| 无水印抖音视频批量下载 | 您所在的位置:网站首页 › 无水印抖音视频如何找到作者名字和地址 › 无水印抖音视频批量下载 |
无水印抖音视频批量下载
|
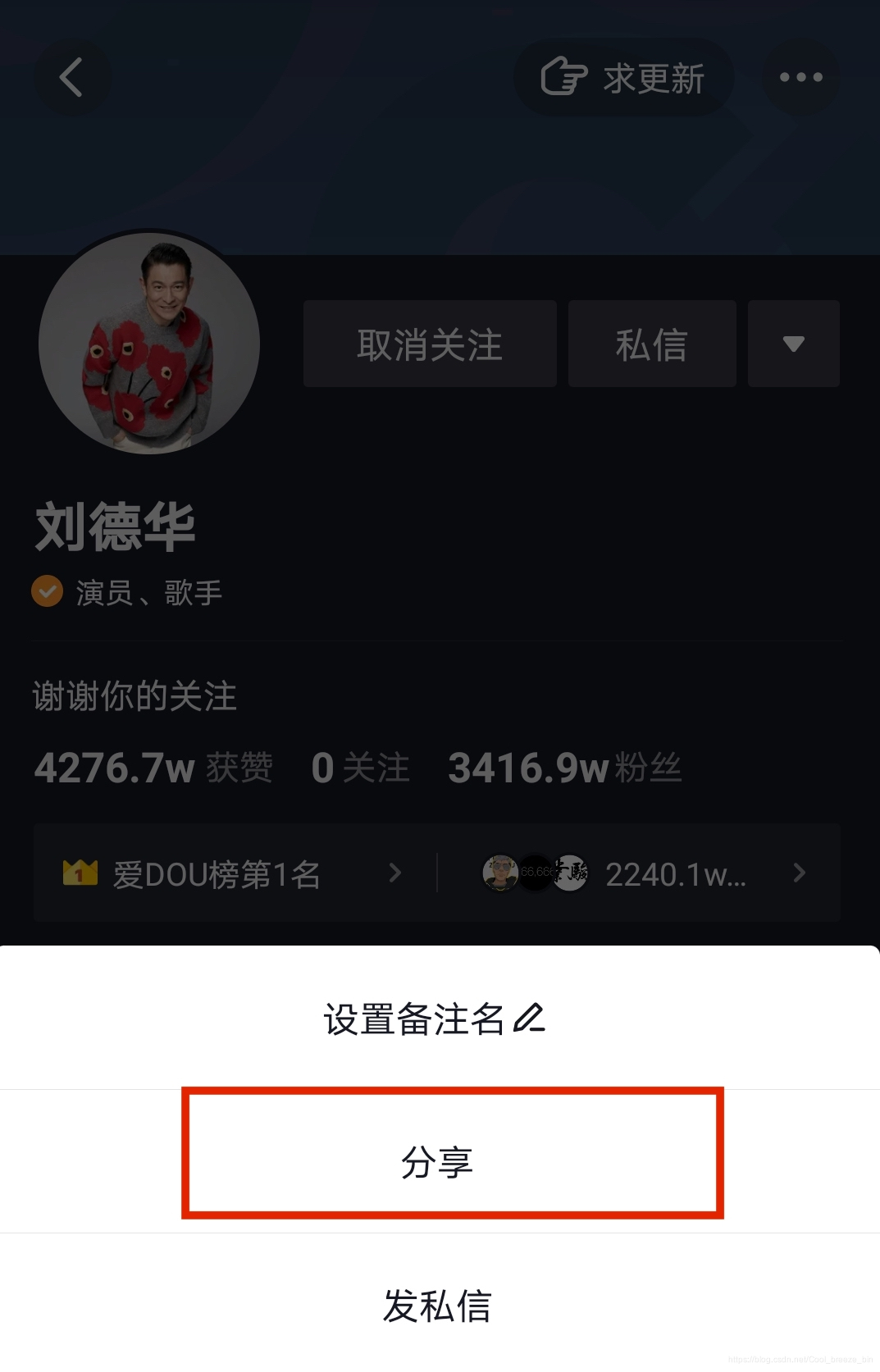
原文链接:https://blog.csdn.net/Cool_breeze_bin/article/details/113356288?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-17.control&dist_request_id=1328602.30574.16150346664273767&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-17.control 声明:此教程只用于学习,不可商用 手机操作 首先手机打开抖音,找到作者主页:我们以天王“刘德华”抖音为例。
