| 【精选】Python数据分析案例 | 您所在的位置:网站首页 › 方差计算案例及分析 › 【精选】Python数据分析案例 |
【精选】Python数据分析案例
|
1. 前言
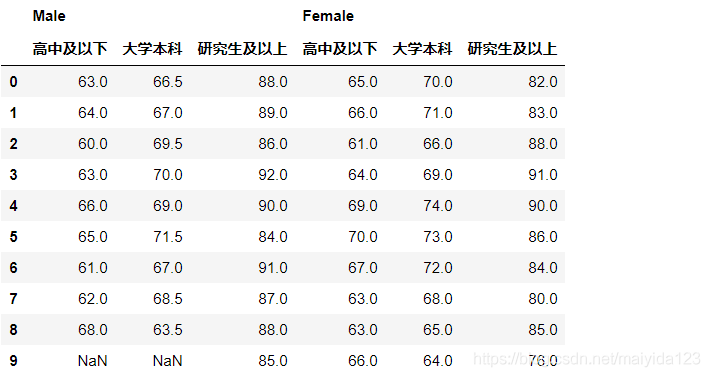
背景:表格为随机挑选的不同性别与受教育程度的对象的幸福指数数据, 目的:现要求分析幸福指数是否受不同的性别和受教育程度影响。 分析方法:两个自变量是分类变量,因变量是连续变量,所以选择多因素方差分析。 方差分析需要满足的条件: 1.各样本须是相互独立的随机样本;2.各样本来自正态分布总体;3.各样本方差齐性。显著性水平:选取为0.05 工具:Jupyter Notebook(Python 3.8) 2. Python数据查看 data = [['Male', '高中及以下', 63.0], ['Male', '高中及以下', 64.0], ['Male', '高中及以下', 60.0], ['Male', '高中及以下', 63.0], ['Male', '高中及以下', 66.0], ['Male', '高中及以下', 65.0], ['Male', '高中及以下', 61.0], ['Male', '高中及以下', 62.0], ['Male', '高中及以下', 68.0], ['Male', '大学本科', 66.5], ['Male', '大学本科', 67.0], ['Male', '大学本科', 69.5], ['Male', '大学本科', 70.0], ['Male', '大学本科', 69.0], ['Male', '大学本科', 71.5], ['Male', '大学本科', 67.0], ['Male', '大学本科', 68.5], ['Male', '大学本科', 63.5], ['Male', '研究生及以上', 88.0], ['Male', '研究生及以上', 89.0], ['Male', '研究生及以上', 86.0], ['Male', '研究生及以上', 92.0], ['Male', '研究生及以上', 90.0], ['Male', '研究生及以上', 84.0], ['Male', '研究生及以上', 91.0], ['Male', '研究生及以上', 87.0], ['Male', '研究生及以上', 88.0], ['Male', '研究生及以上', 85.0], ['Female', '高中及以下', 65.0], ['Female', '高中及以下', 66.0], ['Female', '高中及以下', 61.0], ['Female', '高中及以下', 64.0], ['Female', '高中及以下', 69.0], ['Female', '高中及以下', 70.0], ['Female', '高中及以下', 67.0], ['Female', '高中及以下', 63.0], ['Female', '高中及以下', 63.0], ['Female', '高中及以下', 66.0], ['Female', '大学本科', 70.0], ['Female', '大学本科', 71.0], ['Female', '大学本科', 66.0], ['Female', '大学本科', 69.0], ['Female', '大学本科', 74.0], ['Female', '大学本科', 73.0], ['Female', '大学本科', 72.0], ['Female', '大学本科', 68.0], ['Female', '大学本科', 65.0], ['Female', '大学本科', 64.0], ['Female', '研究生及以上', 82.0], ['Female', '研究生及以上', 83.0], ['Female', '研究生及以上', 88.0], ['Female', '研究生及以上', 91.0], ['Female', '研究生及以上', 90.0], ['Female', '研究生及以上', 86.0], ['Female', '研究生及以上', 84.0], ['Female', '研究生及以上', 80.0], ['Female', '研究生及以上', 85.0], ['Female', '研究生及以上', 76.0]] df = pd.DataFrame(data, columns = ['gender', 'education', 'Index']) df.head()
