| 新来个技术总监:谁再用 count(*) 查询记录数,以后就不用来了! | 您所在的位置:网站首页 › 文件格式无效是什么意思 › 新来个技术总监:谁再用 count(*) 查询记录数,以后就不用来了! |
新来个技术总监:谁再用 count(*) 查询记录数,以后就不用来了!
|
🐇 前言
最近我在公司优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助。 我们使用的数据库是Mysql8,使用的存储引擎是Innodb。这次优化除了优化索引之外,更多的是在优化count(*)。 通常情况下,分页接口一般会查询两次数据库,第一次是获取具体数据,第二次是获取总的记录行数,然后把结果整合之后,再返回。 查询具体数据的sql,比如是这样的: select id,name from user limit 1,20;它没有性能问题。 但另外一条使用count(*)查询总记录行数的sql,例如: select count(*) from user;却存在性能差的问题。 为什么会出现这种情况呢? 🐭 1、count(*)为什么性能差?在Mysql中,count(*)的作用是统计表中记录的总行数。 而count(*)的性能跟存储引擎有直接关系,并非所有的存储引擎,count(*)的性能都很差。 在Mysql中使用最多的存储引擎是:innodb和myisam。 在myisam中会把总行数保存到磁盘上,使用count(*)时,只需要返回那个数据即可,无需额外的计算,所以执行效率很高。 而innodb则不同,由于它支持事务,有MVCC(即多版本并发控制)的存在,在同一个时间点的不同事务中,同一条查询sql,返回的记录行数可能是不确定的。 在innodb使用count(*)时,需要从存储引擎中一行行的读出数据,然后累加起来,所以执行效率很低。 如果表中数据量小还好,一旦表中数据量很大,innodb存储引擎使用count(*)统计数据时,性能就会很差。 🐂 2 如何优化count(*)性能?从上面得知,既然count(*)存在性能问题,那么我们该如何优化呢? 我们可以从以下几个方面着手。 2.1 增加redis缓存 对于简单的count(*),比如:统计浏览总次数或者浏览总人数,我们可以直接将接口使用redis缓存起来,没必要实时统计。 当用户打开指定页面时,在缓存中每次都设置成count = count+1即可。 用户第一次访问页面时,redis中的count值设置成1。用户以后每访问一次页面,都让count加1,最后重新设置到redis中。 该场景无需从数据埋点表中使用count(*)实时统计数据,性能将会得到极大的提升。 不过在高并发的情况下,可能会存在缓存和数据库的数据不一致的问题。 但对于统计浏览总次数或者浏览总人数这种业务场景,对数据的准确性要求并不高,容忍数据不一致的情况存在。 2.2 加二级缓存 对于有些业务场景,新增数据很少,大部分是统计数量操作,而且查询条件很多。这时候使用传统的count(*)实时统计数据,性能肯定不会好。 假如在页面中可以通过id、name、状态、时间、来源等,一个或多个条件,统计品牌数量。 这种情况下用户的组合条件比较多,增加联合索引也没用,用户可以选择其中一个或者多个查询条件,有时候联合索引也会失效,只能尽量满足用户使用频率最高的条件增加索引。 也就是有些组合条件可以走索引,有些组合条件没法走索引,这些没法走索引的场景,该如何优化呢? 答:使用二级缓存。 二级缓存其实就是内存缓存。 我们可以使用caffine或者guava实现二级缓存的功能。 目前SpringBoot已经集成了caffine,使用起来非常方便。 只需在需要增加二级缓存的查询方法中,使用@Cacheable注解即可。 @Cacheable(value = "brand", , keyGenerator = "cacheKeyGenerator") public BrandModel getBrand(Condition condition) { return getBrandByCondition(condition); }然后自定义cacheKeyGenerator,用于指定缓存的key。 public class CacheKeyGenerator implements KeyGenerator { @Override public Object generate(Object target, Method method, Object... params) { return target.getClass().getSimpleName() + UNDERLINE + method.getName() + "," + StringUtils.arrayToDelimitedString(params, ","); } }这个key是由各个条件组合而成。 