第一步,点击右上角“···”,如下点击分享:
然后如下图所示,复制链接:
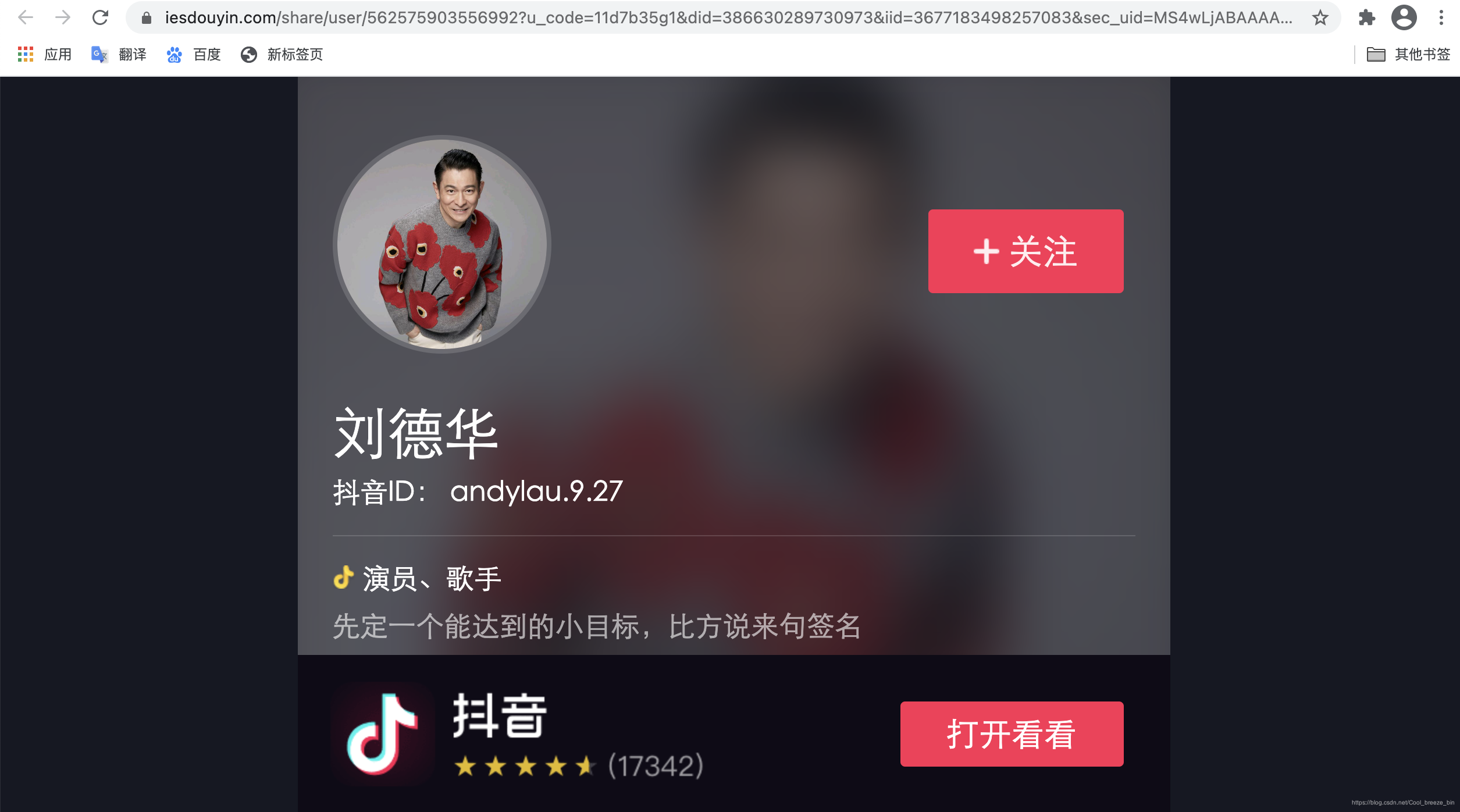
将我们在手机上复制的链接通过浏览器打开:
我们向下划,发现并没有真正的页面内容
这是因为抖音最新加入了网页隐藏功能,我们打开解析页也可发现相关内容只有大概框架,并无真实内容。
对于这一问题,我们反复刷新网页即可(后面代码实现部分也有对应解决方案):
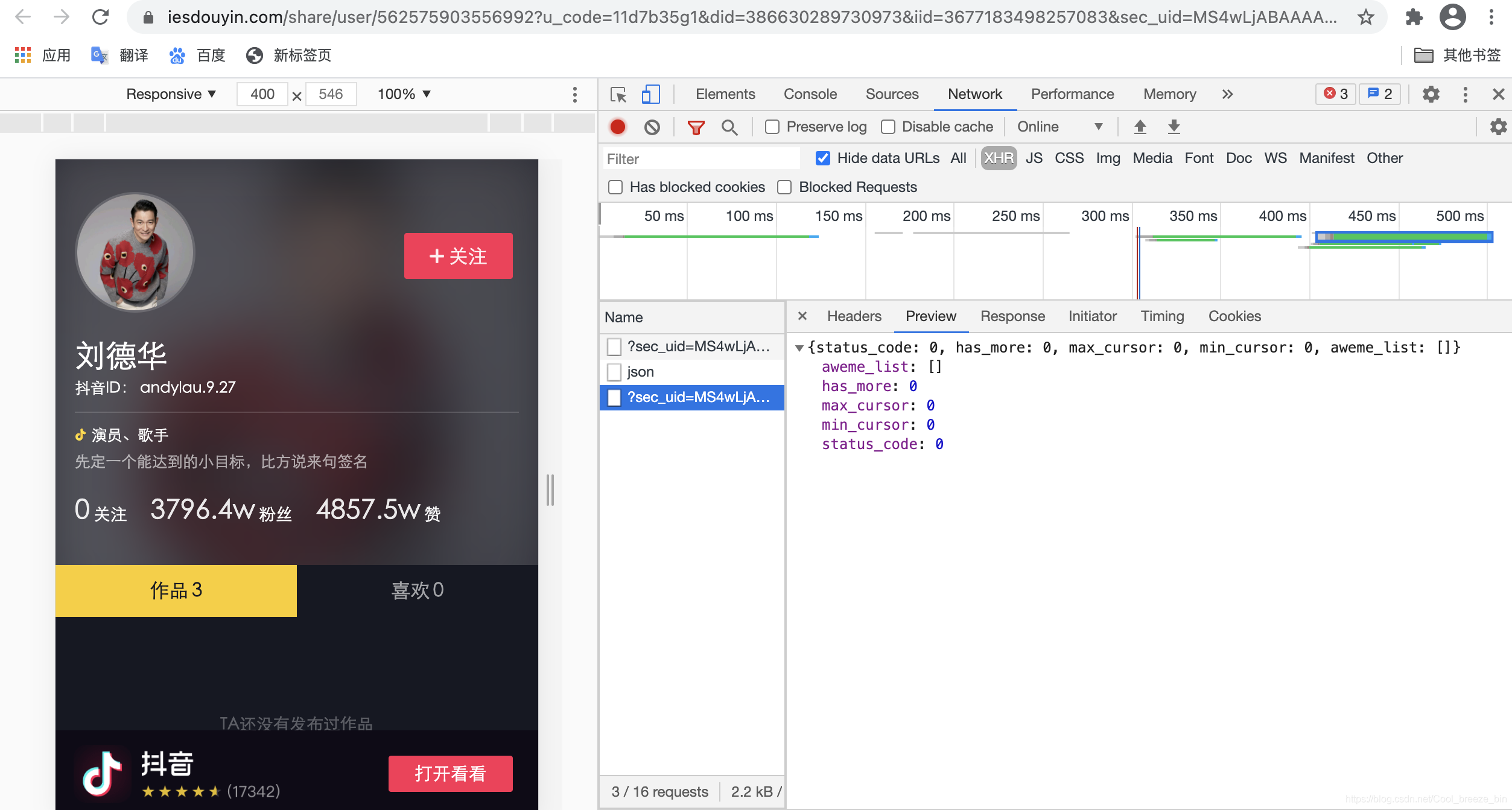
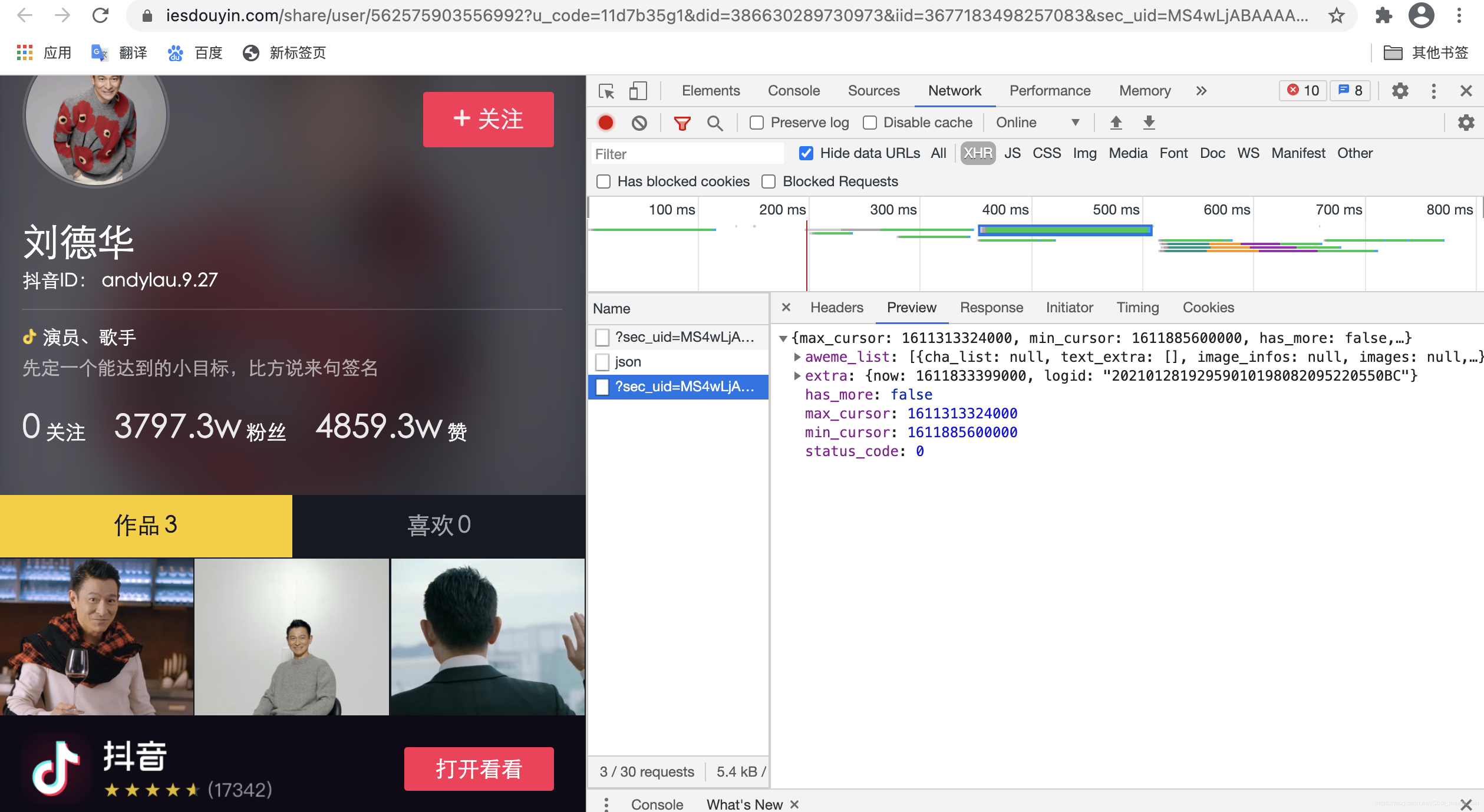
通过刷新成功后的上图,我们可以知道这是正确的解析页。我们接下来对细分内容进行分析即可。首先展开“aweme_list”列表进行查看,我们很容易发现:一共有3行数据,也就是3条视频,而“desc”对应的参数就是抖音视频的题目。
