| 第16章Stata面板数据分析 | 您所在的位置:网站首页 › 时间序列数据和截面数据的例子 › 第16章Stata面板数据分析 |
第16章Stata面板数据分析
|
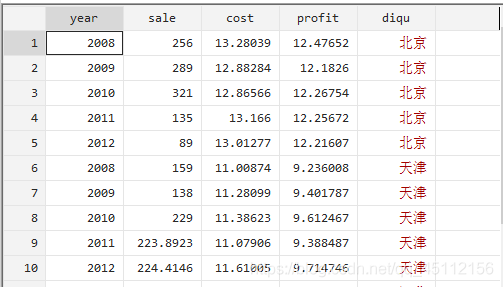
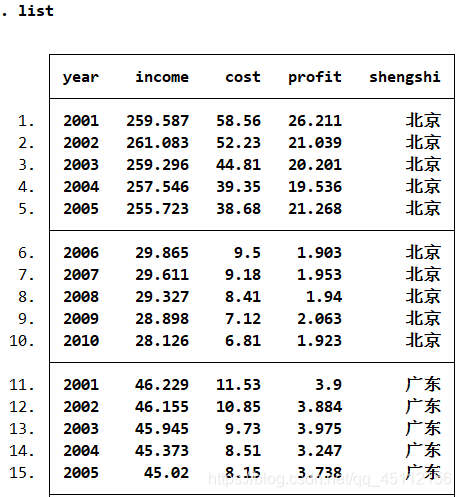
目录 16.1短面板数据分析 案例延伸 延伸:关于模型的选择问题 16.2长面板数据 案例延伸 延伸:进行随即系数模型回归分析 面板数据(Panel Data)又被称为平行数据,指的是对某变量在一定时间内持续跟踪观测的结果。面板数据兼具了横截面数据和时间序列数据的特点,即有横截面维度(在同一时间段内有多个观测样本),又有时间序列维度(同一样本在多个时间段内被观测到)。面板数据通常样本数量相对较多,也可以有效解决遗漏变量的问题,还可以提供更多样本动态行为的信息,具有横截面数据和时间序列数据无可比拟的优势。根据横截面为度和时间序列维度相对长度的大小,面板数据被区分为长面板数据和短面板数据。 16.1短面板数据分析短面板数据其主要特征是横截面为度比较大而时间维度相对较小,或者说,同一期间内被观测的个体数量较多而被观测的期间较少。段面板数据分析方法包括直接最小二乘回归分析、固定效应回归分析、随机效应回归分析、组间估计量回归分析等多种。 案例(16.1)A公司是一家销售饮料的连锁公司,下面是销售公司在各省市连锁店2008-2012年的橡树销售数据(包括销售收入、小小费用以及创造利润等数据)。试用短面板数据回归分析方法深入研究销售量和据消费用对制造利润的影响关系。变量包括年份、销售收入、促销费用、创造利润、地区。
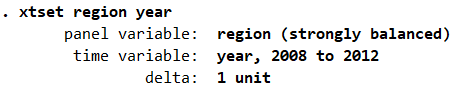
可以看出这是一个平衡的面板数据。 xtdes #本命令旨在观测变慢数据的结构,考察面板数据特征,为后续分析做好必要准备
