| 一篇文章搞懂数据仓库:常用ETL工具、方法 | 您所在的位置:网站首页 › 数据抽取算法包括哪些 › 一篇文章搞懂数据仓库:常用ETL工具、方法 |
一篇文章搞懂数据仓库:常用ETL工具、方法
|
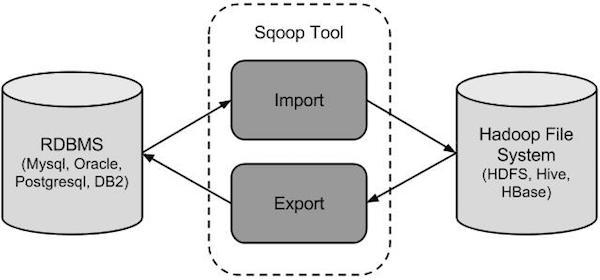
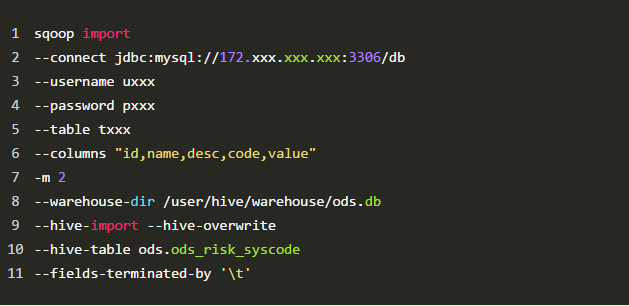
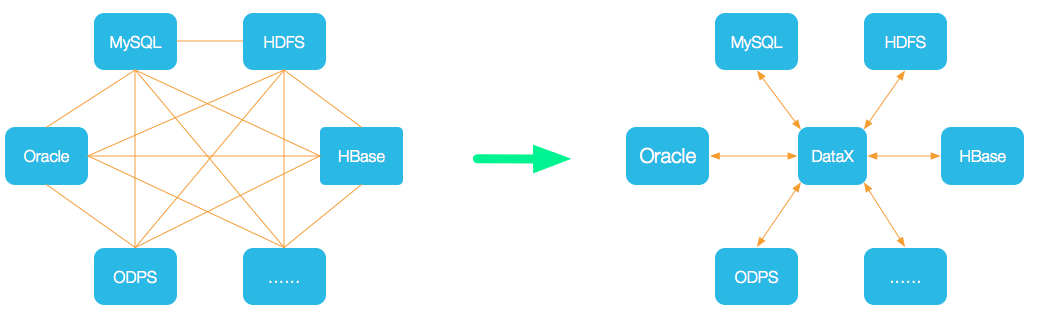
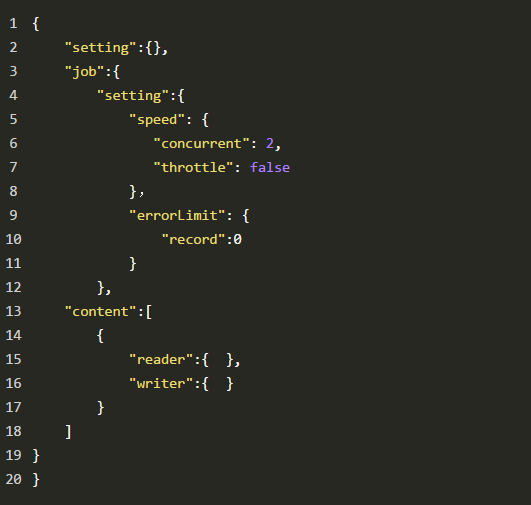
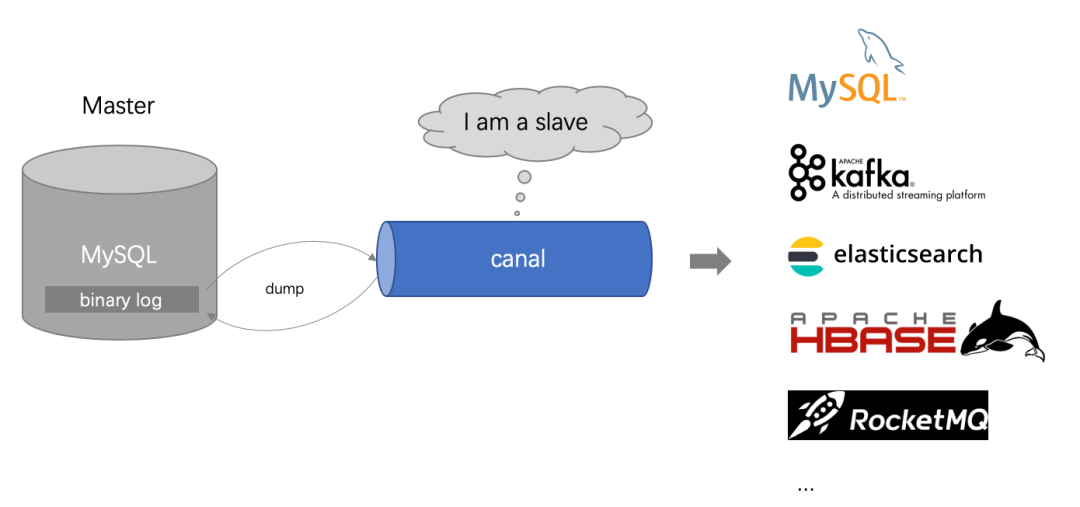
目录 一、什么是ETL? 二、ETL & ELT 三、常用的ETL工具 3.1 sqoop 3.2 DataX 3.3 Kettle 3.4 canal 3.5 StreamSets 四、ETL加载策略 4.1 增量 4.2 全量 4.3 流式 小编有话 一、什么是ETL?ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,是数据仓库的生命线。 抽取(Extract)主要是针对各个业务系统及不同服务器的分散数据,充分理解数据定义后,规划需要的数据源及数据定义,制定可操作的数据源,制定增量抽取和缓慢渐变的规则。 