| 【数据结构】十、图的存储方式以及BFS、DFS遍历算法 | 您所在的位置:网站首页 › 数据结构递归遍历算法 › 【数据结构】十、图的存储方式以及BFS、DFS遍历算法 |
【数据结构】十、图的存储方式以及BFS、DFS遍历算法
|
一、图的概念
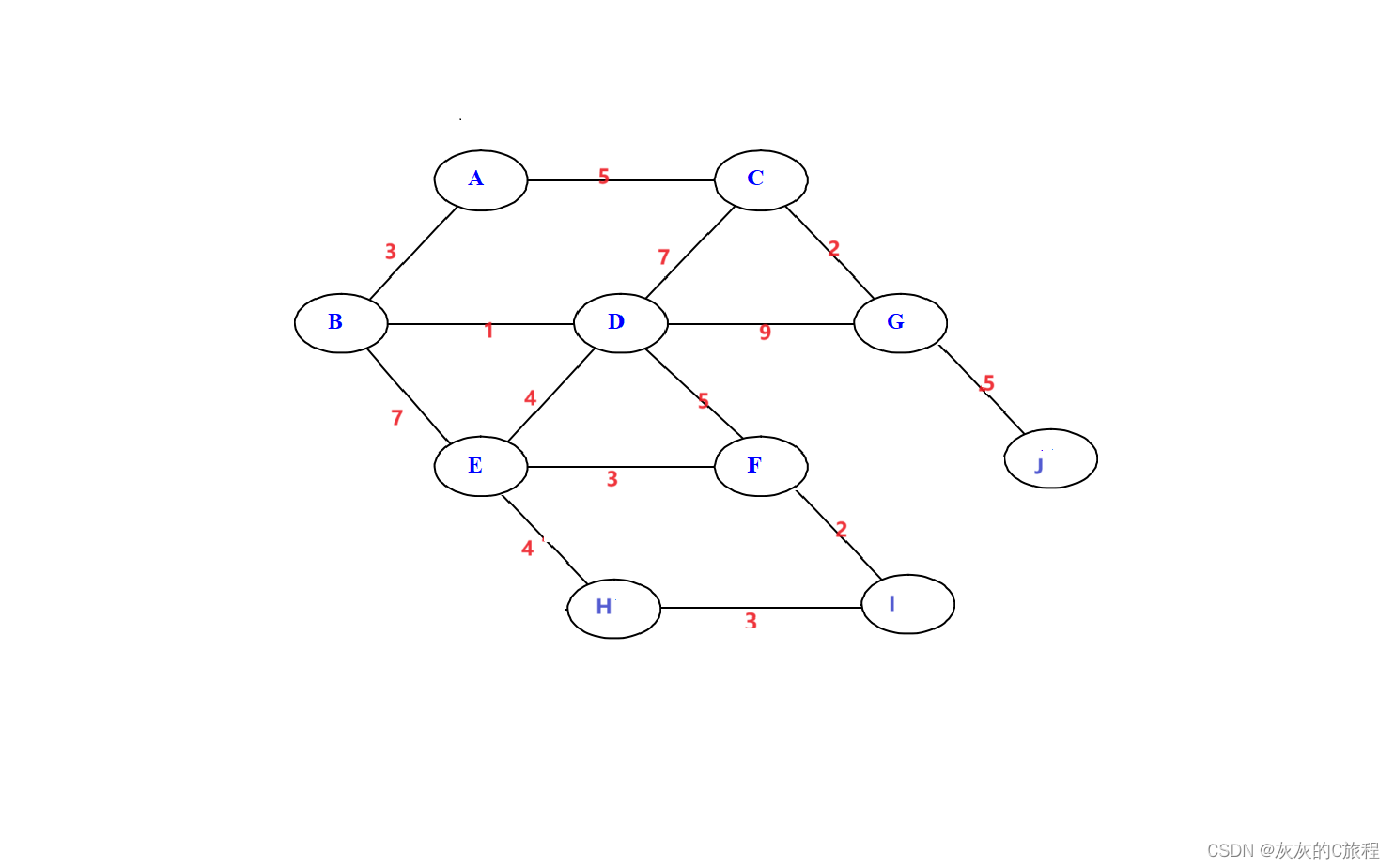
图具有非常复杂的数据结构,每个存储数据的结构称为节点,连接每个节点的结构称为边,这个边可以出现在任意的两个节点之间,并且这个边带有长度,称为权值,表示从一个节点到另一个节点需要付出的“代价”。 比如现在有一份地图,其中节点代表地点的名称,边代表连接两个顶点的路径,则权值表示两个地点之间的距离(km)。
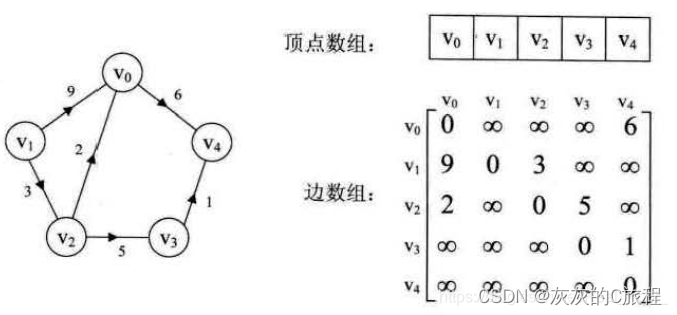
(这个图将作为本次的实验测试用图) 1)线性表、树、和图线性表的个数据之间只存在线性关系,每个元素只有一个前驱和一个后继; 树中不仅存在着线性关系,还存在着层次关系,每个元素有一个前驱但是可以有多个后继; 而在图中,数据之间的线性关系更为复杂,每个数据之间不仅可以有多个前驱,还可以有多个后继,任意两个元素之间都可能存在着关系。 2)图的分类按有无权值分,图可以分为带权图和不带权图。 按有无方向分,图可以分为又向图和无向图。本节我们主要讨论的是无向带权图。 二、图的存储方式 1)邻接矩阵法使用邻接矩阵存储,需要用到一个一维数组(用来存储节点)和一个二维数组(用来存储边) 如果是无向图,则边数组矩阵对称,如果是不带权图,边数组中使用1表示存在边。
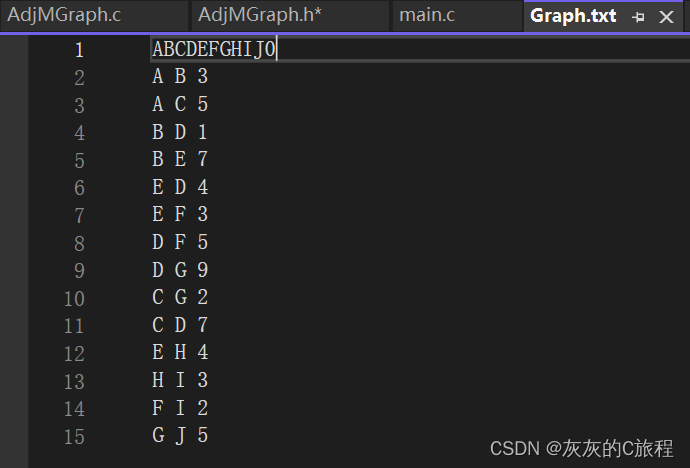
结构体定义为: typedef struct { LinList node; //存放节点 int num; //存放边的数目 int **edge; //存放边 }AdjMGraph; //邻接矩阵结构体 typedef struct { int list[MaxSize]; //使用数组来存储元素 int size; //记录存储的元素个数 }LinList;这里的LinList是一个线性表,其基本操作和函数可跳转: 【数据结构】一、线性表-CSDN博客 Question:对于现有的一个图,我们要这么保存到这个结构体里面呢? 下面提供一个方法:将图的数据保存到文件中,再通过读取文件的方式逐顶点逐边存入图结构体。 文件中的数据:
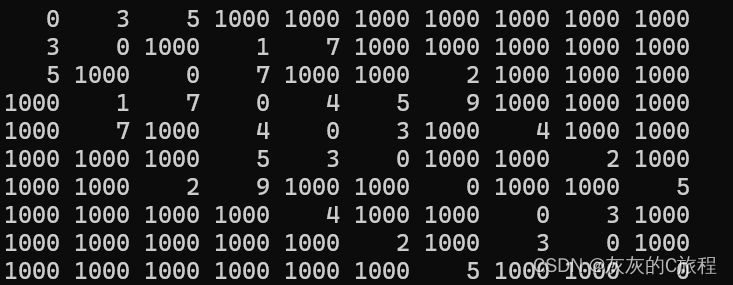