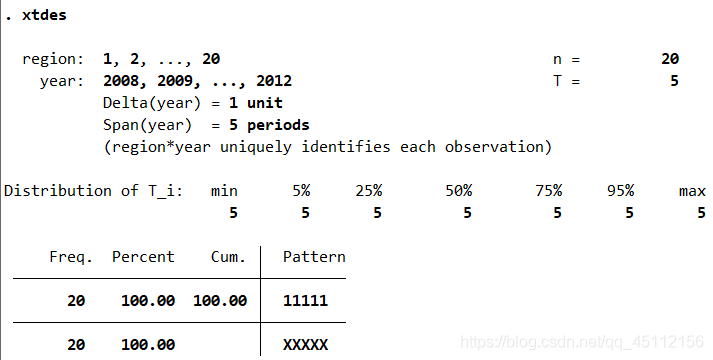
从上图可以看出该面板数据的横截面维度region为1~20共20个取值,时间序列维度year为2008-2012共5个取值,属于短面板数据,而且观测样本在时间上的分布也非常的均匀。 xtsum #本命令旨在现实面板数据组内、组件以及整体的统计指标
上图是sale变量组内、组间以及整体的分布频率的结果。 xtline sale #本命令旨在对每个个体现实“sale”变量的时间序列图 xtline cost xtline profit
上图的解析就不多说了。可从上述分析结果我们可以得到最小二乘模型的回归方程是: profit = 0.0041186*sale+0.862813*cost-0.4981994 得到的结论是该单位创造利润情况与销售量和促销费用等都是显著呈正向变化的。 reg profit sale cost,vce(cluster region) #本命令的含义是以sale、cost为自变量,profit为因变量,并且使用以 region 为聚类变量的聚类稳健标准差,进行最小二乘回归分析。
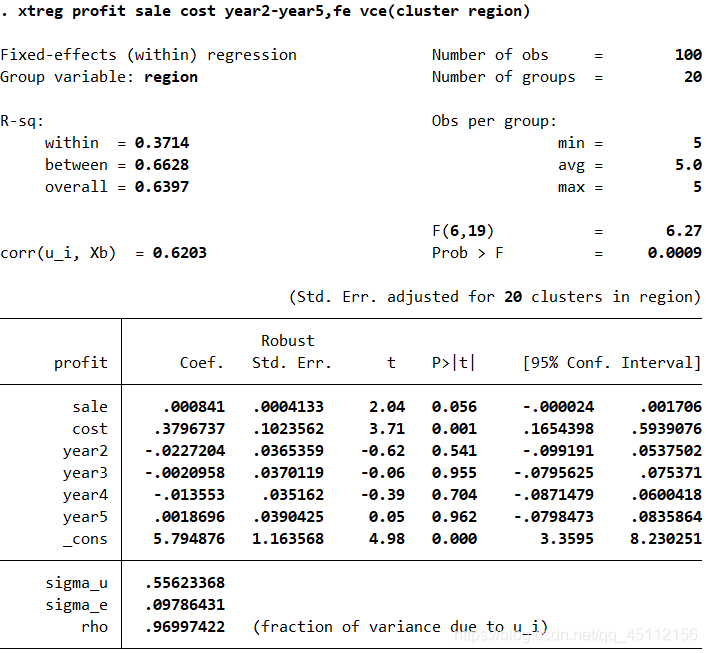
从图中可以看到共有20组,每组5个,共有100个样本参与了固定效应回归分析。模型的F值是10.92,显著性P值为0.0007,模型是非常显著的。模型组内R方是0.3637(within=0.3637),说明单位内解释的变化比例是36.37%。模型组间R方是0.6619(between=0.6619),说明单位间解释的变化比例是66.19%。模型总体R方是0.3697(ovverall=0.6397)说明总的解释变化比例是63.79%。模型的解释能力还是可以接受的。观察模型中各个变量系数的显著性P值,可以发现是比较显著的。此外,图中最后一行,rho=0.97094045,说明复合扰动项的方差主要来自个体效应而不是时间效应的变动,这一点在后面的分析中也可以得到验证。 xtreg profit sale cost ,fe #本命令的含义是以profit为因变量,以sale、cost为自变量进行固定效应回归分析。