转换(transform)主要是针对数据仓库建立的模型,通过一系列的转换来实现将数据从业务模型到分析模型,通过ETL工具可视化拖拽操作可以直接使用标准的内置代码片段功能、自定义脚本、函数、存储过程以及其他的扩展方式,实现了各种复杂的转换,并且支持自动分析日志,清楚的监控数据转换的状态并优化分析模型。 装载(Load)主要是将经过转换的数据装载到数据仓库里面,可以通过直连数据库的方式来进行数据装载,可以充分体现高效性。在应用的时候可以随时调整数据抽取工作的运行方式,可以灵活的集成到其他管理系统中。 二、ETL & ELT伴随着数据仓库的发展(传送门:数据仓库的八个发展阶段),数据量从小到大,数据实时性从T+1到准实时、实时,ETL也在不断演进。 在传统数仓中,数据量小,计算逻辑相对简单,我们可以直接用ETL工具实现数据转换(T),转换之后再加载到目标库,即(Extract-Transform-Load)。但在大数据场景下,数据量越大越大,计算逻辑愈发复杂,数据清洗需放在运算能力更强的分布式计算引擎中完成,ETL也就变成了ELT(Extract-Load-Transform)。 即:Extract-Transform-Load >> Extract-Load-Transform 通常我们所说的ETL,已经泛指数据同步、数据清洗全过程,而不仅限于数据的抽取-转换-加载。 三、常用的ETL工具下面小编将介绍几类ETL工具(sqoop,DataX,Kettle,canal,StreamSets)。 