其中第一行代表顶点的数据,0为结束位,其后每一行代表边的弧头弧尾和权值,代码实现如下: #define MAXWEIGHT 1000 //表示无穷大 /* * @brief 初始化邻阶矩阵 * @param 图结构体的地址 * @return None */ static void AdjM_Init(AdjMGraph* G) { G->num = 0; LinearList_Init(&G->node); } /* * @brief 从文件中读取,使用邻接矩阵存储 */ void AdjM_Creat(AdjMGraph *G) { AdjM_Init(G); //初始化节点线性表 FILE* fp = fopen("Graph.txt", "r"); //打开文件 if (fp == NULL) { perror("fopen"); return 1; } char ch; //逐字节读取节点 while (ch = fgetc(fp)) { if (ch == '0') break; LinearList_Insert(&G->node, G->node.size, ch); //插入到线性表中 } int len = G->node.size; //根据读取到的节点的数目,分配邻接矩阵内存 G->edge = (int**)calloc(len, sizeof(int*)); if (G->edge == NULL) { printf("内存分配失败!1\n"); return; } for (int i = 0; i < len; i++) { G->edge[i] = (int*)calloc(len , sizeof(int)); if (G->edge[i] == NULL) { printf("内存分配失败!\n"); return; } } for (int i = 0; i < len; i++) //初始化邻接矩阵 { for (int j = 0; j < len; j++) { G->edge[i][j] = (i == j) ? 0 : MAXWEIGHT; } } char start, end; int weight; while (fscanf(fp, "\n%c %c %d", &start, &end, &weight) == 3) //输入边的数据 { G->edge[start - 'A'][end - 'A'] = weight; G->edge[end - 'A'][start - 'A'] = weight; G->num += 2; }//因为我们的节点使用大写字母表示,从文件中读取后转换成存储到线性表的下标中 fclose(fp); fp = NULL; } //打印邻接矩阵 void AdjM_Print(AdjMGraph G) { for (int i = 0; i < G.node.size; i++) { for (int j = 0; j < G.node.size; j++) { printf("%4d ", G.edge[i][j]); } printf("\n"); } }输出结果如下:
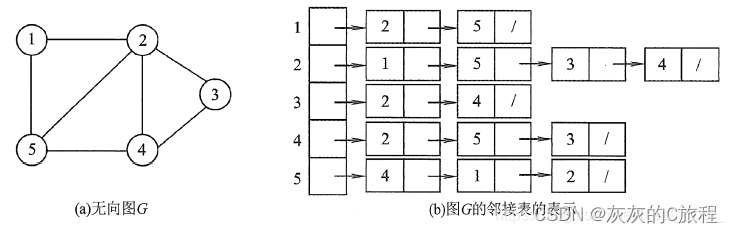
邻接表中使用一个数组来存储节点(如下图左边的一列),数组的类型为一个结构体,包括节点的数据和一个链表指针,与该顶点相连的节点通过链表引出,每个链表节点包含了节点序列、与顶点相连的边的权值和指向与顶点相连的下一个顶点的指针。