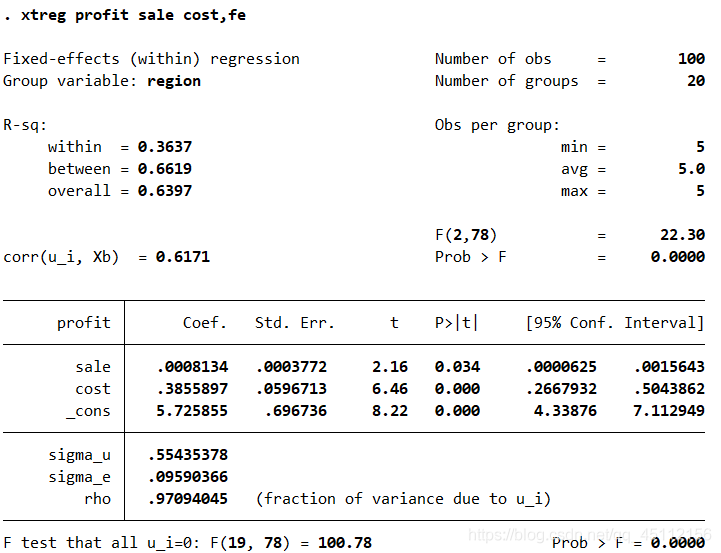
本结果相对于使用以region为聚类变量的聚类稳健标准差进行固定效应回归分析的结果在变量系数显著性上有所提高。此外,在图16.16的最下面一样可以看到“(F test that all u_i=0 : F(19,78) Prob > F = 0.0000)” 显著拒绝了所有各个样本没有自己的截距项的原假设,所以我们可以初步认为每个个体用于与众不同的截距项,也就是说固定效应模型在一定程度上优于普通最小二乘回归模型,这一点也在后续的深入分析中得到了验证。 estimates store fe #本命令的含义是存储固定效应回归分析的估计结果。
从上图我们可以看出,全部year虚拟变量的显著性P值都是远大于0.05的,所以我们可以初步认为模型中不包含时间效应。值得说明的是,在构建双向固定效应模型时并没有把year1列入进去,这是因为year1被视为基期,也就是模型中的常数项。 test year2 year3 year4 year5 #本命令的含义是在上步回归的基础上,通过测试各虚拟变量的系数联合显著性来检验是否应该在模型中纳入时间效应。
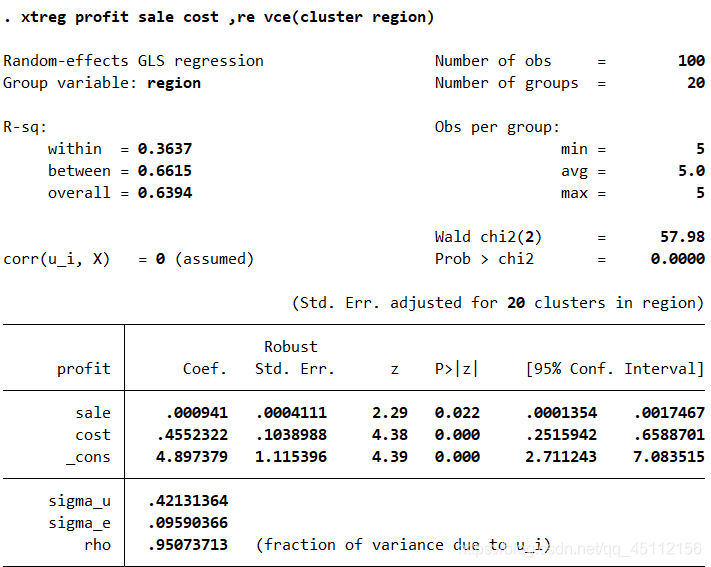
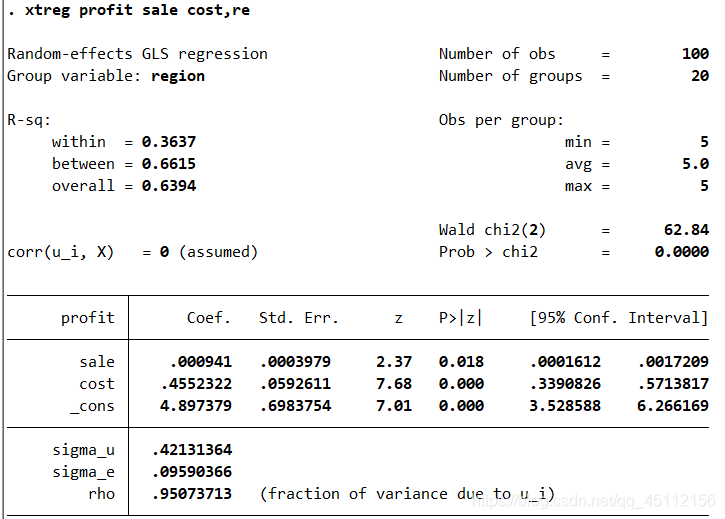
可以看你出,各变量系数的联合显著性是非常差的,接受了没有时间效应的初步假设,所以我们进一步验证了模型中不必包含时间效应的结论。 xtreg profit sale cost,re vce(cluster region) #本命令的含义是以profit为因变量,以sale、cost为自变量,并且以region为聚类变量的聚类稳健标准差,进行随机效应回归分析。