3.1 sqoop 是Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。sqoop命令的本质是转化为MapReduce程序。sqoop分为导入(import)和导出(export),策略分为table和query模式分为增量和全量。
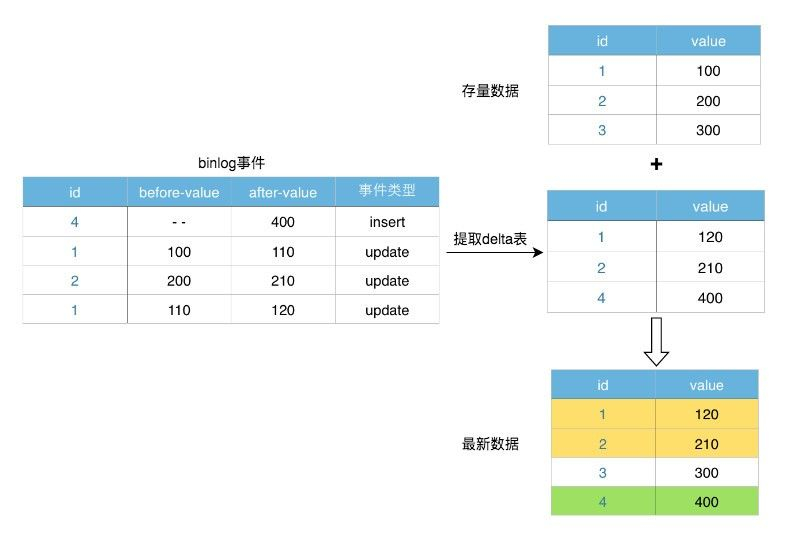
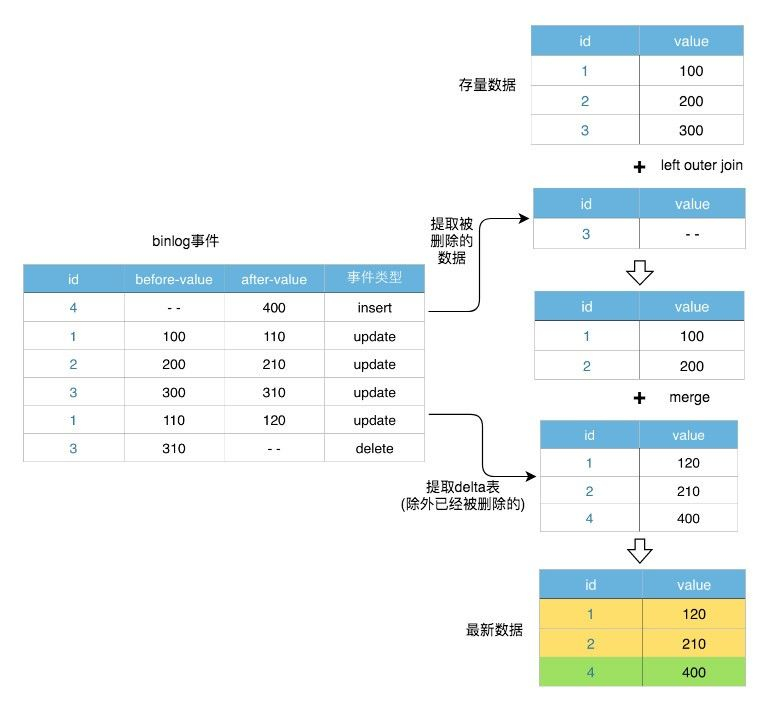
新增+删除 history-table Left join delet-table where delect-table.value is null == 表a表a full join update-table (能拿update就拿update)
每天一个全量表,也可一个hive天分区一个全量。 4.3 流式使用kafka,消费mysql binlog日志到目标库,源表和目标库是1:1的镜像。 小编有话无论是全量还是增量的方式,都会浪费多余的存储或通过计算去重,得到最新的全量数据。为解决这一问题,墙裂建议kafka的数据同步方案,源表变化一条,目标表消费一条,目标表数据始终是一份最新全量数据,且为实时同步的。 ps.极端情况下可能会丢数,需要写几个监控监本(详见数据质量篇)和补数脚本即可~
数仓系列传送门:https://blog.csdn.net/weixin_39032019/category_8871528.html |

【本文地址】