| Python爬虫:教你四种姿势解析提取数据 | 您所在的位置:网站首页 › 文本爬虫 › Python爬虫:教你四种姿势解析提取数据 |
Python爬虫:教你四种姿势解析提取数据
|
一、分析网页
翻页查看url变化规律: 第1页:https://movie.douban.com/top250?start=0&filter= 第2页:https://movie.douban.com/top250?start=25&filter= 第3页:https://movie.douban.com/top250?start=50&filter= 第10页:https://movie.douban.com/top250?start=225&filter=start参数控制翻页,start = 25 * (page - 1)
正则表达式是一个特殊的字符序列,它能帮助你方便地检查一个字符串是否与某种模式匹配,常用于数据清洗,也可以顺便用于爬虫,从网页源代码文本中匹配出我们想要的数据。 re.findall 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。 注意:match和 search 是匹配一次;而 findall 匹配所有。 语法格式为:findall(string[, pos[, endpos]]) string : 待匹配的字符串;pos : 可选参数,指定字符串的起始位置,默认为 0;endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。 示例如下: import re text = """ |
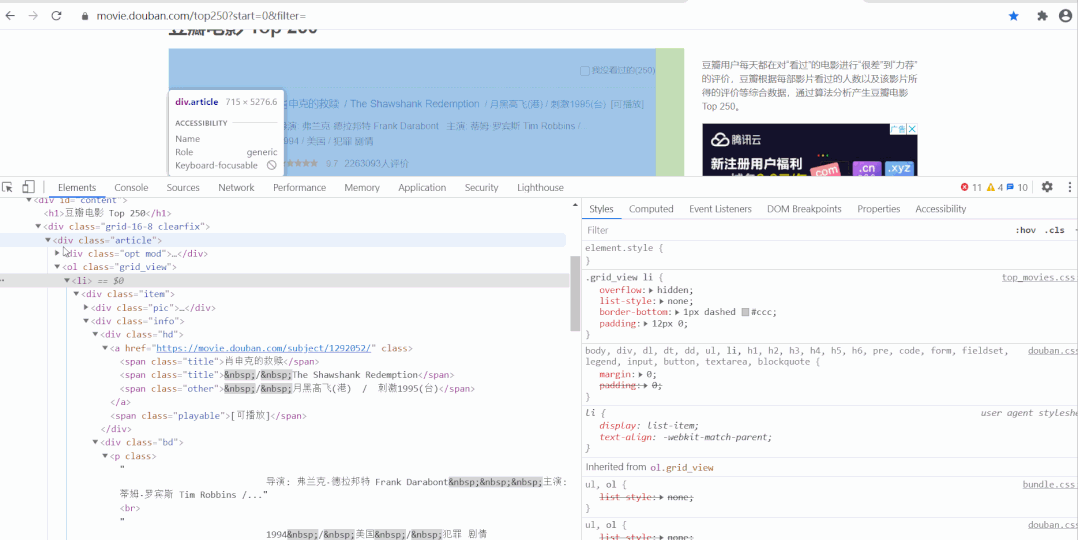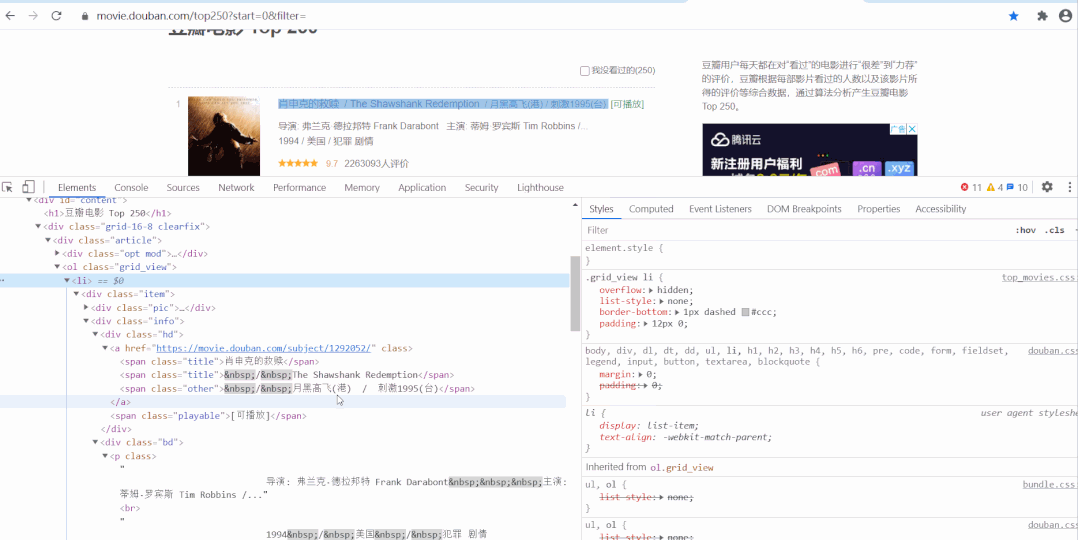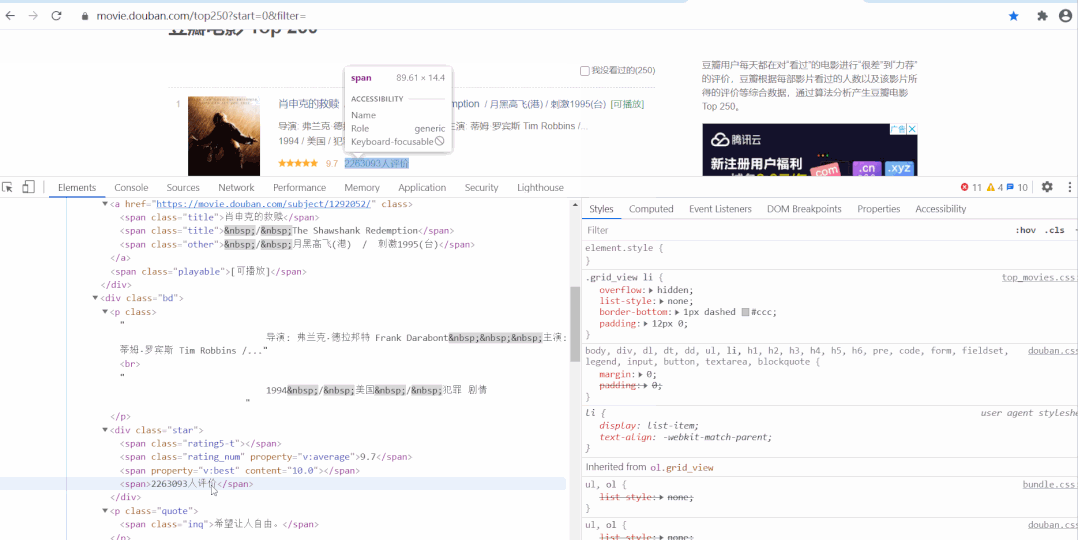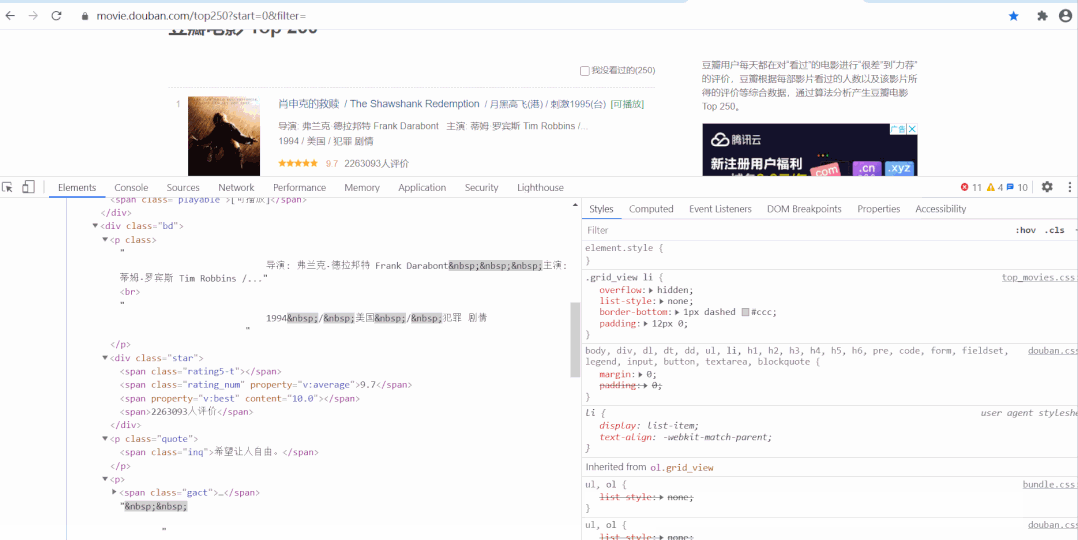 以经典的爬取豆瓣电影 Top250 信息为例。每条电影信息在 ol class 为 grid_view 下的 li 标签里,获取到所有 li 标签的内容,然后遍历,就可以从中提取出每一条电影的信息。
以经典的爬取豆瓣电影 Top250 信息为例。每条电影信息在 ol class 为 grid_view 下的 li 标签里,获取到所有 li 标签的内容,然后遍历,就可以从中提取出每一条电影的信息。 本文分别利用正则表达式、BeautifulSoup、PyQuery、Xpath来解析提取数据,并将豆瓣电影 Top250 信息保存到本地。
本文分别利用正则表达式、BeautifulSoup、PyQuery、Xpath来解析提取数据,并将豆瓣电影 Top250 信息保存到本地。【本文地址】
公司简介
联系我们