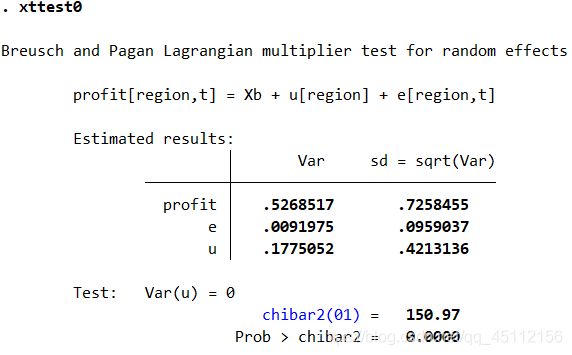
可以看到,随机效应回归分析的结果与固定效应回归分析的结果大同小异,只是部分变量的显著性水平得到了进一步提高。 xttest0 #本命令的含义是在上部回归的基础上,进行假设检验来判断随机效应模型是否优于最小二乘回归模型。
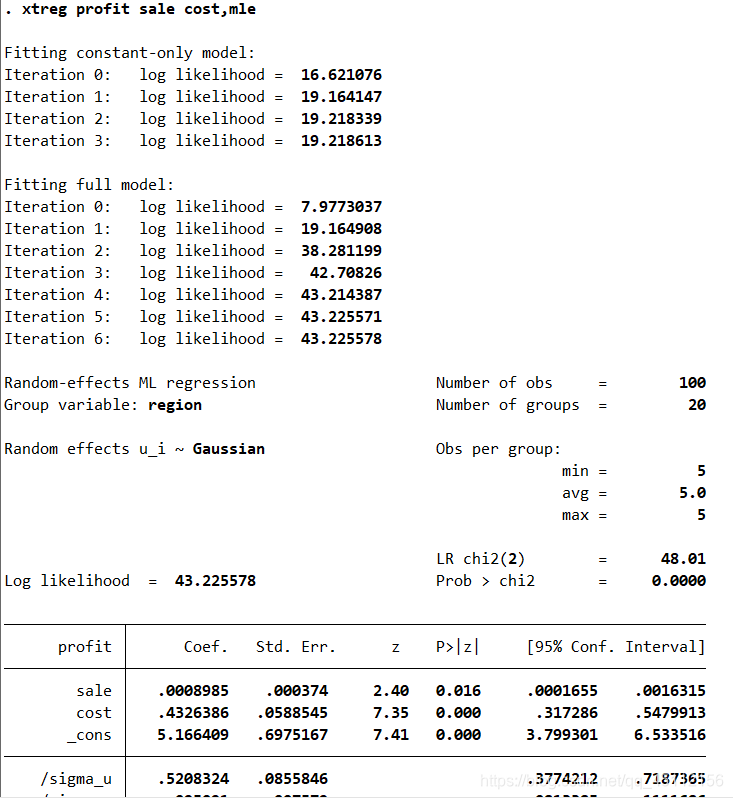
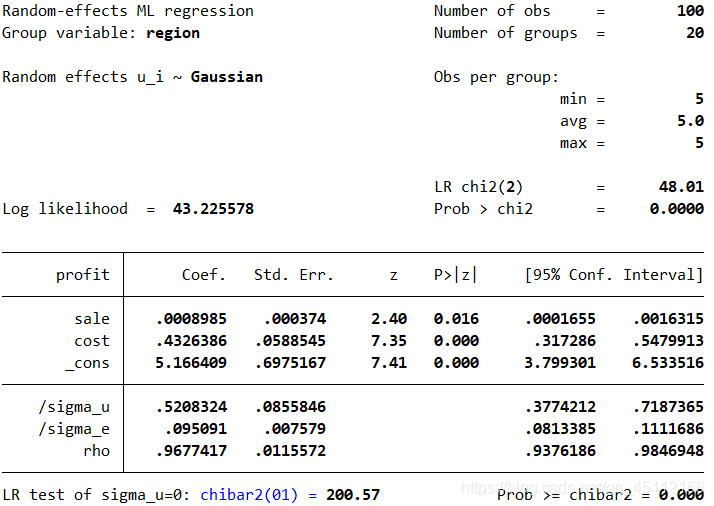
建设检验非常显著的拒绝链不存在个体随机效应的原假设,也就是说,随机效应模型是在一定程度上优于普通最小二乘回归分析模型的。 xtreg profit sale cost,mle #本命令的含义是profit为因变量,以sale、cost为自变量并使用最大似然估计方法,进行随机效应回归分析。
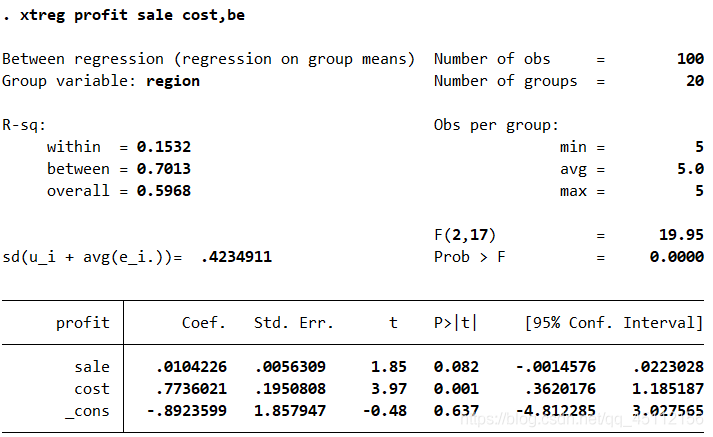
从上图可以看出,使用最大似然估计方法的随机效应回归分析的结果与使用以“region”为聚类变量的聚类稳健标准差的随机效应回归分析的结果大同小异,只是部分变量的显著性水平得到了进一步的提高。 xtreg profit sale cost,be #本命令的含义是以profit为因变量,以sale、cost为自变量并使用组间估计量,进行组间估计量回归分析。
可以看出,使用组间估计量进行回归分析的结果比较固定效应模型、随机效应模型在模型解释能力以及变量的显著性上都有所降低。 案例延伸 延伸:关于模型的选择问题在前面的分析过程中,我们使用各种分析方法对本节涉及的案例进行了详细具体的分析。读者们看到众多的分析方法时可能会有眼花缭乱的感觉,那么我们最终应该选择哪种分析方法来构建模型呢?答案当然是具体问题具体分析,然而我们也有统计方法和统计经验作为决策参考。