| 数据包络分析(DEA)笔记 | 您所在的位置:网站首页 › 数据包络模型采用的是非线性规划的方法 › 数据包络分析(DEA)笔记 |
数据包络分析(DEA)笔记
|
摘自百度百科:数据包络分析(Data envelopment analysis,DEA)是运筹学和研究经济生产边界的一种方法。该方法一般被用来测量一些决策部门的生产效率。 数据包络分析是一种对具有相同类型的多投入多产出决策进行绩效评价的方法,每一种多投入多产出的决策称为一个决策单元。 1.决策单元 (Decision Making Units, DMU)决策单元是指可以将一定的输入转化为相应的产出的运营实体,并且每一个决策单元都有m种输入和s种输出,用X表示第j个决策单元的投入,用Y表示第j个决策单元的产出,其投入-产出可能集满足凸性、无效性、锥性、最小性四个公理。 对决策单元的理解:用效率(用)评估其好坏,产出越大越好,投入越节省越好 只有同类型的决策单元才可以相互比较,省级和市级无法比较,第一产业与二三产业无法比较,决策单元之间的比较是相对的。 2.效率前沿(Efficient Frontier)来看一个单投入多产出的图:
类似这样的一个线(好丑的图):
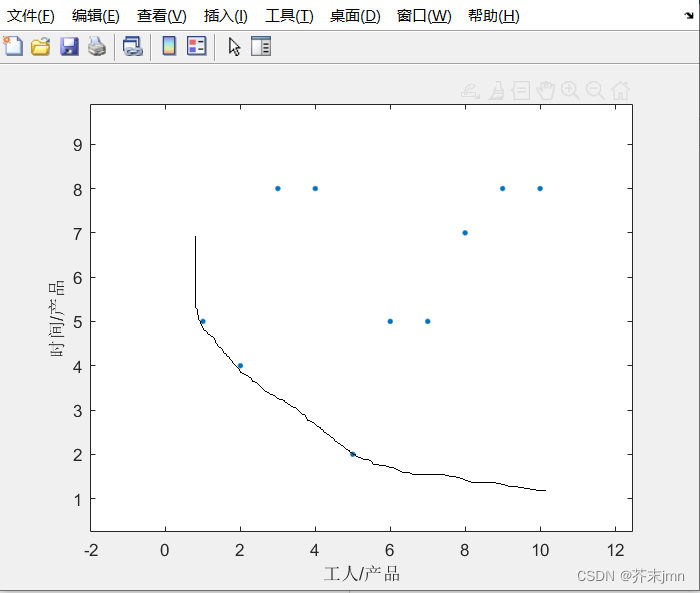
再看一个两投入单产出的图: 这里面x1、x2是工人和时间,产出y是产品,单位产品花费时间和花费工人数肯定是越小越好,这样又得到一种效率前沿面:
这就引申出了CCR模型和BCC模型 此外,DMU的个数一定要满足条件:
