| “傻瓜”学计量 | 您所在的位置:网站首页 › 插值法的计算逻辑思路 › “傻瓜”学计量 |
“傻瓜”学计量
|
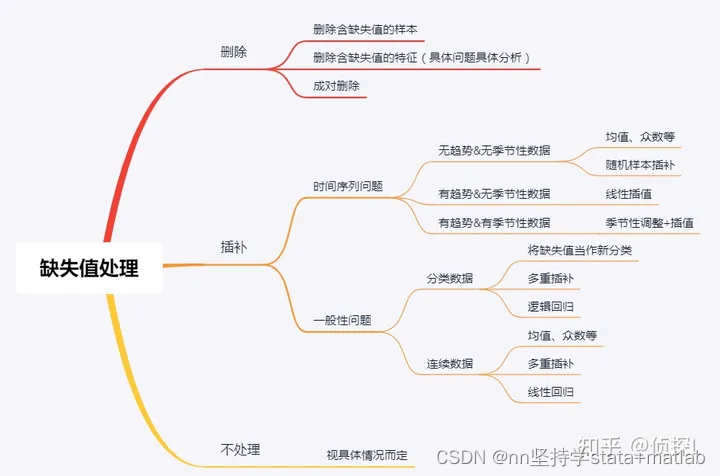
提纲: 1.适用数据类型 2.stata命令 原理:用已有数据拟合一条曲线,然后用预测值来代替 学习来源: Stata:缺失值的填充和补漏 线性插值法的stata操作(面板数据)_哔哩哔哩_bilibili 怎么处理数据缺失问题? - 知乎 数据分析——缺失值处理详解(理论篇) - 知乎 在excel中使用插值法补全数据_excel插值法补齐缺失数据-CSDN博客 数据缺失值的3种处理方式,终于有人讲明白了-CSDN博客 数据预处理常用技巧 | 缺失值插补的5种方法 - 知乎 数据缺失的插补方法简要 1.1 数据缺失的定义: 数据缺失 (Missing data) 是指那些实际未观测到,但是如果观测到会有意义的值。也就是说,缺失数据隐藏了有价值的信息。更直白点讲,计划收集用于研究,但未收集到的数据均可看作缺失数据。 1.2 数据缺失的原因: 信息未被采集到;信息被采集后丢失;信息被采集后认定有误并被删除。2 数据缺失模式和数据缺失机制 2.1 数据缺失模式missing data pattern 数据缺失模式 (missing data pattern) 是指在一个数据集中,数据观测值和数据缺失值的结构。其中最常见的模式有以下三种: 单一模式 (Univariate Pattern)缺失值均属于同一个变量单调模式 (Monotone Pattern)典型的面板数据中被调查对象退出调查且后续不再返回一般模式 (General Pattern)缺失值在数据集中随机散布在 Stata 中,可用如下命令识别缺失数据: misstable summarzie, gen (m_) tab m_* misstable pattern misstable pattern, freq2.2 数据缺失机制 Rubin (1976) 提出了被广为认可的数据缺失机制,用来描述缺失值存在的概率与数据的关系。他将缺失数据分为如下三种: 完全随机缺失数据 (Missing Completely at Random Data,MCAR) 数据缺失的概率与数据集中的任何数据均无关。随机缺失数据 (Missing at Random Data,MAR) 变量 Y 数据缺失的概率与模型中其他变量相关,但与变量 Y 本身无关。 随机丢失意味着数据丢失的概率与丢失的数据本身无关,而仅与部分已观测到的数据有关。也就是说,数据的缺失不是完全随机的,该类数据的缺失依赖于其他完全变量。 非随机缺失数据 (Missing Not at Random Data,MNAR) 变量 Y 数据缺失的概率即使在控制其他变量以后,仍与 Y 本身有关。 即,数据的缺失与不完全变量自身的取值有关。分为两种情况:缺失值取决于其假设值(例如,高收入人群通常不希望在调查中透露他们的收入);或者,缺失值取决于其他变量值(假设女性通常不想透露她们的年龄,则这里年龄变量缺失值受性别变量的影响)。 3 处理数确实的方式
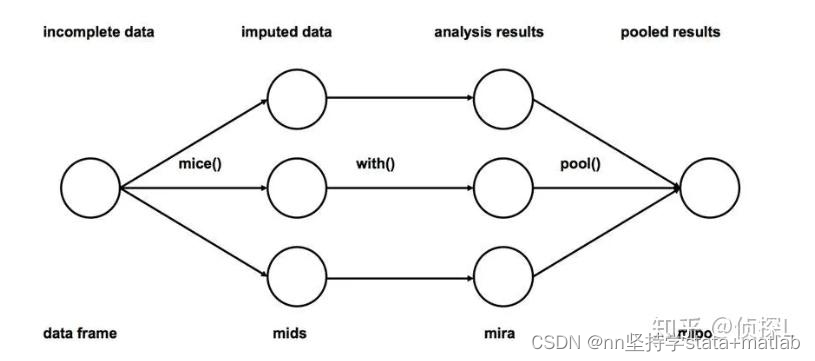
