| 微博博文内容爬取 | 您所在的位置:网站首页 › 新版本微博怎么悄悄关注不了 › 微博博文内容爬取 |
微博博文内容爬取
|
不知你们发现了没有,微博偷偷推出了一个新版本的 网页版
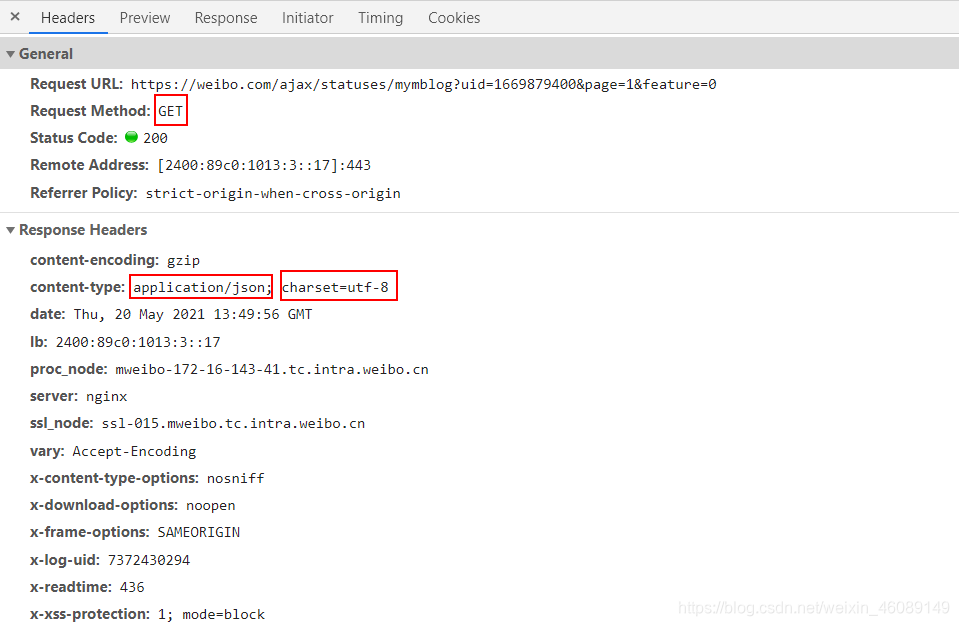
我们很容易的就能找到这个请求,我们可以看到,里面包含博文内容信息、点赞数、转发数、评论数、发文时间等等一些信息。
还能获得热巴的照片哦,这里就不再教你们了^_^。 二、接口分析 url分析 第一页: https://weibo.com/ajax/statuses/mymblog?uid=1669879400&page=1&feature=0 继续往下翻: 第二页: https://weibo.com/ajax/statuses/mymblog?uid=1669879400&page=2&feature=0 可以发现改变的只有page这个参数,代表的是第几页
其中的uid就是热巴微博用户id了,如果把这个uid换成你女神的uid那么爬取的就是你女神的博文信息了,懂??? OK,万事大吉 返回数据分析
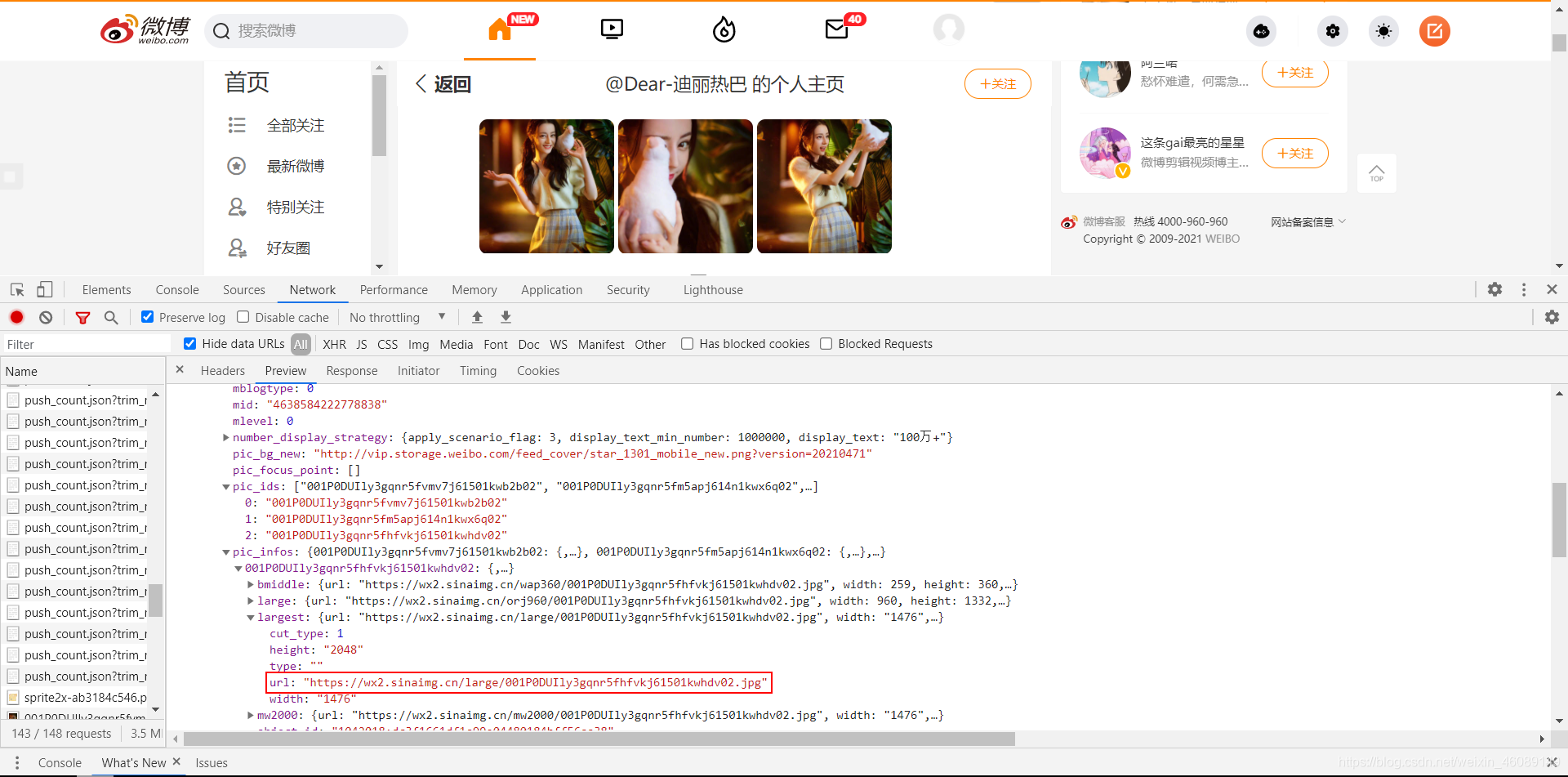
用的是GET请求,返回的数据类型是json格式的,编码为utf-8。 直接把得到的数据按照json数据格式化就行了。 三、编写代码 知道了url规则,以及返回数据的格式,那现在咱们的任务就是构造url然后请求数据 现在来构造url: 写道这不知道你们意识到了没,怎么知道他有多少页的博文呢? 那咱们就用while循环来解决,一旦请求不到博文了咱们就可退出循环了。 uid = 1669879400 url = 'https://weibo.com/ajax/statuses/mymblog?uid={}&page={}&feature=0' page = 1 while 1: url = url.format(uid, page) page += 1对于每个url我们都要去用requests库中的get方法去请求数据: 所以我们为了方便就把请求网页的代码写成了函数get_html(url),传入的参数是url返回的是请求到的内容。 