| svm原理详细推导 | 您所在的位置:网站首页 › 数学公式的推导方法总结 › svm原理详细推导 |
svm原理详细推导
|
笔者在查阅了大量资料和阅读大佬的讲解之后,终于对svm有了比较深一点的认识,先将理解的推导过程分享如下:
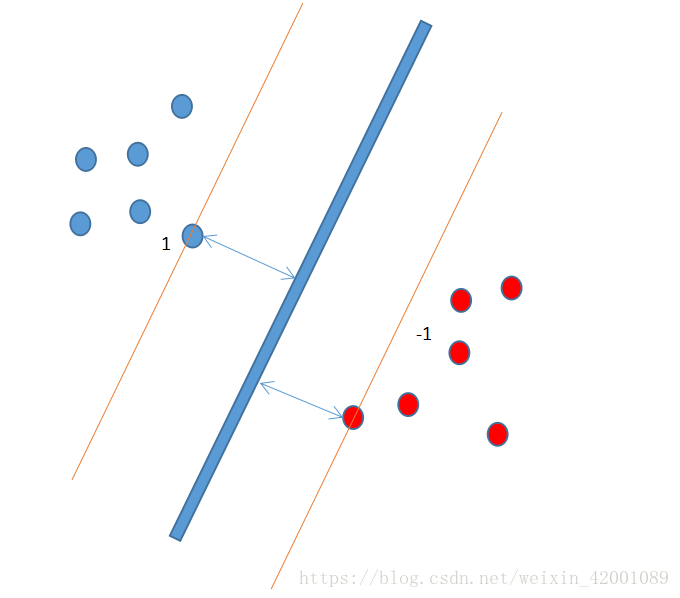
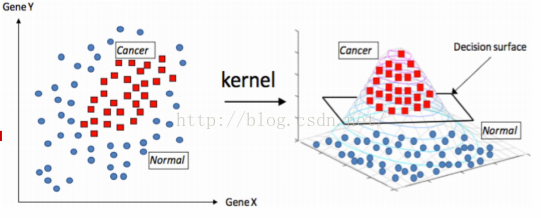
本文主要从如下五个方面进行介绍:基本推导,松弛因子,核函数,SMO算法,小结五个方面以%%为分隔,同时有些地方需要解释或者注意一下即在画有---------符号的部分内。 本文主要介绍的是理论,并没有涉及到代码,关于代码的具体实现,可以在阅读完本文,掌握了SVM算法的核心内容后去看一下笔者另一篇SVM代码剖析: https://blog.csdn.net/weixin_42001089/article/details/83420109 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 基本推导 svm原理并不难理解,其可以归结为一句话,就是最大化离超平面最近点(支持向量)到该平面的距离。 如下图-------------------------------------------------------------------------------------------------------------------------------------------------------------------- 这里简单介绍一下kkt和拉格朗日乘子法(一般是用来求解最小值的优化问题的) 在求优化问题的时候,可以分为有约束和无约束两种情况。 针对有约束的情况又有两种情况即约束条件是等式或者是不等式 当是等式的时候: 首先写出其拉格朗日函数: 需满足的条件是: 而当约束条件是不等式时,便可以使用kkt条件,其实kkt条件就是拉格朗日乘子法的泛化 同理首先写出拉格朗日函数: 好了,接着往下走介绍拉格朗日对偶性: 上面问题可以转化为(称为原始问题): 为什么可以转化呢?这里是最难理解的:笔者还没有完全透彻的理解,这里试着解释一下吧,也是网上最流行的解释方法: 这里分两种情况进行讨论: 当g(x)或者h(x)不满足约束条件时: 那么显然: 当g(x)或者h(x)满足约束条件时: 综上所述: 所以如果考虑极小值问题那么就可以转化为: 还有一种比较直观的方法,这里不再证明,可以参考:如何通俗地讲解对偶问题?尤其是拉格朗日对偶lagrangian duality? - 知乎第二个回答 对偶问题: 上面关于拉格朗日最小最大值问题可以转化为求其对偶问题解决: 两者关系: 假设原始问题的最优解是 即其对偶问题的解小于等于原始问题的解,现在我们要通过其对偶问题来求的原始问题的解对吧,所以我们希望的是 那么什么时候才能相等呢?这就必须满足的kkt条件: ----------------------------------------------------------------------------------------------------------------------------------------------------------------- 说了这么多拉格朗日的东西,其实其本质作用就是,将有不等式约束问题转化为无约束问题(极小极大值问题),然后又进一步在满足kkt条件下将问题转化为了其对偶问题,使之更容易求解,下面要用到的就是上面紫色的部分,关于更深的拉格朗日求解问题大家可以去收集资料参看。 对应到SVM的拉格朗日函数便是:----------------------------------------------------------------------------------------------------------------------------------------------------------- 注意上面给的不等式约束是 ---------------------------------------------------------------------------------------------------------------------------------------------------------- 于是问题转化为:%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 松弛因子 上面是SVM最基本的推导,下面说一下这种情况就是有一个点由于采集错误或者其他原因,导致其位置落在了别的离别当中,而svm是找最近的点,所以这时候找出的超平面就会过拟合,解决的办法就是忽略掉这些点(离群点),即假如松弛因子这里简单来理解一些C的含义:这是一个在使用SVM时需要调的参数, 令 --------------------------------------------------------------------------------------------------------------------------------------------------------------------- 