我们再打开其中一个标签进行深究,发现如下图所示:
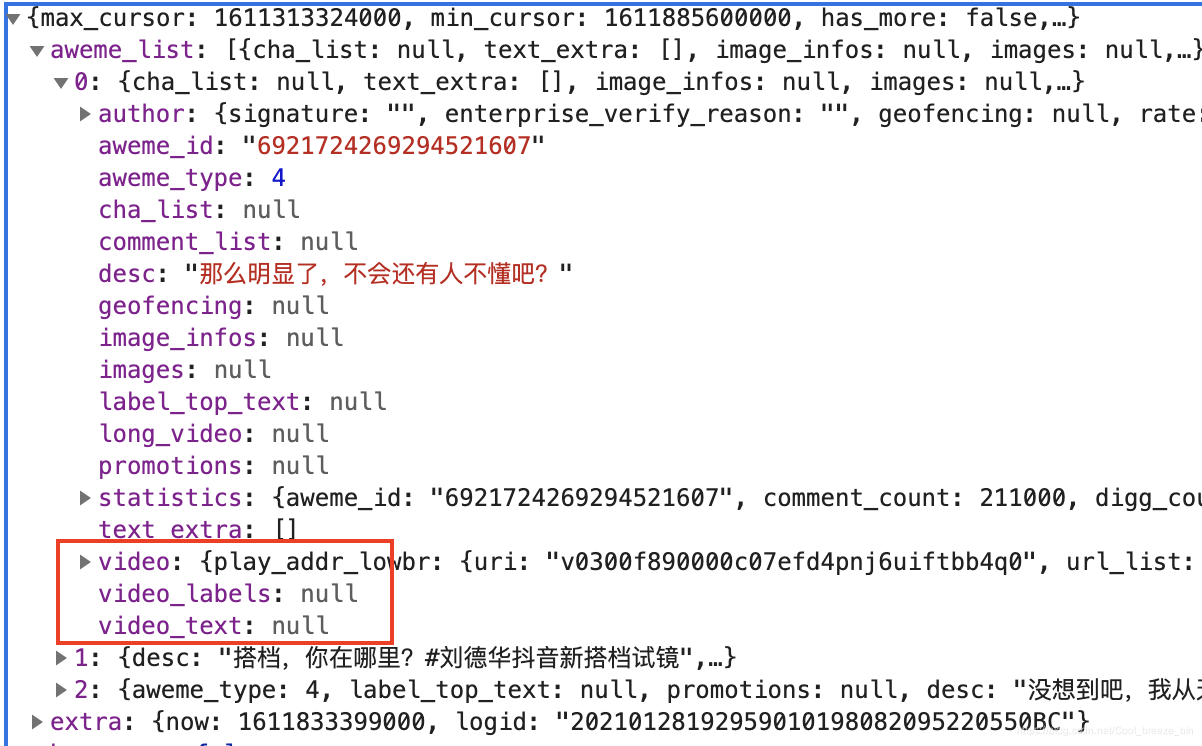
出现“video”标签,通过英文翻译也就是“视频”的意思,我们通过此标签继续深挖,其下一级标签如下图所示:
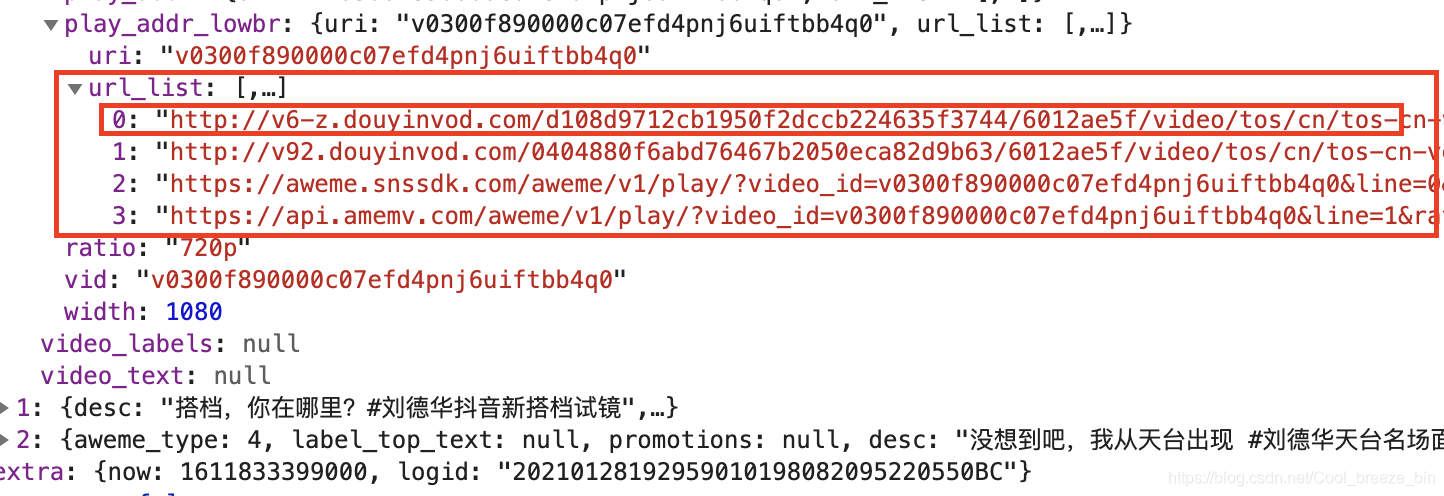
我们又可以找到“play_addr_lowbr”的标签,进行展开后如下图所示:
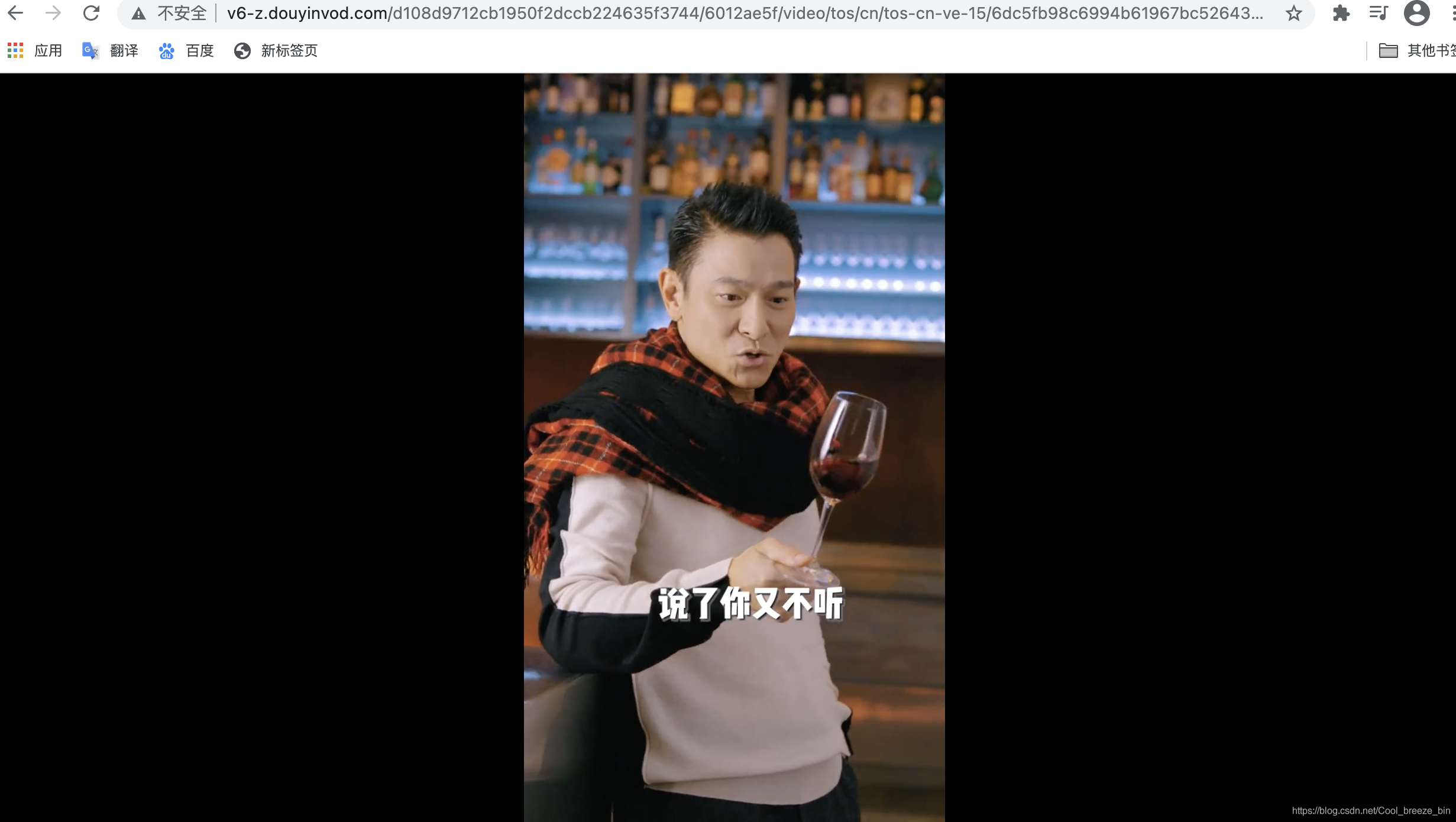
通过上图展开“url_list”标签,即视频的访问地址。我们只需其中的第一条链接即可,将其复制并使用浏览器打开,如下图:
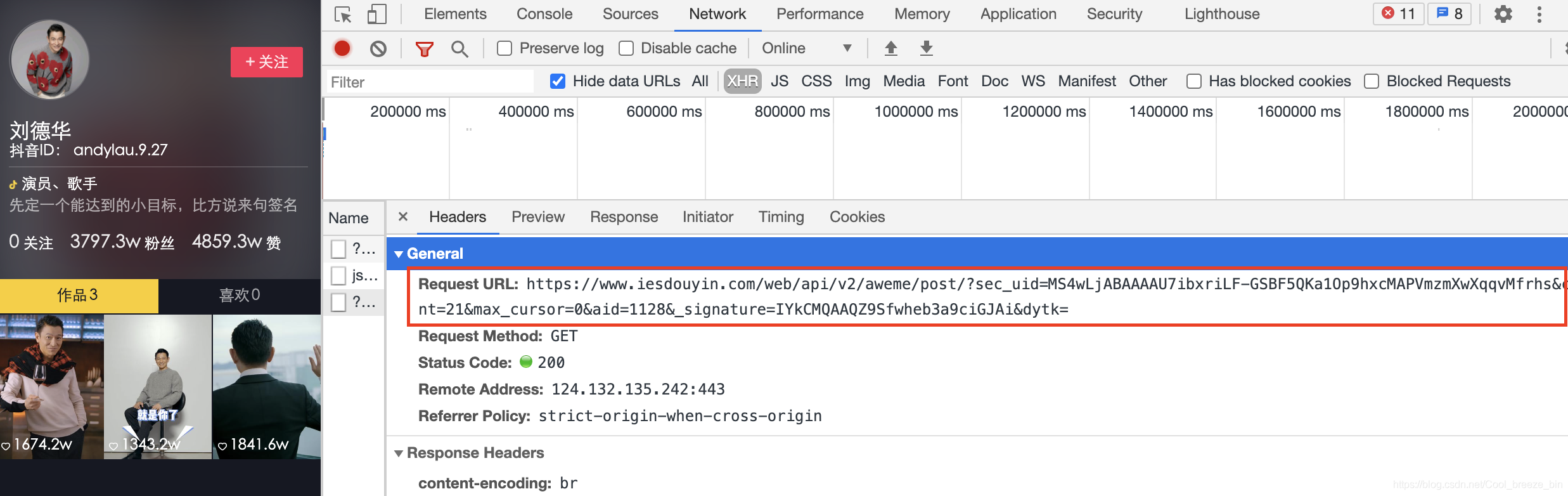
我们看到了无水印的视频,也就是我们需要的视频。网页分析结束,接下来上代码。 