def get_html(url): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36", "Referer": "https://weibo.com" } cookies = { "cookie": "你的cookie" } response = requests.get(url, headers=headers, cookies) time.sleep(3) # 加上3s 的延时防止被反爬 return response.text把自己的cookie里面的信息替换掉代码里的就好了。 cookies获取方式 获取数据 html = get_html(url) responses = json.loads(html) blogs = responses['data']['list'] data = {} # 新建个字典用来存数据 for blog in blogs: data['attitudes_count'] = blog['attitudes_count'] # 点赞数量 data['comments_count'] = blog['comments_count'] # 评论数量(超过100万的只会显示100万) data['created_at'] = blog['created_at'] # 发布时间 data['reposts_count'] = blog['reposts_count'] # 转发数量(超过100万的只会显示100万) data['text_raw'] = blog['text_raw'] # 博文正文文字数据保存数据 定义一个函数 def save_data(data): title = ['text_raw', 'created_at', 'attitudes_count', 'comments_count', 'reposts_count'] with open("data.csv", "a", encoding="utf-8", newline="")as fi: fi = csv.writer(fi) fi.writerow([data[i] for i in title])完整代码 # -*- coding:utf-8 -*- # @time: 2021/5/20 5:20 # @Author: 韩国麦当劳 # @Environment: Python 3.7 # @file: 有情人终成眷属.py import requests import csv import time import json def get_html(url): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36", "Referer": "https://weibo.com" } cookies = { "cookie": "你的cookie" } response = requests.get(url, headers=headers, cookies=cookies) time.sleep(3) # 加上3s 的延时防止被反爬 return response.text def save_data(data): title = ['text_raw', 'created_at', 'attitudes_count', 'comments_count', 'reposts_count'] with open("data.csv", "a", encoding="utf-8", newline="")as fi: fi = csv.writer(fi) fi.writerow([data[i] for i in title]) if __name__ == '__main__': uid = 1669879400 url = 'https://weibo.com/ajax/statuses/mymblog?uid={}&page={}&feature=0' page = 1 while 1: print(page) url = url.format(uid, page) html = get_html(url) responses = json.loads(html) blogs = responses['data']['list'] if len(blogs) == 0: break data = {} # 新建个字典用来存数据 for blog in blogs: data['attitudes_count'] = blog['attitudes_count'] # 点赞数量 data['comments_count'] = blog['comments_count'] # 评论数量(超过100万的只会显示100万) data['created_at'] = blog['created_at'] # 发布时间 data['reposts_count'] = blog['reposts_count'] # 转发数量(超过100万的只会显示100万) data['text_raw'] = blog['text_raw'] # 博文正文文字数据 save_data(data) page += 1获得的部分数据截图
|

 界面相对原版微博来说简直是舒服了不知多少倍,全新炫目的微博界面、清晰有条理的分组阅读、个性化的应用管理……(微博打钱!) 那咱们今天就用这个来爬一爬你女神历史博文数据吧! 一、网页分析 今天我选择的女神是迪丽热巴!阿巴阿巴 找到热巴的主页,依旧先打开开发者模式,然后刷新网页。
界面相对原版微博来说简直是舒服了不知多少倍,全新炫目的微博界面、清晰有条理的分组阅读、个性化的应用管理……(微博打钱!) 那咱们今天就用这个来爬一爬你女神历史博文数据吧! 一、网页分析 今天我选择的女神是迪丽热巴!阿巴阿巴 找到热巴的主页,依旧先打开开发者模式,然后刷新网页。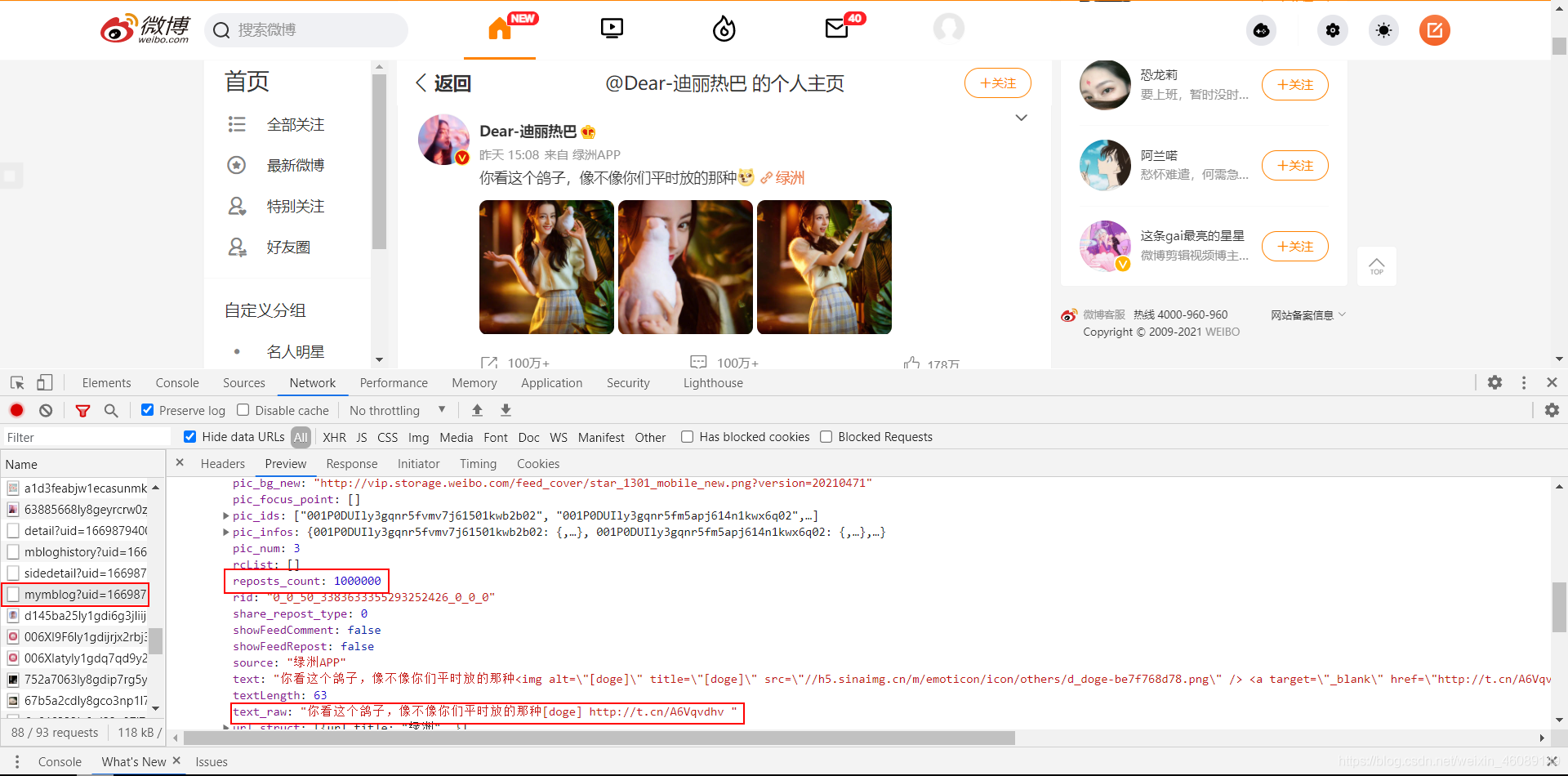
 版权声明:本文为CSDN博主「韩国麦当劳」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:Python爬虫实战(三):微博博文内容爬取_韩国麦当劳的博客-CSDN博客_python微博爬虫实战
版权声明:本文为CSDN博主「韩国麦当劳」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:Python爬虫实战(三):微博博文内容爬取_韩国麦当劳的博客-CSDN博客_python微博爬虫实战【本文地址】