| 2019疫情海量数据挖掘分析与可视化实战(源码数据见附件) | 您所在的位置:网站首页 › 数据预处理实战总结报告 › 2019疫情海量数据挖掘分析与可视化实战(源码数据见附件) |
2019疫情海量数据挖掘分析与可视化实战(源码数据见附件)
|
实验总体要求如下: 所有流程附上处理代码和处理完成截图 数据预处理与导入1、2019_nCoV_data.csv是2020年1月-3月世界新冠疫情的数据,要求对2019_nCoV_data.csv进行数据预处理做以下操作,要求: 1.Sno编号列没有用,需要删除
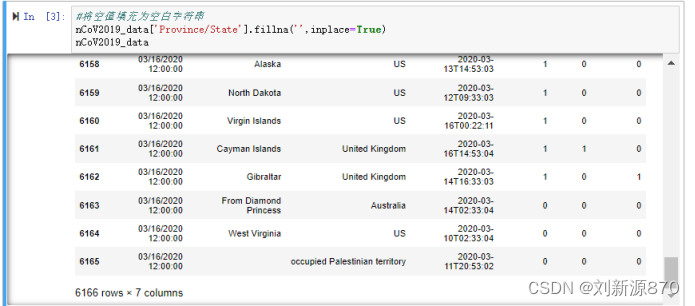
2.部分国家对应的地区为NAN,需要填充为空白字符串
3.部分国家/地区,受感染人数为0,也被列在表格中,需要删去 4.查看受影响的国家/地区的数量,Country一列中将'Mainland China', 'Hong Kong' , 'Macau', 'Taiwan' 等统一修正为'China';另外需将'Korea, South'改为'South Korea'。
1.由于数据国内省级行政区中香港、澳门、台湾的数据都是按省统计的,因此需要将这三个地区的province_confirmedCount、province_suspectedCount、province_curedCount、province_deadCount的数据赋值到city_confirmedCount、city_suspectedCount、city_curedCount、city_deadCount。
2.countryEnglishName一列中将 'HongKong' , 'Macao'等统一修正为'China'
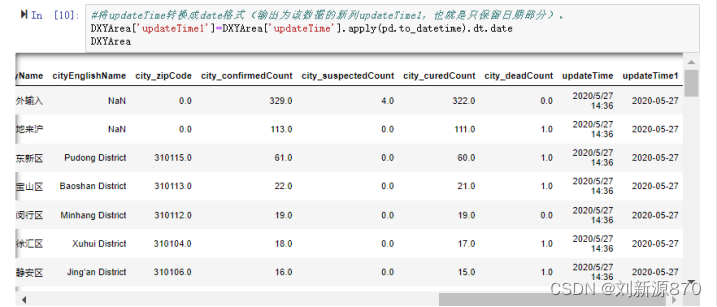
3.将updateTime转换成date格式(输出为该数据的新列updateTime1,也就是只保留日期部分)。
4.因为大部分城市都没有加“市”字,所以要把直辖市的下属区的“区”字去掉;还有一些没有变化规律的城市名字,可以通过city_rename的字典进行修改。
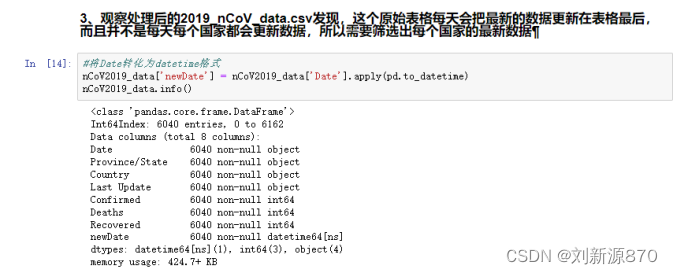