这样通过某个条件组合查询出品牌的数据之后,会把结果缓存到内存中,设置过期时间为5分钟。 后面用户在5分钟内,使用相同的条件,重新查询数据时,可以直接从二级缓存中查出数据,直接返回了。 这样能够极大的提示count(*)的查询效率。 但是如果使用二级缓存,可能存在不同的服务器上,数据不一样的情况。我们需要根据实际业务场景来选择,没法适用于所有业务场景。 2.3 多线程执行 不知道你有没有做过这样的需求:统计有效订单有多少,无效订单有多少。 这种情况一般需要写两条sql,统计有效订单的sql如下: select count(*) from order where status=1;统计无效订单的sql如下: select count(*) from order where status=0;但如果在一个接口中,同步执行这两条sql效率会非常低。 这时候,可以改成成一条sql: select count(*),status from order group by status;使用group by关键字分组统计相同status的数量,只会产生两条记录,一条记录是有效订单数量,另外一条记录是无效订单数量。 但有个问题:status字段只有1和0两个值,重复度很高,区分度非常低,不能走索引,会全表扫描,效率也不高。 还有其他的解决方案不? 答:使用多线程处理。 我们可以使用CompleteFuture使用两个线程异步调用统计有效订单的sql和统计无效订单的sql,最后汇总数据,这样能够提升查询接口的性能。 2.4 减少join的表 大部分的情况下,使用count(*)是为了实时统计总数量的。 但如果表本身的数据量不多,但join的表太多,也可能会影响count(*)的效率。 比如在查询商品信息时,需要根据商品名称、单位、品牌、分类等信息查询数据。 这时候写一条sql可以查出想要的数据,比如下面这样的: select count(*) from product p inner join unit u on p.unit_id = u.id inner join brand b on p.brand_id = b.id inner join category c on p.category_id = c.id where p.name='测试商品' and u.id=123 and b.id=124 and c.id=125;使用product表去join了unit、brand和category这三张表。 其实这些查询条件,在product表中都能查询出数据,没必要join额外的表。 我们可以把sql改成这样: select count(*) from product where name='测试商品' and unit_id=123 and brand_id=124 and category_id=125;在count(*)时只查product单表即可,去掉多余的表join,让查询效率可以提升不少。 2.5 改成ClickHouse 有些时候,join的表实在太多,没法去掉多余的join,该怎么办呢? 比如上面的例子中,查询商品信息时,需要根据商品名称、单位名称、品牌名称、分类名称等信息查询数据。 这时候根据product单表是没法查询出数据的,必须要去join:unit、brand和category这三张表,这时候该如何优化呢? 答:可以将数据保存到ClickHouse。 ClickHouse是基于列存储的数据库,不支持事务,查询性能非常高,号称查询十几亿的数据,能够秒级返回。 为了避免对业务代码的嵌入性,可以使用Canal监听Mysql的binlog日志。当product表有数据新增时,需要同时查询出单位、品牌和分类的数据,生成一个新的结果集,保存到ClickHouse当中。 查询数据时,从ClickHouse当中查询,这样使用count(*)的查询效率能够提升N倍。 需要特别提醒一下:使用ClickHouse时,新增数据不要太频繁,尽量批量插入数据。 其实如果查询条件非常多,使用ClickHouse也不是特别合适,这时候可以改成ElasticSearch,不过它跟Mysql一样,存在深分页问题。 |
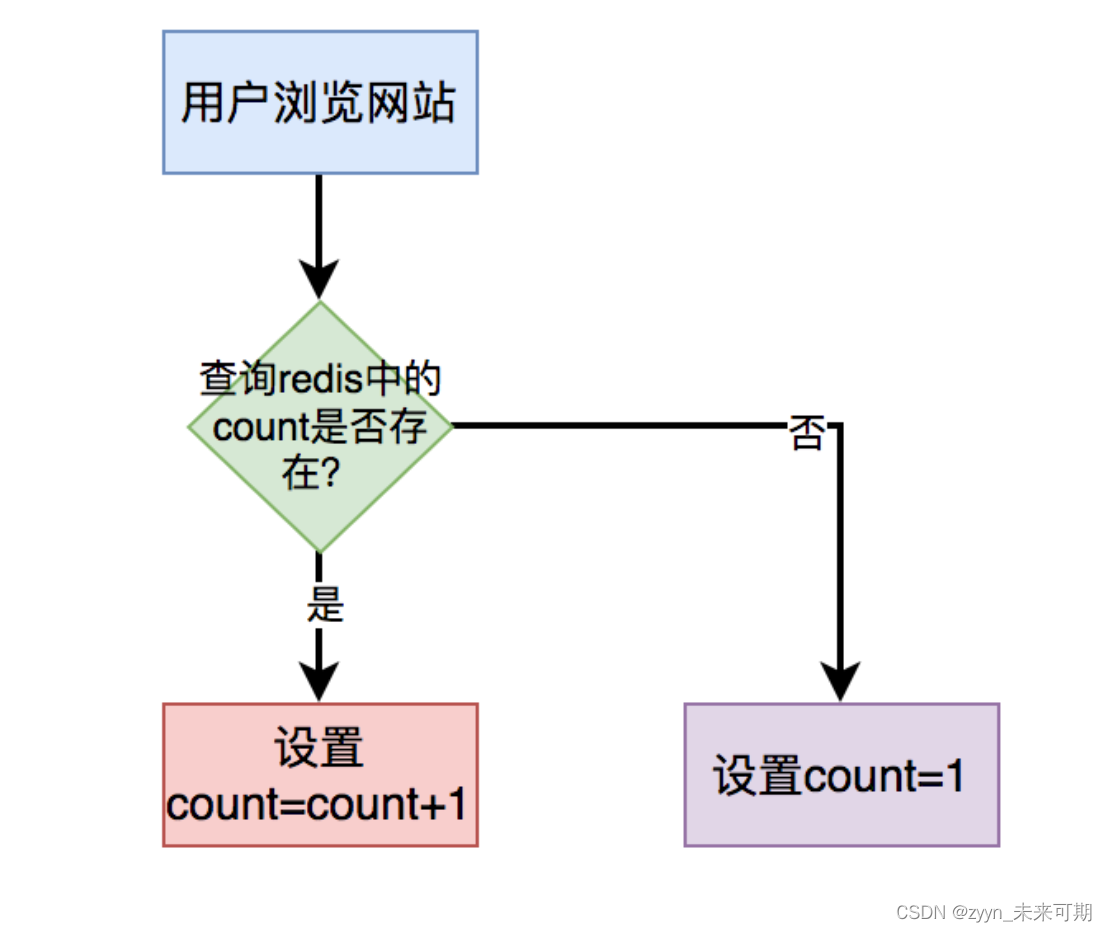 这样在需要展示数量的地方,从redis中查出count值返回即可。
这样在需要展示数量的地方,从redis中查出count值返回即可。【本文地址】