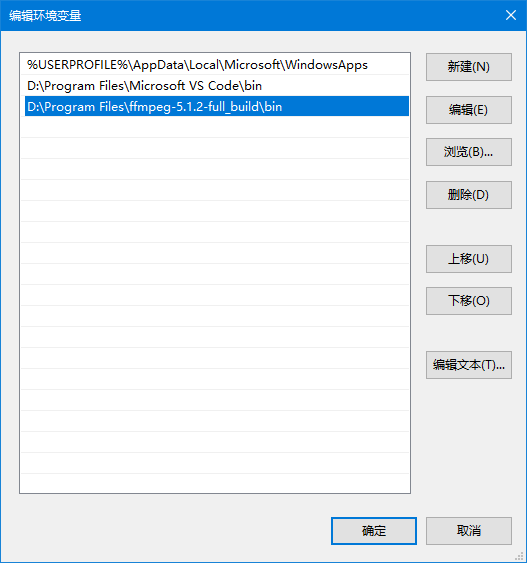 指定ffmpeg路径
指定ffmpeg路径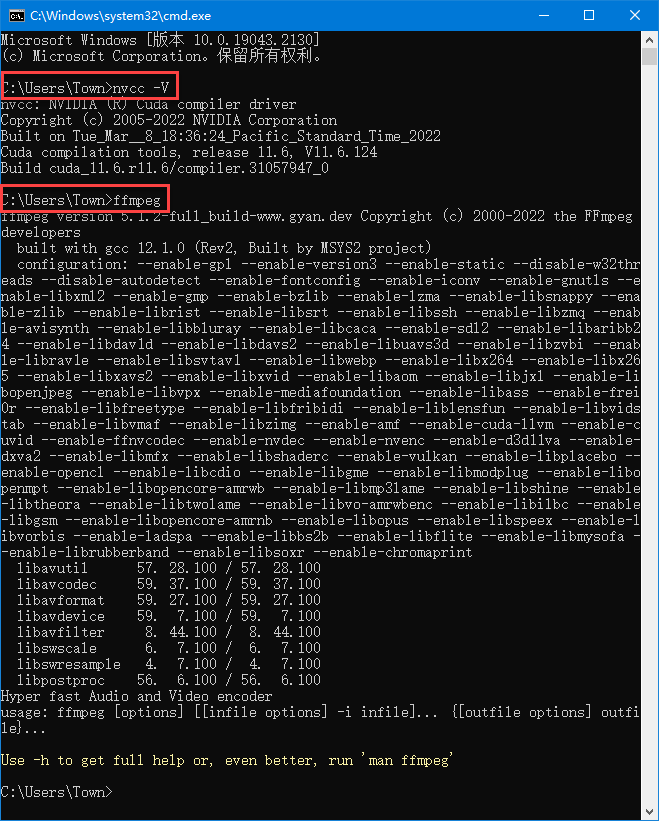 验证CUDA驱动和ffmpeg
验证CUDA驱动和ffmpeg