| Web scraper 爬虫傻瓜教程(不断更新中) | 您所在的位置:网站首页 › 携程web › Web scraper 爬虫傻瓜教程(不断更新中) |
Web scraper 爬虫傻瓜教程(不断更新中)
教程
安装基本操作打开Web scraper使用Web scraper创建爬取运行爬虫,查看数据这里讲一个复杂一点的例子帮助大家学习参考:
安装
Web scraper只支持chrome浏览器,可以从chrome网上应用店下载这个插件,安装好后在扩展程序页面启用插件。Web scraper具备反爬虫机制,模拟人手动操作浏览器,适合轻度的数据爬取,而且免费!  基本操作
打开Web scraper
基本操作
打开Web scraper
当我们想要抓取某网页的时候,需要调出来Web scraper的开发界面,这点开发人员肯定很懂。 不懂的下面提供几种方法: windows 系统下可以使用快捷键 F12,有的型号的笔记本需要按 Fn+F12Mac 系统下可以使用快捷键 command+option+i在网页右键点击检查(ctrl+shift+i)直接在 Chrome 界面上操作,点击设置 → \rightarrow →更多工具 → \rightarrow →开发者工具 打开之后长这样,如果不在网页的下方就点这三个竖着的小圆点,给它换到网页下方。  换好之后长这样,就可以看的Web scraper插件了~ 换好之后长这样,就可以看的Web scraper插件了~  使用Web scraper
创建爬取
首先需要创建一个新的爬取:Create new sitemap
→
\rightarrow
→Create sitemap Import sitemap是导入脚本
使用Web scraper
创建爬取
首先需要创建一个新的爬取:Create new sitemap
→
\rightarrow
→Create sitemap Import sitemap是导入脚本  添加请求头,命名和将我们要爬取的网页url填好之后点Create Sitemap 这里要说明一下,一个Sitemap可以有多个Selector, 添加请求头,命名和将我们要爬取的网页url填好之后点Create Sitemap 这里要说明一下,一个Sitemap可以有多个Selector, 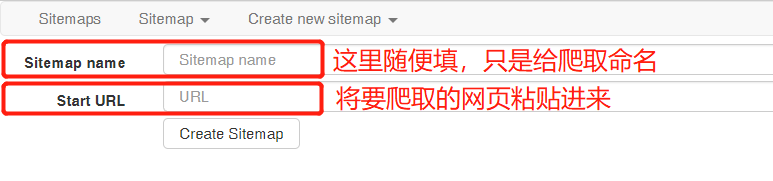 理解工具 理解工具  创建选择器时需使用 Element preview 和 Data preview 功能以确保你选中了正确的网页元素及数据。 1)Id - 爬取标题的命名,自己随意取 2)Type - 抓取数据的类型名字
Text(文本)选择器;Link(链接)选择器;Popup LINK(弹出链接)选择器;Image(图像)选择器;Table(表格)选择器;Element attribute(元素属性)选择器;HTML 选择器;Element;Element scroll down(滑动);Element click(点击);Grouped(组块)选择器。 创建选择器时需使用 Element preview 和 Data preview 功能以确保你选中了正确的网页元素及数据。 1)Id - 爬取标题的命名,自己随意取 2)Type - 抓取数据的类型名字
Text(文本)选择器;Link(链接)选择器;Popup LINK(弹出链接)选择器;Image(图像)选择器;Table(表格)选择器;Element attribute(元素属性)选择器;HTML 选择器;Element;Element scroll down(滑动);Element click(点击);Grouped(组块)选择器。  3)selector - CSS 选择器选取所需元素; 4)multiple - 如果要选择多个记录需勾选此项。从两个或多个选中 multiple 的选择器中提取的数据不会合并到一个单独记录中; 5)delay - 选择器生效前的延迟时长; 6)parent selectors - 为此选择器选择母选择器以产生选择器树形结构; 7)文本选择器(Text selector); 8)链接选择器(Link selector); 9)元素选择器(Element selector)。 3)selector - CSS 选择器选取所需元素; 4)multiple - 如果要选择多个记录需勾选此项。从两个或多个选中 multiple 的选择器中提取的数据不会合并到一个单独记录中; 5)delay - 选择器生效前的延迟时长; 6)parent selectors - 为此选择器选择母选择器以产生选择器树形结构; 7)文本选择器(Text selector); 8)链接选择器(Link selector); 9)元素选择器(Element selector)。  运行爬虫,查看数据
运行爬虫,查看数据
 如果抓取多页网站,Start url可以设定page=[2-5]表示第2页到第5页,如果是步长为2页,则可以:[2-5:2]。建立selector,Type选择Element scroll down用于爬取下拉滚动式的页面结构体。 如果抓取多页网站,Start url可以设定page=[2-5]表示第2页到第5页,如果是步长为2页,则可以:[2-5:2]。建立selector,Type选择Element scroll down用于爬取下拉滚动式的页面结构体。  建立新的selector,负责展开全文。Type选择Element click来模拟点击。 建立新的selector,负责展开全文。Type选择Element click来模拟点击。  建立新的selector,负责抓取正文内容。Type选择Text。 建立新的selector,负责抓取正文内容。Type选择Text。  建立新的selector,负责抓取时间日期。Type选择Text。 建立新的selector,负责抓取时间日期。Type选择Text。  同理,建立新的selector,负责抓取转赞评。Type选择Text。就不放图了。 同理,建立新的selector,负责抓取转赞评。Type选择Text。就不放图了。
注意:每次选择网页元素一定要点击Mutiple,从top到bottom选择两次自己要抓取的内容,比如要抓取微博推送内容,抓取该页面第一条和第二条,接下来板块都会自动抓取。 speed要调整一下,不然抓取的内容会不全。 参考: 如何使用web scraper收集大量微博信息 使用Selenium实现微博爬虫(预登录、展开全文、翻页)Webscraper爬取使用总结(持续更新)Web Scraper官网教程翻页选择器Element click selector --webscraper操作手册web scraper 里的 Element click 模拟点击「加载更多」Web Scraper 使用教程(五)- 进阶用法(Element scroll down)Web Scraper 高级用法——Web Scraper 抓取多条内容 | 简易数据分析 07web scraper 爬取微博粉丝性别以及微博内容web scraper中Selectors解析简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页简易数据分析Web Scraper傻瓜式爬虫插件之进阶套路有关webscraper的问题,看这个就够了爬取2000篇 Matrix 文章,这是一份可视化踹门教程介绍一款好用又易学的爬虫工具:web scraperWeb Scraper 教程web scraper 入门到精通之路不写代码,超级简单实用的爬虫工具:web scraper!Web Scraper教程 |
 1)Selector graph - 查看爬虫逻辑 2)Scrape - 运行爬虫 3)Browse - 查看数据 4)Export data as CSV - 保存数据
1)Selector graph - 查看爬虫逻辑 2)Scrape - 运行爬虫 3)Browse - 查看数据 4)Export data as CSV - 保存数据【本文地址】
公司简介
联系我们