例如,在本例中,已经证明了固定效应模型和随机效应模型都要浩宇普通最小二乘回归模型。而对于组间估计量模型来说,他通常用于数据质量不好的时候,而且会损失较多的信息,所以很多时候我们仅仅将其作为一种对照的估计方法。那么剩下的问题就是选择固定效应模型还是随机效应模型的问题。在前面的基础下,操作命令如下。 xtreg profit sale cost ,re #本命令的含义是以profit为因变量,cost、sale为自变量进行随机效应回归分析
豪斯曼检验的原假设是使用随机效应模型。上图显示的显著性P值(Prob>chi2=0.0061)远远小于5%,所以我们应该拒绝初始假设,认为使用固定效应模型更为合理的。综上所述,我们应该构建固定效应模型来描述变量之间的关系。 16.2长面板数据长面板数据是面板数据的一种,其主要特征是时间维度比较大而横截面维度相对较小的,或者说,同一期间内被观测的期间较多而被观测的个体数量少。长面板数据分析相对而言更加关注扰动项相关的具体形式,一般使用可行广义最小二乘法进行估计。这又分为两种情形:一是进解决组内自相关的可广义最小二乘估计:李毅中是同时处理组内自相关与组间同期相关的可行广义最小二乘估计。 案例(16.2)B公司是一家保险公司,各省市连锁店2001-2010年的相关经营数据包括保费收入、赔偿支出以及创造利润等。试用多种长面板数据回归分析方法深入研究保费收入、赔偿支出对创造利润的影响关系。
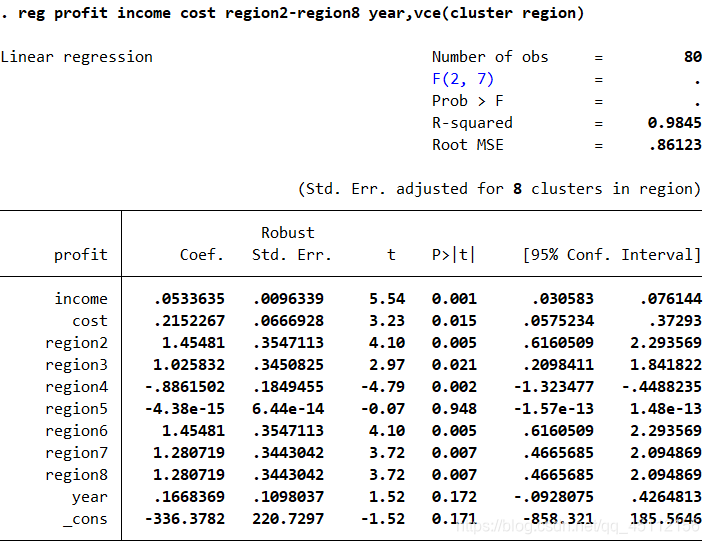
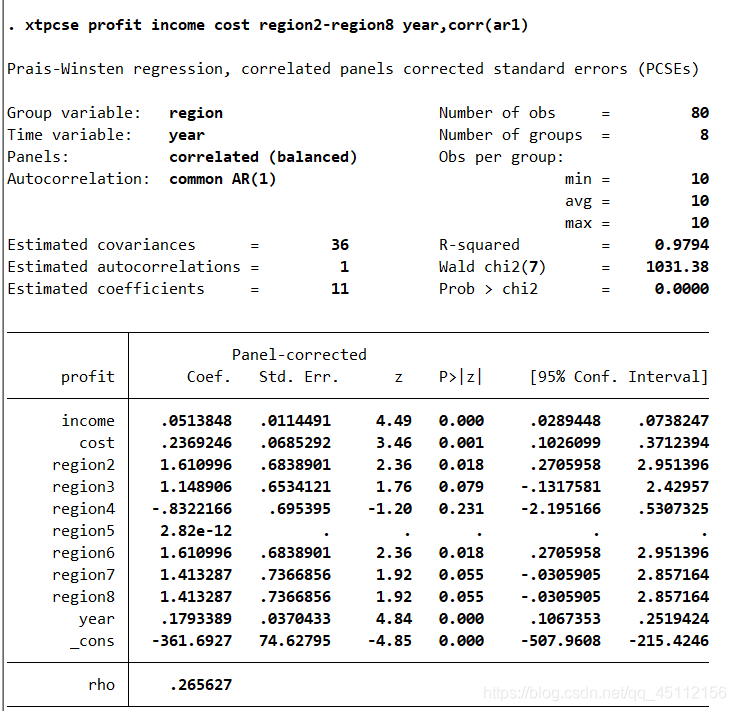
上述命令的分析不再过多赘述。 xtpcse profit income cost region2-region8 year ,corr(ar1) #本命令的含义是在仅考虑存在组内自相关,并且各组的子回归系数相同的情形下,以profit为因变量,以income、cost以及生成的各个地区虚拟变量为自变量,进行可行广义最小二乘回归分析。 estimates store ar1