代码部分需要的相关python库为:requests和json两个库 import requests import json # 抖音视频的URL url="https://www.iesdouyin.com/web/api/v2/aweme/post/?sec_uid=MS4wLjABAAAAU7ibxriLF-GSBF5QKa1Op9hxcMAPVmzmXwXqqvMfrhs&count=21&max_cursor=0&aid=1128&_signature=rrFSDQAAzq.dR1hiGSYhIa6xUh&dytk=" headers = { 'User-Agent':"Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36" } #调用requests中的get获取抖音作者主页的网页链接 r = requests.get(url=url, headers=headers,stream=True) #输出访问状态,如为即为访问成功 print("初始访问状态:",r) #使用json解析获取的网页内容 data_json = json.loads(r.text) #使用json解析网页后,data_json的内容为dict格式,我们可以通过以下方式查看健名 print(data_json.keys()) #pd参数为布尔类型参数,data_json['aweme_list'] == []是为了判断'aweme_list'下一级内容是否为空,为空则为True pd = data_json['aweme_list'] == [] #接下来使用循环来解决我们之前所提到的“隐藏内容”问题 while pd == True: #只要“aweme_list”下一级内容为空,则反复访问作者主页链接,直到成功显示隐藏内容为止跳出循环 r = requests.get(url=url, headers=headers,stream=True) data_json = json.loads(r.text) pd = data_json['aweme_list']== [] #下一级内容不为空,则访问下一级标签 for i in range(len(data_json['aweme_list'])): print(data_json['aweme_list'][i]['video']['play_addr_lowbr']['url_list'][0])上面所讲的url即解析页中“Headers”下的“requests url”(复制粘贴即可):
“headers”内容即“Headers”下“Request Headers”中的“user-agent”:
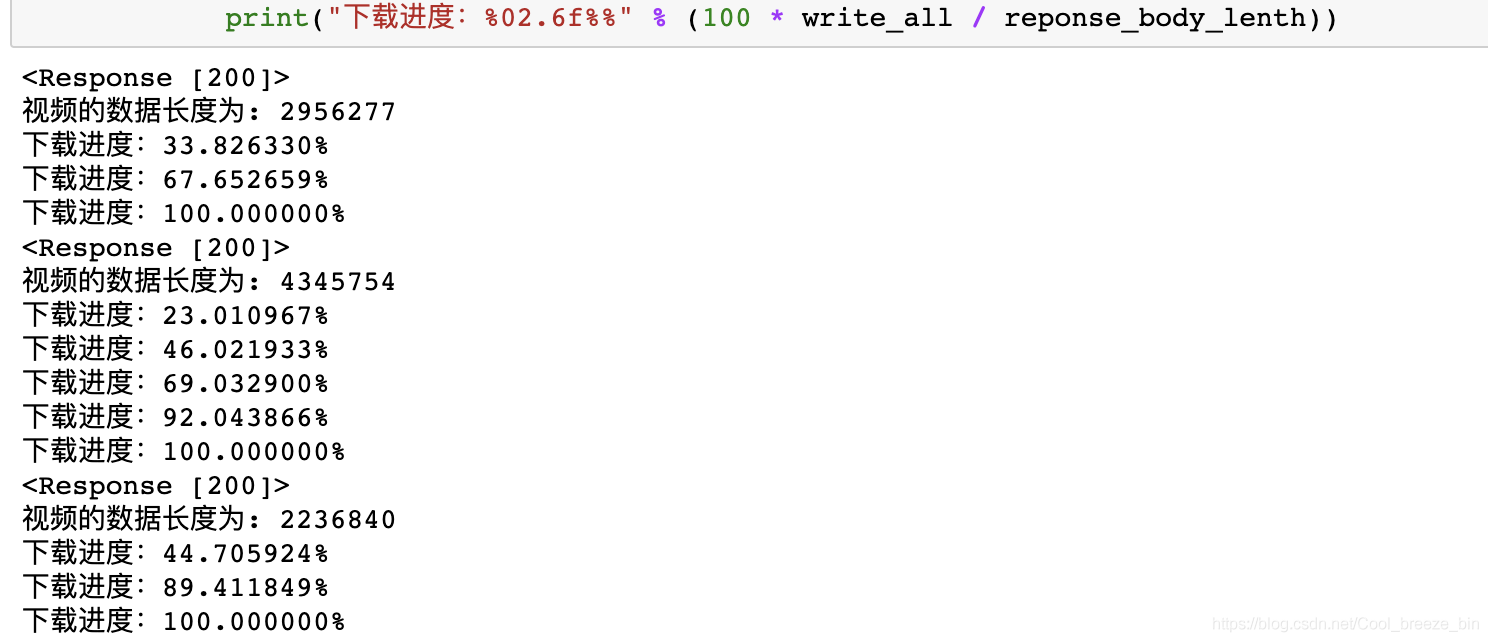
上面代码运行结果如下图所示:
