| 模型融合model fusion与模型聚合model ensemble:提升机器学习性能的艺术 | 您所在的位置:网站首页 › 提高模型 › 模型融合model fusion与模型聚合model ensemble:提升机器学习性能的艺术 |
模型融合model fusion与模型聚合model ensemble:提升机器学习性能的艺术
|
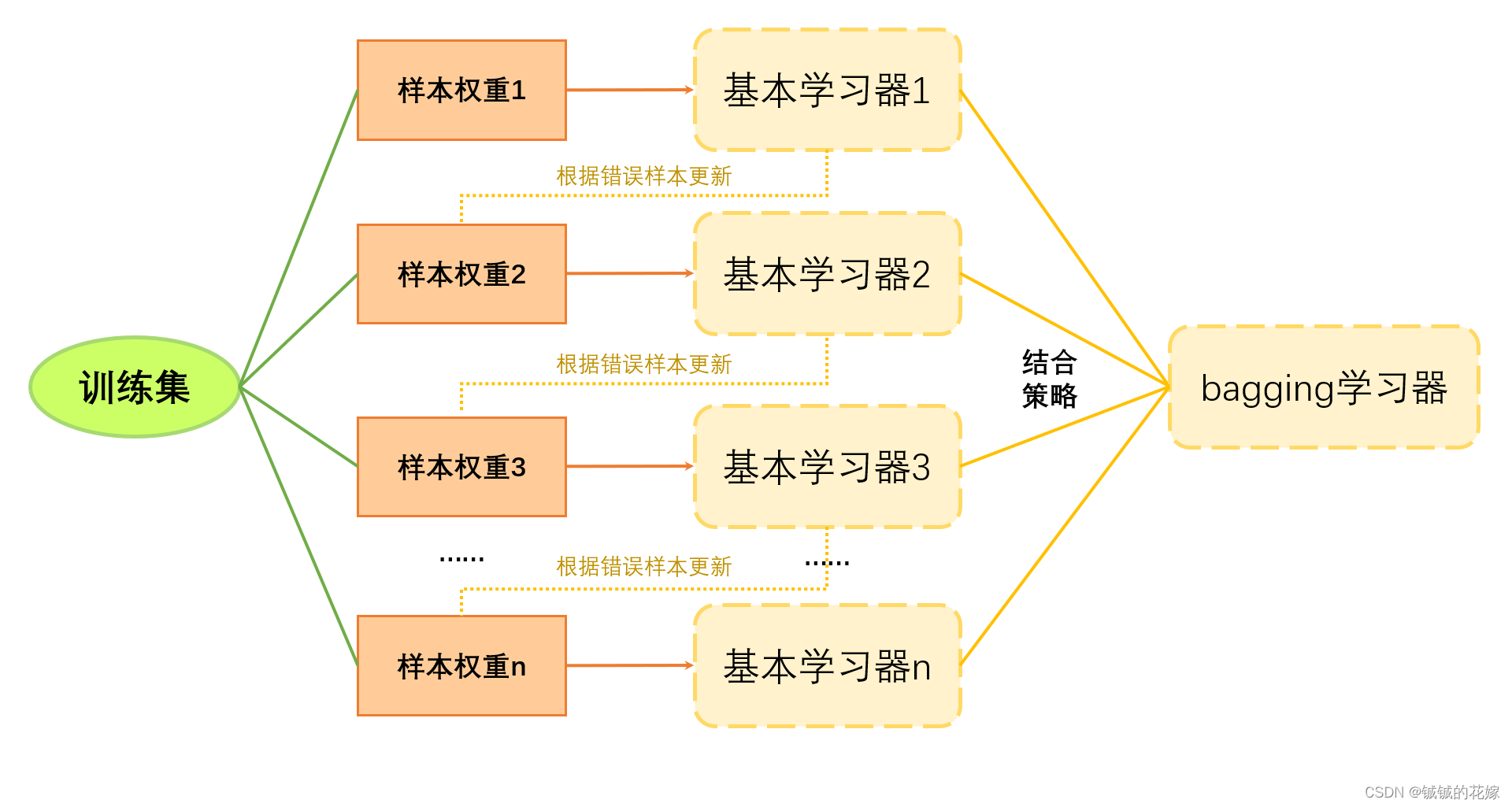
诸神缄默不语-个人CSDN博文目录 文章目录 引言基模型模型融合与模型聚合的基本概念常见的模型聚合方法简单平均法加权平均模型输出加权平均模型参数投票法bagging堆叠法(Stacking)提升法(Boosting)GBDT 新的模型聚合工作模型融合与聚合的应用结论参考资料 引言在机器学习领域,单一模型往往难以达到最佳性能。模型融合(Model Fusion)和模型聚合(Model Ensemble)是提高预测准确性和鲁棒性的有效策略。它们通过组合多个模型的预测结果来改善单一模型可能存在的不足。本文将介绍模型融合和模型聚合的基本概念、常见方法及其应用。 基模型同样的参数,不同的初始化方式。 不同的参数,通过cross-validation,选取最好的几组 同样的参数,模型训练的不同阶段,即不同迭代次数的模型 不同的模型,进行线性融合,例如RNN和传统模型 模型融合与模型聚合的基本概念模型融合是指在模型层面上,将不同的模型组合在一起,通过特定的算法来整合多个模型的输出。模型融合的目标是综合不同模型的优点,以达到比单个模型更好的预测效果。 模型聚合则更侧重于通过策略性地组合多个模型的预测结果来提高整体的预测准确率。它通常涉及构建多个独立的模型,并利用某种形式的平均或投票机制来综合这些模型的预测。 常见的模型聚合方法 简单平均法简单平均法是最直接的模型聚合方法,它对所有模型的预测结果求平均,以获取最终的预测值。 def simple_average(predictions): return sum(predictions) / len(predictions) 加权平均模型输出与简单平均法类似,加权平均法为不同模型的预测结果分配不同的权重。这种方法在某些模型预测结果更可靠时非常有效。 def weighted_average(predictions, weights): weighted_sum = sum(p * w for p, w in zip(predictions, weights)) return weighted_sum / sum(weights)参考文献: (1994 Information and Computation) The Weighted Majority Algorithm:加权平均输出 加权平均模型参数 (1985 SIGGRAPH) Animating Rotation with Quaternion Curves:球面线性插值(2022 ICML) Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time:线性加权平均(2022 NeurIPS) Patching open-vocabulary models by interpolating weights:任务算术(2022 NeurIPS) Merging Models with Fisher-Weighted Averaging:利用补充数据,根据模型梯度或表示计算融合权重,消除了超参数调优的需求(2023 ICLR) Dataless Knowledge Fusion by Merging Weights of Language Models:利用补充数据,根据模型梯度或表示计算融合权重,消除了超参数调优的需求(2023 NeurIPS) TIES-Merging: Resolving Interference When Merging Models:在模型融合前修剪低振幅变化的参数值,以避免冗余参数干扰 投票法对于分类问题,投票法是一种常用的模型聚合策略。