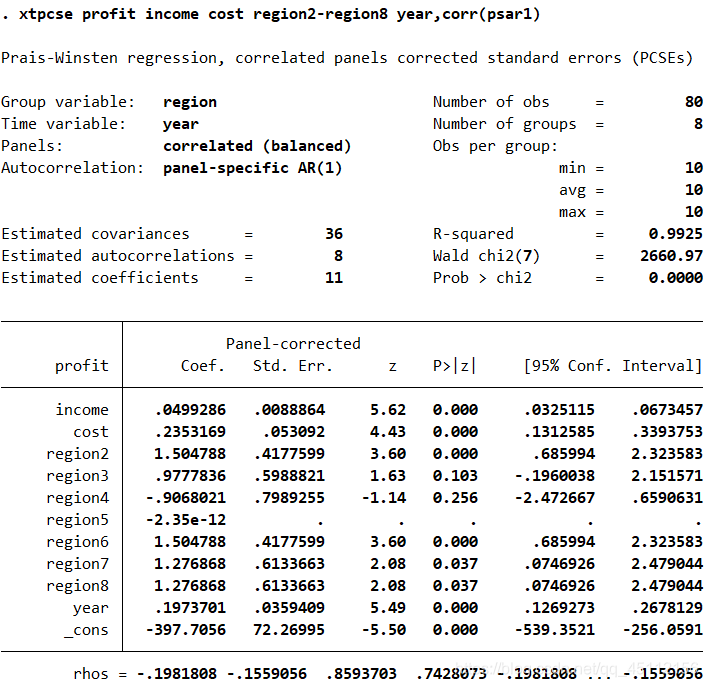
上图可以看出,在仅考虑存在组内自相关,并且各组的自回归系数相同的情形下,进行可行广义最小二乘回归分析的结果与普通最小二乘回归分析的结果是有一些区别的。 xtpcse profit income cost region2-region8 year,corr(psar1) #本命令的含义是在仅考虑存在组内自相关,并且哥组的自回归系数不相同的情形下,进行可行广义最小二乘回归分析。 estimates store psar1
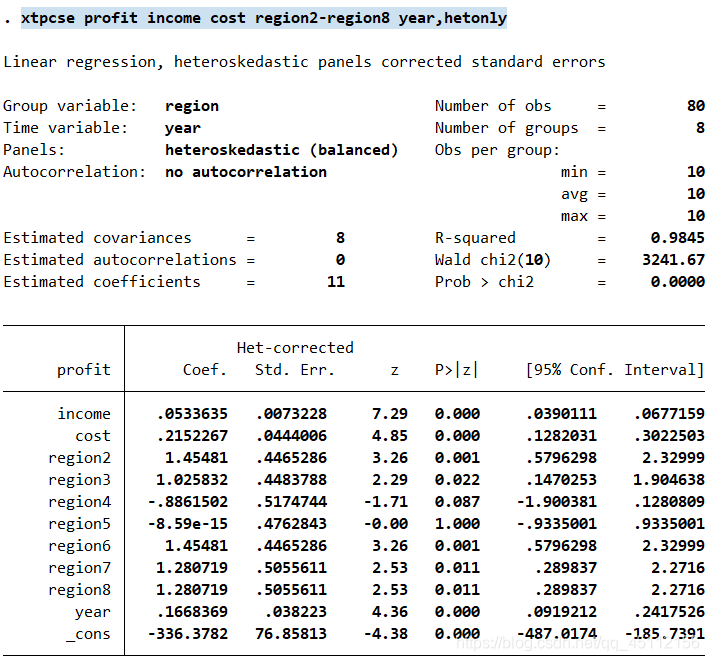
可以看出在仅考虑存在组内自相关,并且哥组的自回归系数不相同的情形下,进行可广义最小二乘回归分析的结果与前面各种回归分析的结果是有一些区别的。 xtpcse profit income cost region2-region8 year,hetonly #本命令的含义是在不考虑存在自相关,仅考虑不同个体扰动项存在异方差的情形下,进行可行广义最小二乘回归分析 estimates store hetonly #存储上不可行广义最小二乘回归分析的估计结果
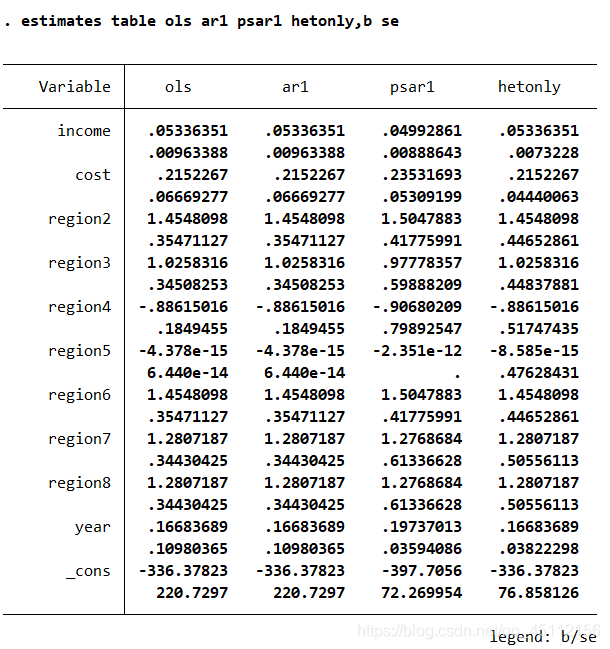
从上图可以可出,在不考虑存在自相关,仅考虑不同个体扰动项存在异方差的情形下,进行广义最小二乘回归分析的结果与前面各种回归分析结果是有一些区别的。 estimates table ols ar1 psar1 hetonly,b se #本命令的含义是展示将以上各种方法的系数估计值及标准差列表放到一起进行比较的结果
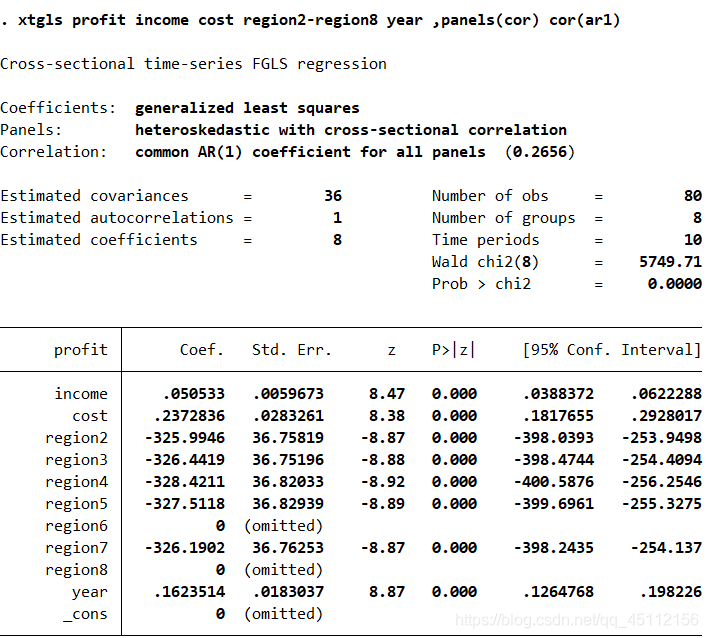