通过上图,我们发现已经成功得到该作者所有作品链接。接下来就是下载到自己的电脑: # 我们要保存视频文件的主要路径 path = "/··/··/Desktop/" for i in range(len(data_json['aweme_list'])): #url_1为我们获取的视频链接 url_1 = data_json['aweme_list'][i]['video']['play_addr_lowbr']['url_list'][0] #t为我们获取的视频标题 t = data_json['aweme_list'][i]['desc'] # requests发送浏览器发送get请求,得到数据 r = requests.get(url=url_1, headers=headers,stream=True) print(r) #输出r访问状态 # 获取数据的二进制长度 reponse_body_lenth = int(r.headers.get("Content-Length")) # 打印数据的长度 print("视频的数据长度为:", reponse_body_lenth) #path_1为完整文件保存路径 path_1 = path+t+'.mp4' # 保存抖音视频mp4格式,二进制读取 with open(path_1, "wb") as xh: # 先定义初始进度为0 write_all = 0 for chunk in r.iter_content(chunk_size=1000000): write_all += xh.write(chunk) # 打印下载进度 print("下载进度:%02.6f%%" % (100 * write_all / reponse_body_lenth))运行代码:
如上图所示,下载完毕后,我们便可在桌面找到爬取的无水印的抖音视频文件(我的path参数指向桌面,路径可自行修改)
|







【本文地址】