你的决策单元放少了会导致在你的效率前沿上的点的数量占总数比非常大。 数据包络分析所适应的场景十分局限,但它正好能够十分契合一个在做课题是与队友讨论了很长时间的点(影响因素分析)。 个人认为MATLAB代码的实现比python代码的实现简单一些,确定决策单元效率评价指数
u、v分别是产出组合和投入组合的权重系数。选择合适的u、v,目的是将效率评价指数收束在0~1之间。原本认为选择u、v会是个很麻烦的步骤,但是实际上u、v的选择不用自己求,有点像是在做归一化(因为是线性规划问题),它虽然叫权重,但并不影响投入产出组合的效率前沿线的划分,即效率前沿线上存在哪些决策单元。 不用自己选择权重看起来很神奇,可以直接用MATLAB中的linprog函数完成此步骤 CCR模型CCR模型假设DMU处于固定规模报酬情形下,用来衡量总效率,是一种得到单个决策单元最优效率下的各个输出量与输入量的最佳权重的模型。 固定规模报酬是经济学术语,指在其他条件不变的情况下,企业内部各种生产要素按相同比例变化时所带来的产量变化。 给出约束条件形成线性规划问题:
其中p、q分别是投入指标个数和产出指标个数。 BCC模型BCC模型假设DMU处于变动规模报酬情形下,比较多产出组合的达成情况,用来衡量纯技术和规模效率,研究多投入情形下的资源配置,在CCR模型基础上改进即可。
尚在学习,望不吝指教。 |