这里得到的和没加松弛变量时是一样的 ------------------------------------------------------------------------------------------------------------------------------------------------ 对应的kkt条件为:注意如下几点: 一:对比最开始的kkt条件模板这里的(1)(8)(9)是求偏导的结果即一二三公式,(6)(7)是拉格朗日乘子即相当于模板的第五公式,(2)(4)相当于模板第六个公式,(3)(5)是原始约束条件即相当于模板的第七个公式 二:可以将kkt中部分条件进行总结归纳:(6)(7)(8)三个条件:可以看到这里和没加松弛变量相比,唯一不同的就是 对比模板 当 当 由(8)可得: 又有公式(4)可得: 最后又公式(3)可得: 同理 又(2)可得: 最后: 进而这里还是只能得到 最后: 在点在两条间隔线外则,对应前面的系数 通过上面也可以看出,最后求出的所有 1首先根据上面的最优化问题求出一些列的 2然后求出w和b 注意这里是随便取一个点i就可以算出b,但是实际中往往取所有点的平均 3得出超平面 注意这里说一下 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 核函数: 出现的背景: 对于一些线性不可分的情况,比如一些数据混合在一起,我们可以将数据先映射到高纬,然后在使用svm找到当前高纬度的超平面,进而将数据进行有效的分离,一个直观的例子:图片来源七月算法 比如原来是:(1)线性核函数 :也是首选的用来测试效果的核函数
总的来说就是,当样本足够多时,维度也足够高即本身维度已经满足线性可分,那么可以考虑使用线性核函数,当样本足够多但是维度不高时,可以考虑认为的增加一定的维度,再使用线性核函数,当样本也不多,维度也不高时,这时候可以考虑使用高斯(RBF)核函数。 关于SVM ,python中有一个机器学习库sklearn,其中集成了很多机器学习方法,包括SVM,笔者这里也做过一个简单直观的调用,可以参看python_sklearn机器学习算法系列之SVM支持向量机算法_爱吃火锅的博客-CSDN博客 再者就是我们虽然可以直接拿sklearn库下集成好的接口来用,但是其具体实现细节,还是有必要了解一下,换句话说: 上面我们最后得到的结果是: 我们求出一些列 -------------------------------------------------------------------------------------------------------------------------------------------------------------- 为什么是二元一次方程呢?很简单由原始优化目标可以看出基本单元就是 ------------------------------------------------------------------------------------------------------------------------------------------------------------- 好啦,求一元二次方程最值应该很简单啦吧,即:------------------------------------------------------------------------------------------------------------------------------------------------------------- 介绍到这里也许会发现还有一个约束条件没有用即: 是的我们在算 回到: 我们分类讨论: (1)当 则是一个斜率为-1的直线即 那么可以画出如下图。横坐标是
现在要保证范围,即 所以最后综合一下即 (2)当当 则是一个斜率为1的直线即 那么可以画出如下图。横坐标是
现在要保证范围,即 所以最后综合一下即 所以在我们通过一元二次方程求得的 注意这里有时候L=H这代表 -------------------------------------------------------------------------------------------------------------------------------------------------------------- 好的我们接着往下走,刚才说得到一个一元二次方程组那么系数a,b,c是多少呢?我们来求一下: 我们先将
我们将本次要优化的参数标为*即规范一下就是:
注意这里的 因为下面
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 最后小结理一下思路: 求解过程:首先我们要优化的问题是: 然后利用拉格朗日对偶问题将问题转化为: 接着我们使用了SMO算法求解出了一系列 将 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP的干活总结和实践心得,当然别的方向也会发,一起学习:
|










【本文地址】