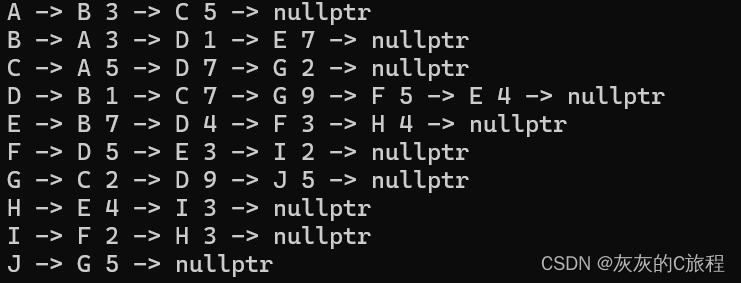
结构体定义: typedef struct EdgeList{ char end_node; //指向的节点 int weight; //边的权重 struct EdgeList* next; //指针域 }EdgeList_t; //边结构体 typedef struct NodeList{ char start_node; //该顶点的数据 EdgeList_t* edge; //该顶点所连接的定点链表 }NodeList_t; //顶点结构体 typedef struct { NodeList_t* node; //节点数组 int edgenum,nodenum; //顶点和边的个数 }AdjAGraph; //邻接表结构体这个结构体比较复杂,我来解释一下: 第一个结构体表示链表的一个节点; 第二个结构体表示一个顶点和与它相连的顶点组成的一条链表; 第三个结构体表示节点的数组,此外还加上了顶点和边的个数计数。 Question:这里介绍另一种输入图的方法:手动键盘输入,使用邻接表存储 static void AdjA_Init(AdjAGraph* G) { G->edgenum = G->nodenum = 0; G->node = NULL; } //手动输入图表数据 //先输入一个顶点,然后输入该顶点所连接的顶点和他们的边的权值,输入0表示结束 void AdjA_Creat(AdjAGraph* G) { AdjA_Init(G); G->node = (NodeList_t*)calloc(10, sizeof(NodeList_t)); //开辟十个节点的内存 if (G->node == NULL) return; char ch1,ch2; //顶点 int weight = 0; //权值 for (int i = 0; i < 10; i++) { while (scanf("%c", &ch1) != EOF) //限制节点使用大写字母表示,避免空格、回车等字符造成影响 { if ((ch1 >= 'A' && ch1 node[i].start_node = ch1; G->node[i].edge = (EdgeList_t*)calloc(1, sizeof(EdgeList_t)); if (G->node[i].edge == NULL) return; else G->node[i].edge->next = NULL; G->nodenum++; //添加节点并初始化 while (1) { while (scanf("%c", &ch2) != EOF) { if ((ch2 >= 'A' && ch2 end_node = ch2; newedge->weight = weight; newedge->next = NULL; } //添加到链表中 EdgeList_t* k = G->node[i].edge; while (k->next != NULL) { k = k->next; } k->next = newedge; G->edgenum++; //添加边 } } } //输入样例: A B 3 C 5 0 B A 3 D 1 E 7 0 C A 5 D 7 G 2 0 D B 1 C 7 G 9 F 5 E 4 0 E B 7 D 4 F 3 H 4 0 F D 5 E 3 I 2 0 G C 2 D 9 J 5 0 H E 4 I 3 0 I F 2 H 3 0 J G 5 0 0 //打印邻接表 void AdjA_Print(AdjAGraph G) { for (int i = 0; i < G.nodenum; i++) { printf("%c -> ", G.node[i].start_node); EdgeList_t* p = G.node[i].edge->next; while (p != NULL) { printf("%c %d -> ", p->end_node, p->weight); p = p->next; } printf("nullptr\n"); } }打印结果如下:
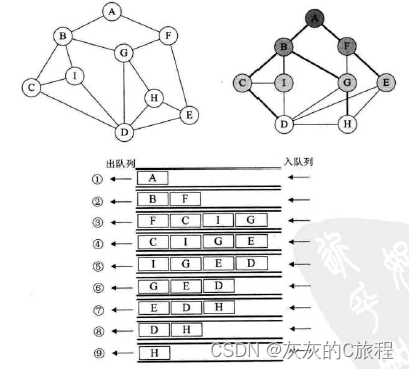
图的遍历方式分为深度优先算法(DFS)和广度优先算法(BFS),其中深度优先算法类似于树的前序遍历,使用递归实现,广度优先算法类似于树的层序遍历,使用队列实现。 tip:以下的遍历均以邻接矩阵为例。 1)深度优先算法(DFS算法)算法思想: 访问顶点v并标记顶点v已访问; 查找顶点v的第一个邻接顶点w; 若w存在,则继续执行,否则算法结束; 若顶点w未访问,则访问w,递归到第一步; 查找v的w顶点的下一个邻接顶点,转到第三步。 //深度优先算法 void DFS(AdjMGraph G, int v, int visit[]) { Visit(G.node.list[v]); //访问该顶点 visit[v] = 1; //标记已访问 for (int i = 0; i < G.node.size; ++i) { if (G.edge[v][i] != MAXWEIGHT && G.edge[v][i] != 0 && visit[i] != 1) { //寻找存在且未访问的 DFS(G, i, visit); //递归 } } } 2)广度优先算法(BFS算法)算法思想:(出入队列的都是存储节点的数组代表节点的下标) 访问初始顶点v并标记访问,v入队列; 若队列非空,则继续执行,否则算法结束; 队头顶点出队列,并访问; 将队头的顶点的所有未被访问的邻接顶点入队列; 最后感谢你观看完我的文章,如果文章对你有帮助,可以点赞收藏评论,这是对作者最好的鼓励!不胜感激🥰🥰 |
【本文地址】