3.1 直接删除法 Deletion Method 要求:缺失数据是「完全随机缺失数据 (MCAR)」,否则会产生明显的偏误。 但是,即使缺失数据满足 MCAR 条件,直接删除法会造成数据的浪费,大大削弱分析的效能 (reduce power)。 成列删除 (Listwise Deletion, Complete-Case Analysis) 删除所有存在缺失值的个体成对删除 (Pairwise Deletion, Available-Case Analysis) 只删除需要用到的变量存在缺失值的个体。3.2 单一插补法 Single Imputation Method 区别于多重插补 (Multiple Imputation),单一插补 (Single Imputation)为每个缺失的数据点生成一个单一的替换值。 方法大类原理主要细分方法/步骤优势/劣势单一插补法 (Single Imputation Method) 为每个缺失的数据点生成一个单一的替换值1.算数平均差补法 (Arithmetic Mean Imputation) 2.回归插值法(Regression Imputation) 3.随即回归插值法(Stochastic Regression Imputation) 优势在于创建了完整的数据集,使那些在直接删除法中会被删除的数据得以利用。劣势:但是大部分单一插补法,即使在缺失数据是 MCAR 的情况下,均会产生有偏估计 (随即回归插补是例外,其是唯一可以对 MAR 数据产生无偏估计的方法)。此外,单一回归插补法会使「标准误被低估,导致置信区间过窄」。 多重插补 (Multiple Imputation) 创建数据集的多个副本,并对每个副本使用不同的估计方法来估算缺失值。 多重插补的理论源于是单一插补法中的随机回归插补,但是其数学基础来自贝叶斯估计。多重插补 (MI) 一般涉及以下三个步骤: 重插补 (MI) 一般涉及以下三个步骤: 1.插补阶段 (Imputation Phase):创建数据集的 m 个副本,每个副本中包含对缺失值的不同估计; 2.分析阶段 (Analysis Phase):将分析模型拟合到 m 个数据集中; 3.汇集阶段 (Pooling Phase):使用 Rubin 法则将 m 组结果汇集成一个结果 优势:为单一插补法下的标准误低估问题提供了一个解决方案。其可以通过引入观测数据的可变性、估计插补模型的不确定性和生成插补值的不确定性增加数据的标准误。3.2 多重差补法
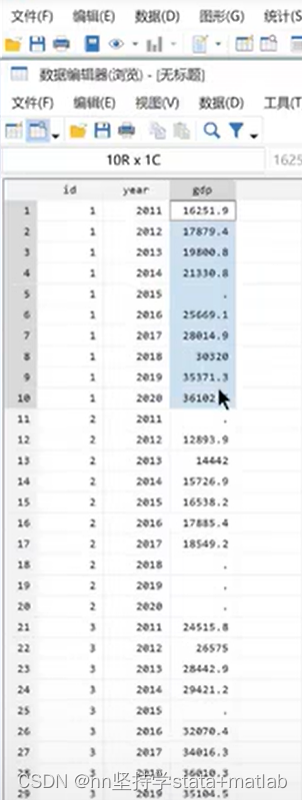
Stata 中多重插补的操作可使用如下命令: *准备工作 mi set flong/mlong/wide //为 MI 声明数据结构 mi register imputed //声明要插补的变量 *插补阶段 mi impute regress/logit //单一插补法 mi impute monotone/mvn/chained //多重插补法 *分析与汇集阶段 mi estimate //分析并整合结果一、适用数据:面板数据 二、stata命令 xtset id year 设定面板格式 by id: ipolate gdp year, gen(gdp1) 依据id分组,插值法均在组内运行 ipolate 插值法代码 gdp 对gdp进行插值 year 根据年份对gdp进行插值。 gen(gdp1) 构建新的变量叫gdp1
该命令缺点:首尾位置的数据 或 与空白首尾数据相连的数据不能插值 解决方法: by id: ipolate gdp year, gen(gdp2) epolate |
【本文地址】