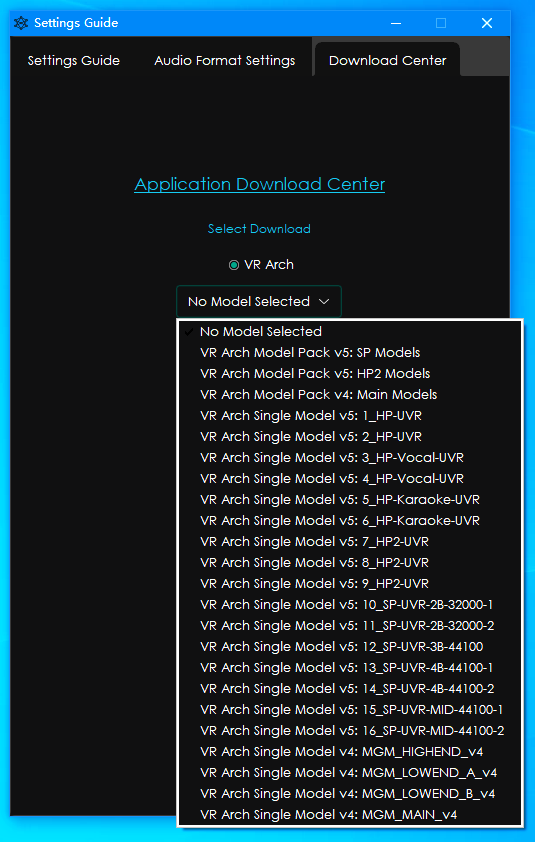 额外的模型和程序补丁可以通过程序内的“Settings”菜单下载
额外的模型和程序补丁可以通过程序内的“Settings”菜单下载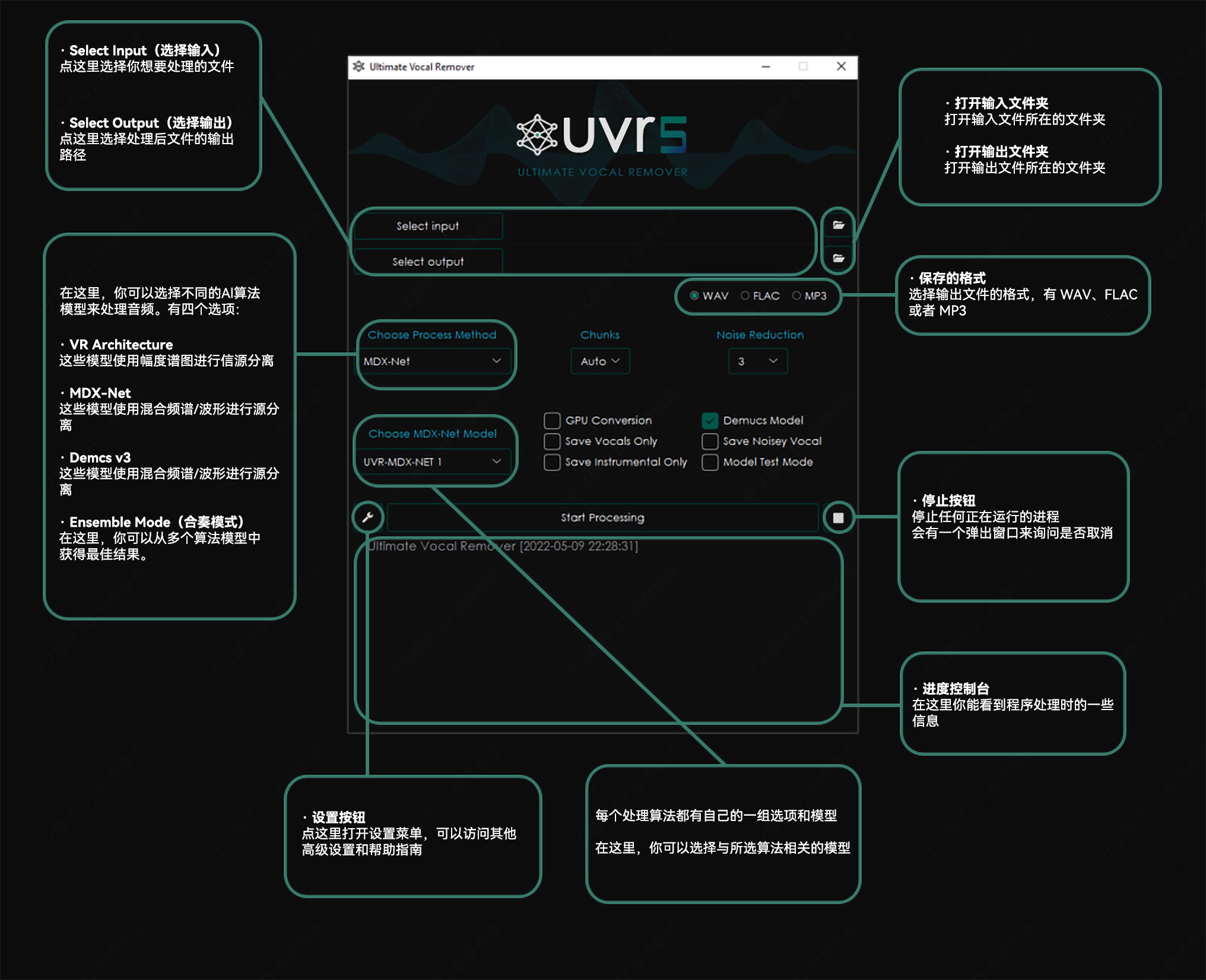


【本文地址】