从上图可以看出,hetonly方法的系数估计值和ols方法的系数估计值是完全一样的,但是标准差不一样。其他各种方法之间都存在着一定的差别。 xtgls profit income cost region2-region8 year ,panels(cor) cor(ar1) #本命令事在假定不同个体的扰动项相互独立且有不同得方差,并且各组的自回归系数相同的情形下,进行的可行广义最小二乘回归分析。
每次分析都与前面的各种分析有些区别。 案例延伸 延伸:进行随即系数模型回归分析前面我们讲述的种种面板数据回归分析方法,最多允许每个个体拥有自己的截距项,从来没有允许每个个体拥有子的回归方程斜率。变系数的命令如下 xtrc profit income cost , betas本命令不仅每个个体拥有自己的截距项,还允许每个个体拥有自己的回归方程斜率,旨在进行随机系数模型回归分析。 模型中对参数一致检验的显著性P值为0.0000(Test of parameter constancy:chi2(21)=891.48 Prob > chi2 = 0.0000),显著的拒绝链每个个体都具有相同系数的原假设,我们的变系数模型设置时非常合理的。 |
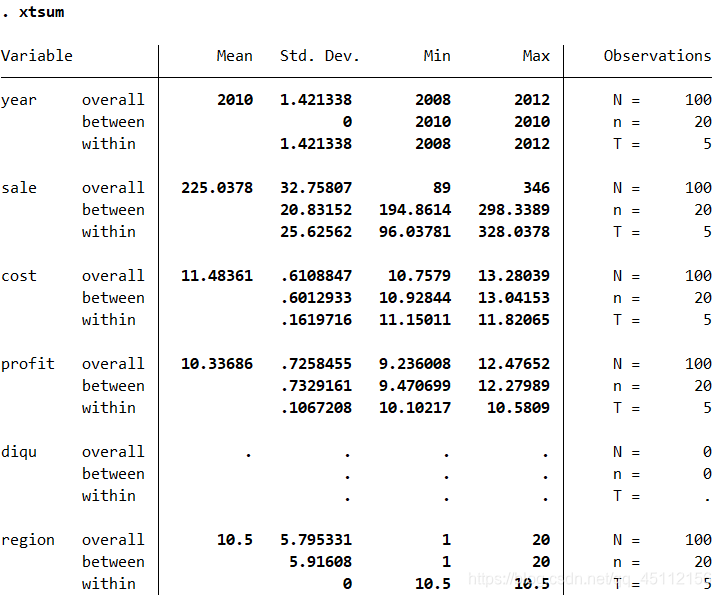 上图是面板数据组内、组间以及整体的统计指标的结果。在短面板数据中,同一时间段内的不同观测样本构成一个组。从图中可以看出变量year的组间标准差是0,因为不同组的这一变量取值完全相同,同时变量region的组内标准差也为0,因为分布在同一组的数据属于同一个地区。
上图是面板数据组内、组间以及整体的统计指标的结果。在短面板数据中,同一时间段内的不同观测样本构成一个组。从图中可以看出变量year的组间标准差是0,因为不同组的这一变量取值完全相同,同时变量region的组内标准差也为0,因为分布在同一组的数据属于同一个地区。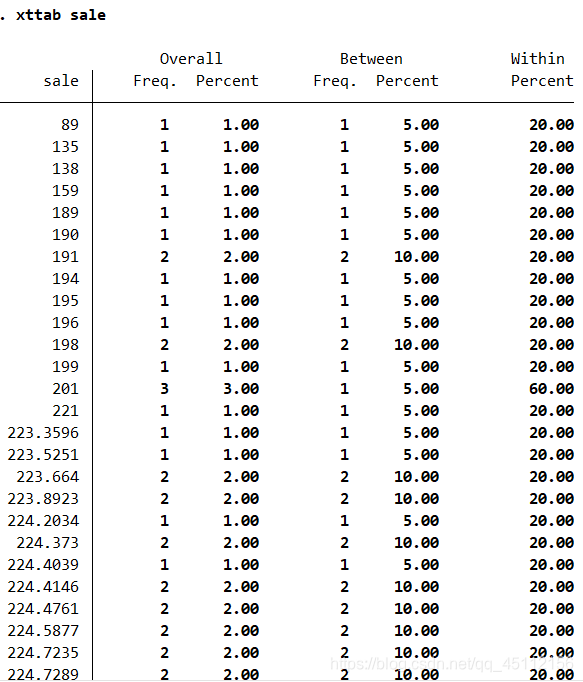
