| 自然语言处理NLP | 您所在的位置:网站首页 › 文章摘要提取算法有哪些 › 自然语言处理NLP |
自然语言处理NLP
|
利用三种方法实现抽取式自动摘要,并给摘要结果打分(一、textrank 二、word2vec+textrank 三、MMR 四、Rouge评测)
具体代码我上传到了Github上,其中有45篇小论文(包括三种摘要方法生成的摘要、标准摘要和各摘要方法生成的摘要的p、r、f值),地址如下: https://github.com/God-Fish-X/Extractable-automatic-Text 网上有很多关于自动文摘的博客和资料,我主要参考自ReignsDu作者,原文地址为https://blog.csdn.net/reigns_(在作者博客的最下方) 此篇博客也是我参考的重点https://blog.csdn.net/qq_22636145/article/details/75099792?locationNum=5&fps=1 写这篇博客的目的主要是记录一下在学习过程中遇到的一些问题,和这些问题的解决方案。 前期准备工作(包括下载中文语料库、提取正文、繁简转化、jieba分词、训练模型)首先是中文语料库的下载,我使用的是维基百科的中文语料,下载地址是https://dumps.wikimedia.org/zhwiki/ 选择最新的即可
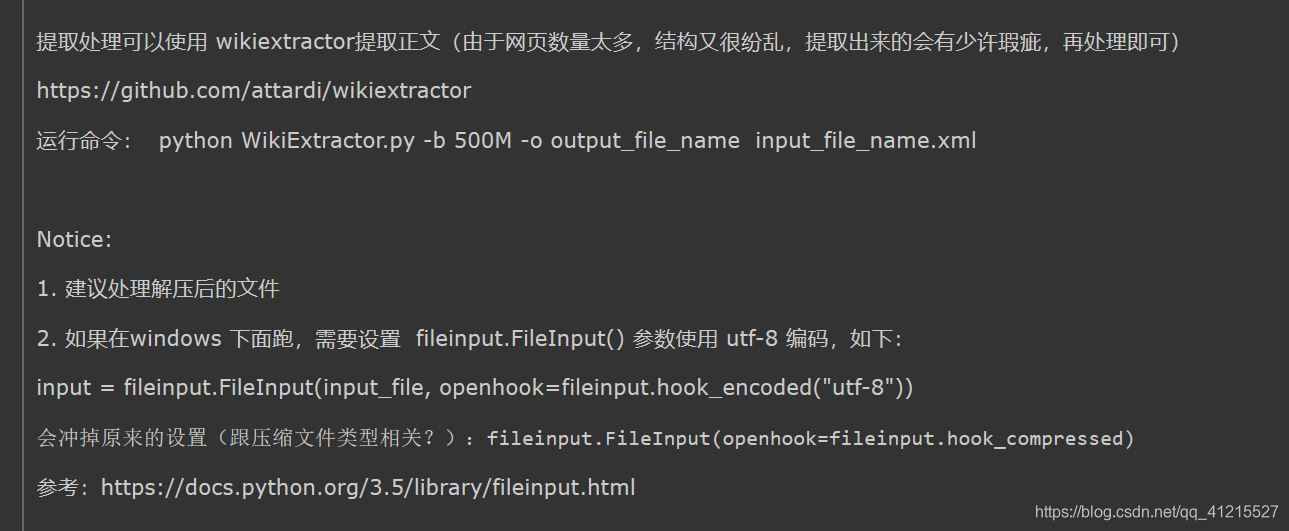
接着下载意大利程序员用python研发的维基百科抽取器,可抽取出维基百科中文语料库的内容并输出。 下载地址为:https://github.com/attardi/wikiextractor win下需要更改文件中的input行,如下图,并用如下语句提取内容(我将分割的数值设置到2048m,把所有内容提取到一个文档中)
抽取出来的内容是繁体,用opencc对语料库进行繁简转换 使用pip install opencc安装opencc包,遇到的错误无法解决,在查找资料后选择用如下新包,无法安装的问题得以解决
此处我的解决方法是把提取出的内容拷到ubuntu系统下,在ubuntu系统下重新安装opencc,完成繁简转换 将ubuntu下处理好的语料库重新拷贝到win下,开始jieba分词以及去除停用词(网上有很多停用词文档,自行下载即可) import jieba import codecs import re file_chinese_one = codecs.open('cut_zh_wiki.txt',"a+",'utf-8') #file_chinese_two = codecs.open('cut_zh_wiki_01.txt',"a+",'utf-8') stopwordslist = [line.strip() for line in open('stopwords.txt',encoding='utf-8').readlines()] #创建停用词列表 for line in open("chinese_corpus/zh_wiki_00",'r',encoding='utf-8'): for i in re.sub('[a-zA-Z0-9]', '', line).split(' '): if i != '': data = list(jieba.cut(i, cut_all = False)) readline = ' '.join(data) + '\n' file_chinese_one.write(readline) file_chinese_one.close() #去除停用词 for line in open("zh_wiki","r",encoding='utf-8'): for i in re.sub('[a-zA-Z0-9]','',line).split(' '): if i != '': data = list(jieba.cut(i,cut_all=False)) outstr = '' for word in data: if word not in stopwordslist: if word != '\t': outstr += word outstr += " " file_chinese_one.write(outstr + '\n') file_chinese_one.close() 这一步是模型训练,在此处我踩坑无数,浪费了将近20个小时 此处用word2vec进行模型训练 代码如下 from gensim.models import word2vec import logging logging.basicConfig(format = '%(asctime)s : %(levelname)s : %(message)s',level=logging.INFO) sentences_one = word2vec.LineSentence(u'./cut_zh_wiki.txt') #sentences_two = word2vec.LineSentence(u'./cut_zh_wiki_01.txt') model_one = word2vec.Word2Vec(sentences_one,size=200,window=10,min_count=64,sg=1,hs=1,iter=10,workers=25) #model_two = word2vec.Word2Vec(sentences_two,size=200,window=10,min_count=64,sg=1,hs=1,iter=10,workers=25) model_one.save(u'./train_test_x/word2vec2') #model_one.wv.save_word2vec_format(u'./w2v',binary=False) #model_two.save(u'./word2vec2')(此处遇到的问题是,训练后的模型在pycharm中打开是乱码,导致我以为是我文档的编码有问题,导致训练出错;1、我更改了编码方式再次进行训练,结果仍是乱码;2、用别的代码进行模型训练,结果仍是乱码;3、这次我尝试直接测试模型,发现虽然文档打开是乱码,但是测试模型输出是并非乱码;4、于是我重新用上面的代码进行了最后一次训练,训练完成后文档打开虽然是乱码,但可以正常的进行模型测试) 我训练模型用的是笔记本,配置为 7代i5(HQ)、16G内存、2.50GHz四核,每次训练的时间大概在5到6个小时以下是测试代码和测试结果 from gensim.models import word2vec model = word2vec.Word2Vec.load(u'./train_test_x/word2vec2') similar = model.wv.similarity(u'南京',u'上海') print("南京与上海的相似度为:",similar) similar = model.wv.similarity(u'太原',u'上海') print("太原与合肥的相似度为:",similar) print("与'计算机'最相近的单词") result = model.wv.most_similar(u'地点',topn=20) for each in result: print(each) print()
|
 选择较大的文件下载
选择较大的文件下载
 但此时又遇到了新的问题,在win下安装好后仍报错找不到opencc,即使将opencc的地址添加到path中后问题仍然得不到解决
但此时又遇到了新的问题,在win下安装好后仍报错找不到opencc,即使将opencc的地址添加到path中后问题仍然得不到解决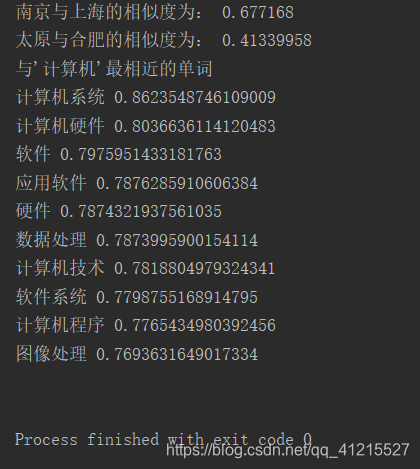
【本文地址】