转换 df1 = pd.DataFrame() data_list = [] for i in df.gender.unique(): for j in df.education.unique(): data = df[(df.gender == i)&(df.education == j)]['Index'].values data_list.append(data) df1 = df1.append(pd.DataFrame(data, columns = pd.MultiIndex.from_arrays([[i],[j]])).T) df1 = df1.T df1
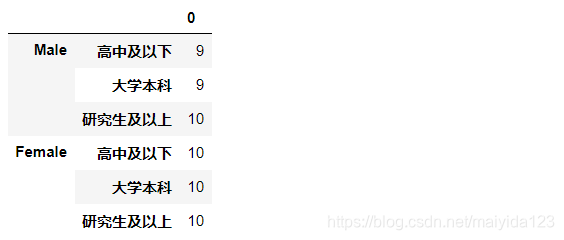
各组数量统计 # 查看各组数量分布 df1.count().to_frame()
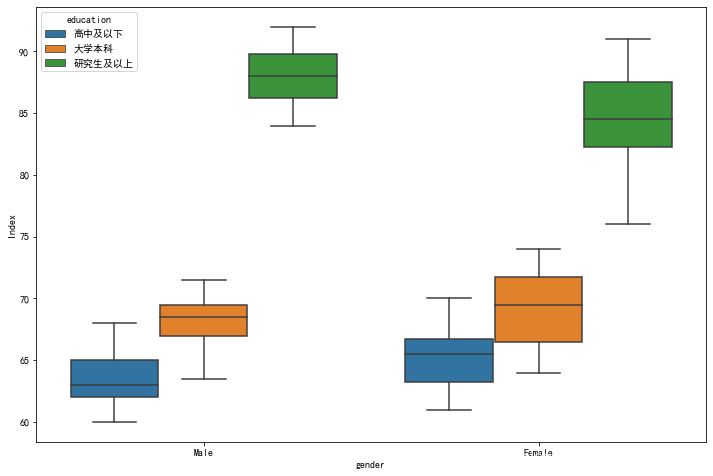
箱线图查看异常值 plt.figure(figsize = (12,8)) sns.boxplot(x = 'gender', y = 'Index', data = df, hue = 'education') plt.show()
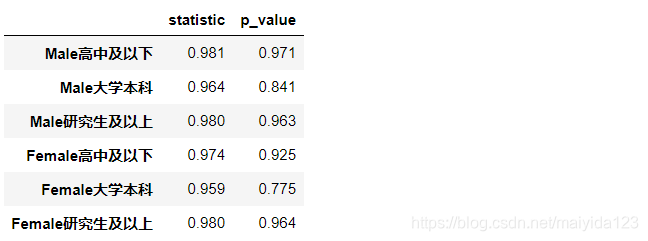
正态性检验 # Shapiro-Wilk 检验 sw_test_res = pd.DataFrame() for i in df1.columns: statistic,pvalue = stats.shapiro(df1[i].dropna()) sw_test_res[i] = [statistic, pvalue] sw_test_res.index = ['statistic', 'p_value'] sw_test_res.T.round(3)
方差齐性检验 # levene test print('基于中位数的levene test P值:', stats.levene(*data_list, center='median').pvalue) P值为0.286,大于0.05,即任一分类都具有等方差性判断交互作用 计算平均值 df_mean = df1.mean().to_frame().unstack().round(1) df_mean.columns = ['大学本科', '研究生及以上', '高中及以下'] df_mean = df_mean[['高中及以下', '大学本科', '研究生及以上']] df_mean
多因素方差分析 将交互项放入方差分析 anova = smf.ols('Index ~ C(gender) + C(education) + C(gender)*C(education)',data = df).fit() sm.stats.anova_lm(anova, typ=1)
事后比较 不同教育程度的事后比较 # 事后多重比较 sm.stats.multicomp.pairwise_tukeyhsd(groups = df.education, endog=df.Index).summary()
|

 绘制交互图
绘制交互图

 结果显示:
结果显示: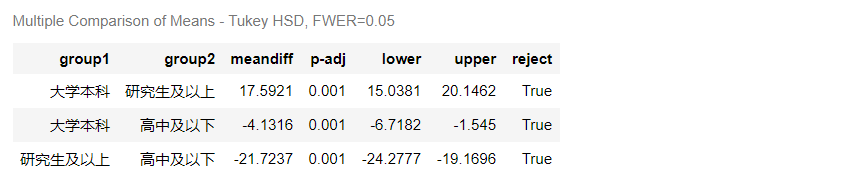 由事后比较可得:
由事后比较可得:【本文地址】
公司简介
联系我们