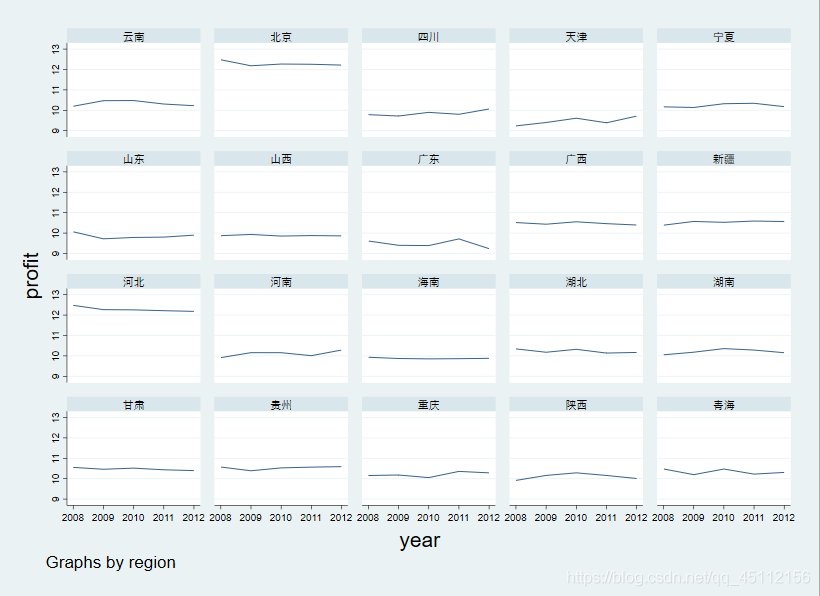 上图是sale的时间序列图,我们可以看到不同地区的销售收入是不一样的有的高有的低,从图中我们还可以看到sale变量在各个地区的时间趋势。
上图是sale的时间序列图,我们可以看到不同地区的销售收入是不一样的有的高有的低,从图中我们还可以看到sale变量在各个地区的时间趋势。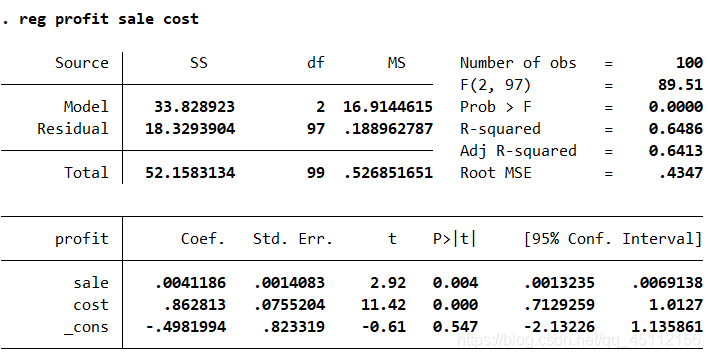
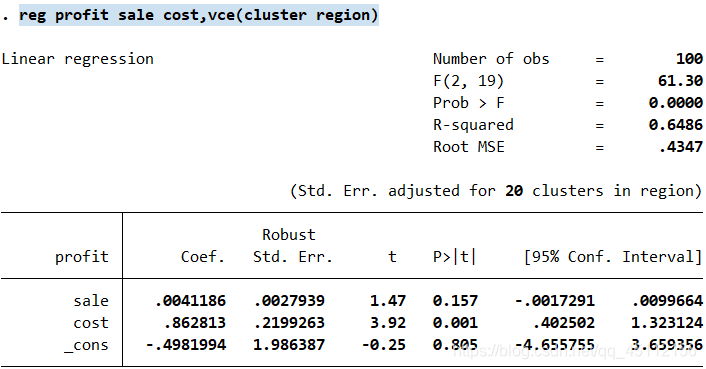 从上图我们可以看出,使用以“region”为聚类变量的聚类文件标准差进行最小二乘回归分析的结果与普通最小二乘回归分析得到的结果类似,只是sale变量系数的显著性有所下降。
从上图我们可以看出,使用以“region”为聚类变量的聚类文件标准差进行最小二乘回归分析的结果与普通最小二乘回归分析得到的结果类似,只是sale变量系数的显著性有所下降。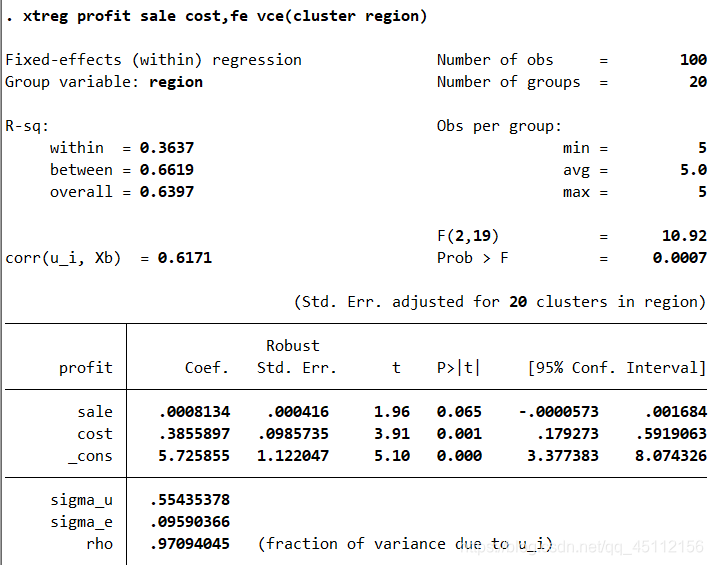

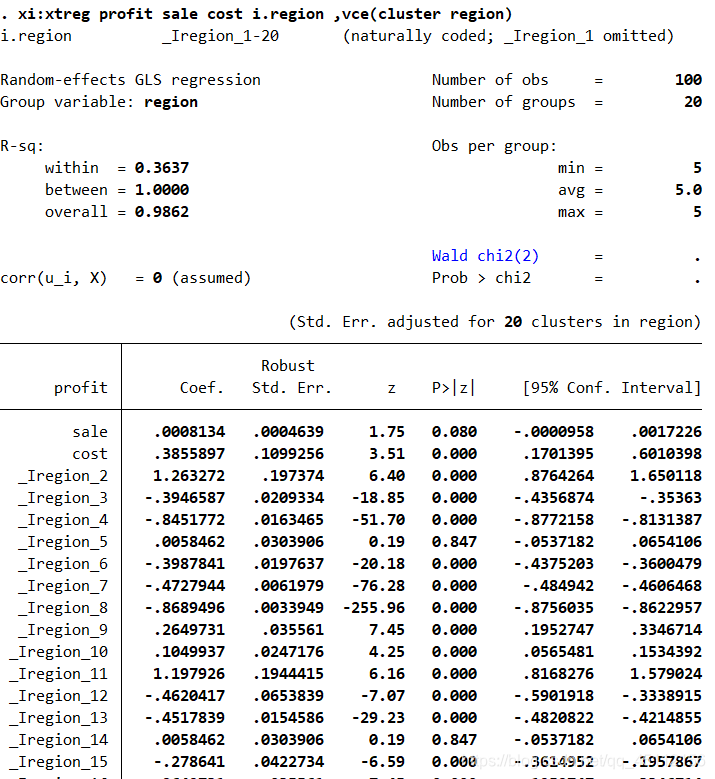
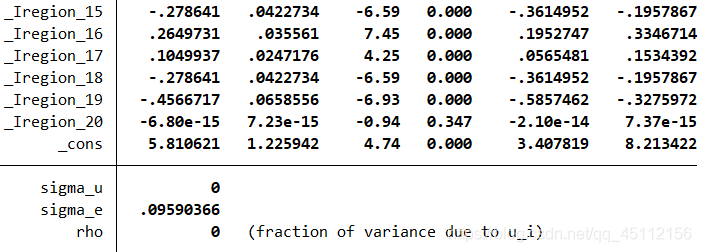 从上图可以看出,大多数个体虚拟变量的显著性P值都是小于0.05的,所以我们可以非常有把握的认为可以拒绝“所有个体的虚拟变量皆为0”的原假设,也就是说固定效应模型是由于普通最小二乘回归模型的。
从上图可以看出,大多数个体虚拟变量的显著性P值都是小于0.05的,所以我们可以非常有把握的认为可以拒绝“所有个体的虚拟变量皆为0”的原假设,也就是说固定效应模型是由于普通最小二乘回归模型的。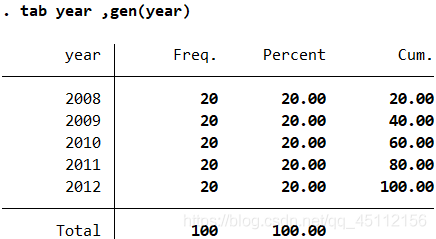
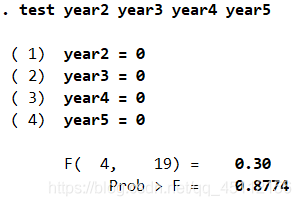


【本文地址】