| Tesseract | 您所在的位置:网站首页 › 文字识别准确率 › Tesseract |
Tesseract
|
这里我是将图片 num1.jpg 放在了:D:\p我们需要在 cmd 进入此目录
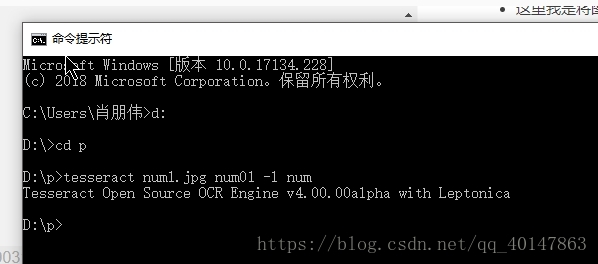
使用 cd 目录名 进入目录使用 cd.. 返回上一级目录使用 Tesseract 命令: 【注意】:语言参数要设置成 num,就是我们刚才拷贝的,没拷贝 num.trainddata 文件不能使用 tesseract 文件名 保存的txt文件名 例: tesseract num1.jpg num01 -l num 操作截图: 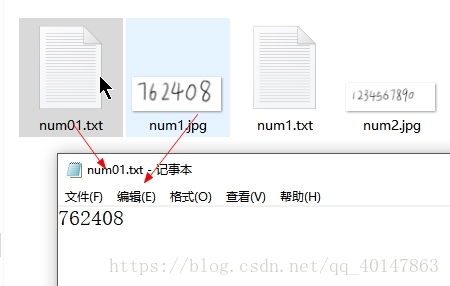 我们可以看到新生成的文件 num01 的内容为 762408,内容完全正确。细心的人会发现,最后一句指令,我们使用了指令[-l num]而不是[-l eng]。这说明,最后一次转换我们使用的是新生成的num语言的匹配库而不是默认的 eng 语言匹配库 我们可以看到,经过简单的训练,我们对于数字数据的转换准确率提高了很多 看到这里如果还没有安装工具,参考: Windows下 Tesseract-OCR 的安装与 环境变量配置本篇完善了很多细节,初学者也可以看懂,奉上 原文链接,拜拜 |
【本文地址】
公司简介
联系我们