(1)将Date转化为datetime格式,方便操作后面进行时间的比较。
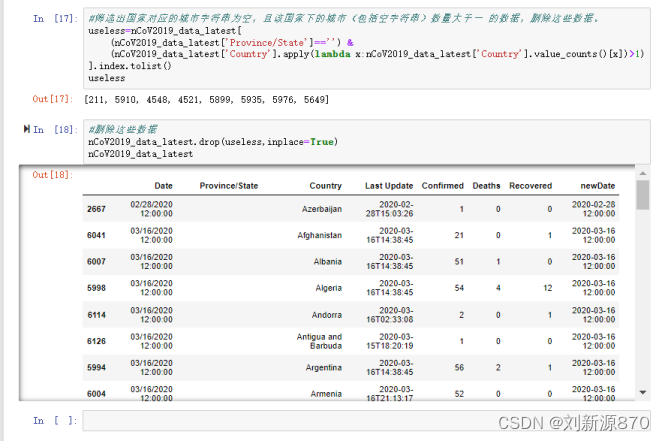
4、通过以上处理,经查看后又发现一个问题,比如Australia,一开始是以国家为单位报数据,之后又分成小区域报数据,会导致计算重复,所以要删除这部分数据;但也不能直接删,因为不知道有多少国家的数据有这个问题。 (3)筛选出国家对应的城市字符串为空,且该国家下的城市(包括空字符串)数量大于一 的数据,删除这些数据。
5、对预处理后的DXYArea.csv数据也需要进行最新数据提取工作
1.普通数据分析 1.根据2019_nCoV_data.csv预处理后的数据,查看2020年1月-3月最新数据中,除中国外世界各国总感染数据,找出前top10的国家
2.根据处理后的DXYArea.csv查看全国各省确诊病例数量,统计相关信息。 3.根据处理后的DXYArea.csv统计全国总体累计趋势。
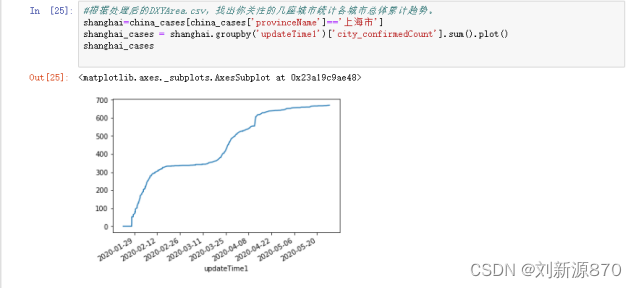
4.根据处理后的DXYArea.csv,找出你关注的几座城市统计各城市总体累计趋势。
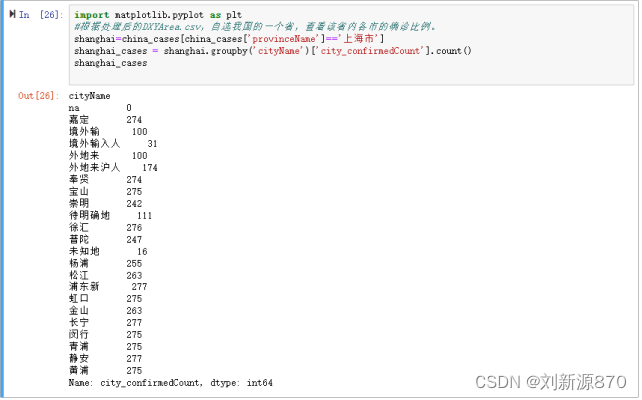
5.根据处理后的DXYArea.csv,自选我国的一个省,查看该省内各市的确诊比例。
6.根据处理后的DXYArea.csv,筛选除湖北省外其他各地区确诊病例数量,找出前top10的城市,统计相关信息。
7.筛选除湖北省外其他各省确诊病例数量,找出前top10的省份,统计相关信息。
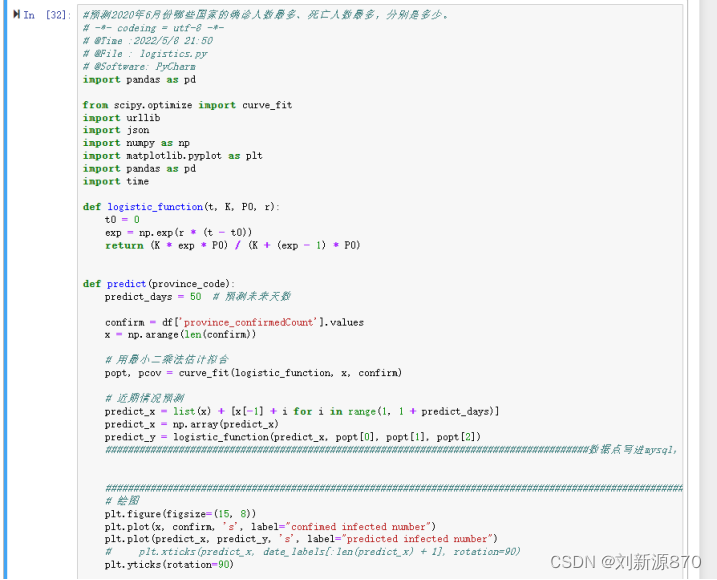
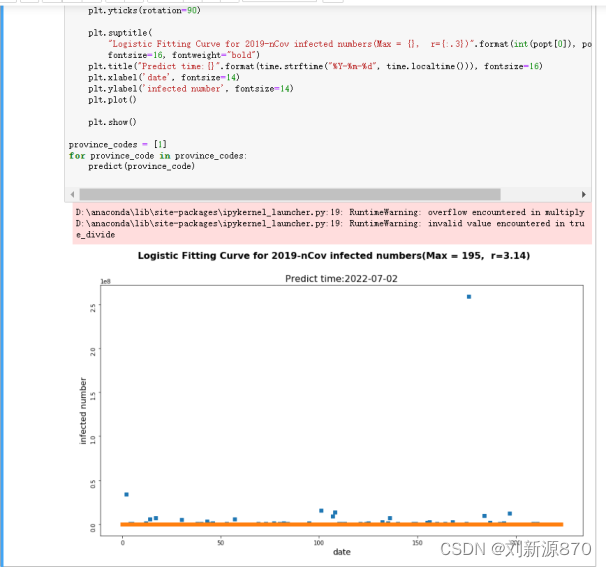
8.请预测2020年6月份哪些国家的确诊人数最多、死亡人数最多,分别是多少。
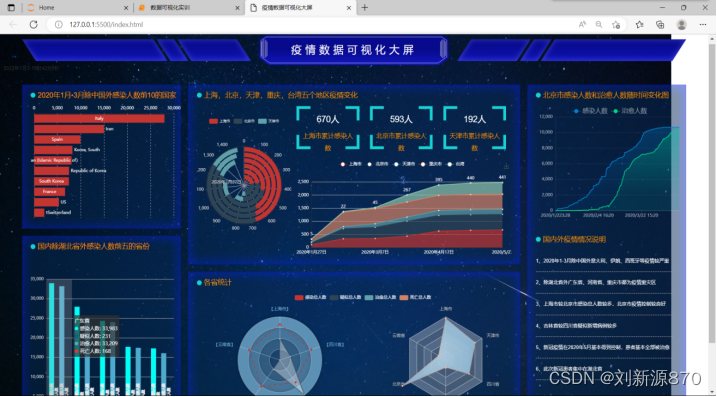
(1)选取6个及以上分析指标数据进行疫情数据可视化大屏制作; (2)利用Javaweb或Flask/Django框架等+Echarts实现以上可视化。
|













【本文地址】