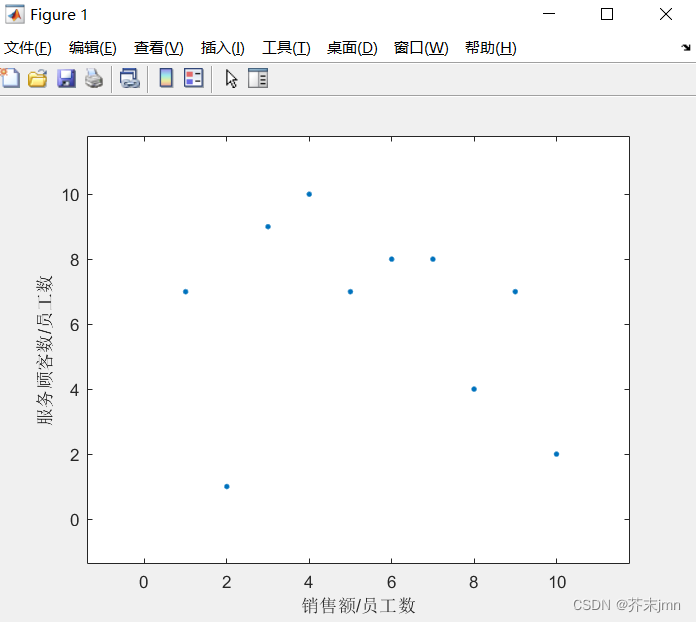 图中决策单元有两个指标,有些点指标1大而指标2小,我们无法明确决策出最优指标,我们构造一个效率前沿,表示效率前沿上我们的投入在多产出中的相对效率是最大的。
图中决策单元有两个指标,有些点指标1大而指标2小,我们无法明确决策出最优指标,我们构造一个效率前沿,表示效率前沿上我们的投入在多产出中的相对效率是最大的。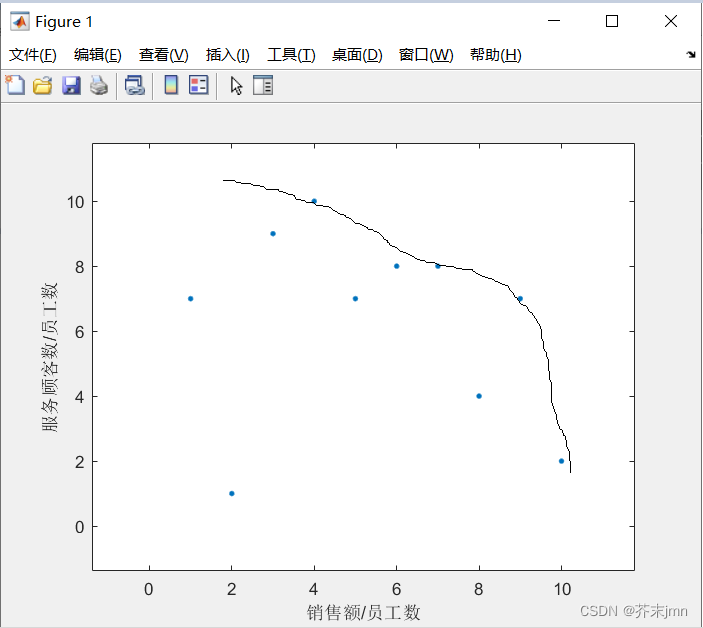 横纵坐标是学习时看到的某个例子,但是我觉得作为一个单投入的模型,对一个店来说大部分情况都是销售额越大越好才对,也就是关注x轴就行了。服务顾客数这种赚店面口碑的数据仿佛就代入了时间序列的考究,与数据包络分析关联性是不大的,个人理解不应该拿来和销售额/员工数放一块抢权重。
横纵坐标是学习时看到的某个例子,但是我觉得作为一个单投入的模型,对一个店来说大部分情况都是销售额越大越好才对,也就是关注x轴就行了。服务顾客数这种赚店面口碑的数据仿佛就代入了时间序列的考究,与数据包络分析关联性是不大的,个人理解不应该拿来和销售额/员工数放一块抢权重。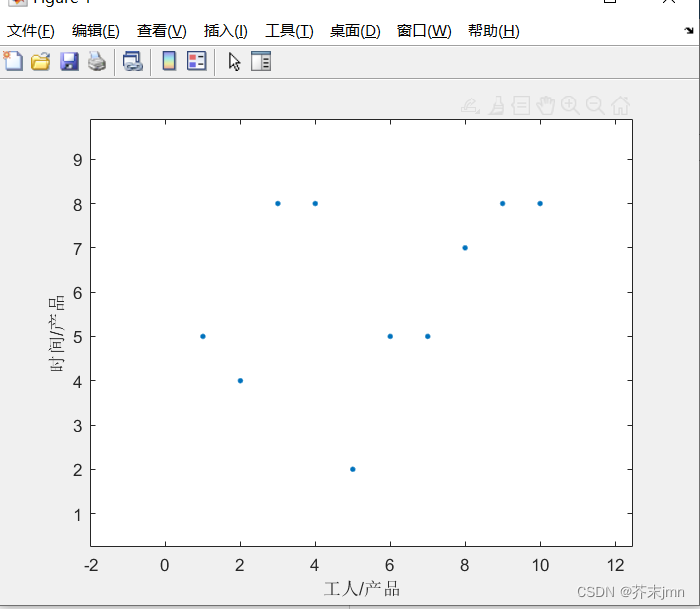
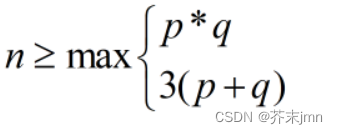
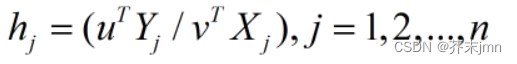
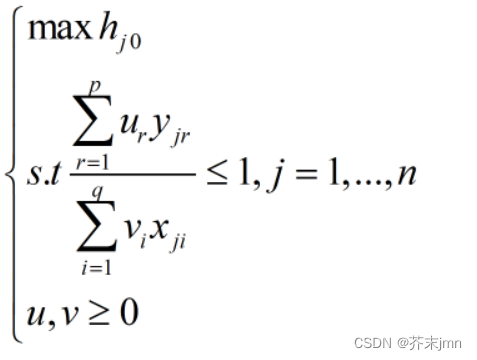
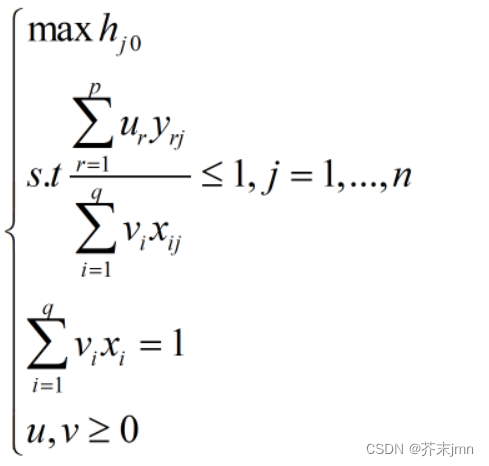
【本文地址】