它根据多个模型的预测类别进行投票,选出得票最多的类别作为最终预测。 投票可以选择不同模型都运行输出,也可以选择一个模型运行多次。 from collections import Counter def majority_vote(predictions): votes = Counter(predictions) majority = votes.most_common(1)[0][0] return majority参考文献: (2011 IJCNN) Turning Bayesian Model Averaging Into Bayesian Model Combination bagging它将数据分成N折,每个基模型学习其中N-1折数据。 对于相同部分,直接采取;对于不同部分,采用投票的方式做出集体决策。 堆叠法(Stacking)堆叠是一种更复杂的模型聚合方法,将多个不同模型的预测结果作为输入,训练一个新的模型来产生最终的预测。这种方法能够有效地利用不同模型的预测能力。 Stacking(堆叠泛化)是一种集成学习技术,通过结合多个不同的基模型,使用一个元模型(或称为次级学习器)来整合各基模型的预测结果,以获得更好的预测性能。以下是使用Python和scikit-learn库实现的一个简单的Stacking示例。这个例子中,我们将使用三个基模型(决策树、K近邻、支持向量机)和一个元模型(逻辑回归),来解决一个分类问题。 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.base import BaseEstimator, TransformerMixin, ClassifierMixin from sklearn.base import clone from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.linear_model import LogisticRegression import numpy as np # 加载数据集 iris = load_iris() X, y = iris.data, iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 定义Stacking类 class StackingClassifier(BaseEstimator, ClassifierMixin, TransformerMixin): def __init__(self, base_classifiers, meta_classifier): self.base_classifiers = base_classifiers self.meta_classifier = meta_classifier def fit(self, X, y): # 克隆基模型,避免修改原始模型 self.clones_ = [clone(clf) for clf in self.base_classifiers] # 训练基模型 for clf in self.clones_: clf.fit(X, y) # 创建用于训练元模型的数据集 meta_features = np.column_stack([clf.predict(X) for clf in self.clones_]) # 训练元模型 self.meta_classifier_ = clone(self.meta_classifier).fit(meta_features, y) return self def predict(self, X): # 基模型的预测结果 meta_features = np.column_stack([clf.predict(X) for clf in self.clones_]) # 元模型的最终预测 return self.meta_classifier_.predict(meta_features) # 实例化基模型和元模型 base_classifiers = [DecisionTreeClassifier(), KNeighborsClassifier(), SVC(probability=True)] meta_classifier = LogisticRegression() # 创建Stacking分类器 stacking_clf = StackingClassifier(base_classifiers=base_classifiers, meta_classifier=meta_classifier) # 训练Stacking分类器 stacking_clf.fit(X_train, y_train) # 在测试集上进行预测 y_pred = stacking_clf.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print(f"Stacking Classifier Accuracy: {accuracy:.2f}")在这个例子中,我们首先定义了一个StackingClassifier类,它接受基模型列表和一个元模型作为输入。在训练阶段,每个基模型独立地在完整的训练数据集上进行训练。接着,我们使用这些基模型的预测结果来训练元模型,元模型的任务是综合这些预测结果,输出最终的预测。最后,我们使用训练好的Stacking分类器在测试集上进行预测,并计算准确率。 请注意,这个示例仅用于演示Stacking的基本概念和实现方法。在实际应用中,您可能需要根据具体问题调整模型的选择、超参数等。 提升法(Boosting)
提升法是一种迭代技术,它通过连续地修改数据的权重,训练一系列的模型。每个模型都试图纠正前一个模型的错误,最终的预测结果是这些模型的加权和。 每个学习器按照串行的方法生成。把几个基本学习器层层叠加,但是每一层的学习器的重要程度不同,越前面的学习的重要程度越高。它聚焦样本的权重。每一层在学习的时候,对前面几层分错的样本“特别关注”,建立了每个机器学习器之间的依赖关系,因此提升了整体模型的准确率。 Boosting 是一种集成学习技术,通过顺序地训练模型,使得后续的模型能够修正前一个模型的错误,最终的预测结果是通过组合所有模型的预测来完成的。Boosting 方法的一个著名实例是 AdaBoost(自适应增强)。以下是使用 Python 和 scikit-learn 库实现的一个 AdaBoost 示例,其中使用决策树作为基学习器来解决一个分类问题。 值得一提的是很多树类的boost还可以作为特征筛选器,有特征重要程度评分的功能。 from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 加载数据集 data = load_breast_cancer() X, y = data.data, data.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化基学习器 base_estimator = DecisionTreeClassifier(max_depth=1) # 初始化AdaBoost分类器 ada_boost_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42) # 训练模型 ada_boost_clf.fit(X_train, y_train) # 在测试集上进行预测 y_pred = ada_boost_clf.predict(X_test) # 计算准确率 accuracy = accuracy_score(y_test, y_pred) print(f"AdaBoost Classifier Accuracy: {accuracy:.2f}")在这个示例中,我们首先加载了乳腺癌数据集并划分成训练集和测试集。然后,我们使用 DecisionTreeClassifier 作为基学习器初始化了 AdaBoost 分类器。AdaBoost 分类器的 n_estimators 参数设置为 50,意味着将顺序地训练 50 个决策树;learning_rate 参数控制着每个基学习器的贡献程度。之后,我们训练 AdaBoost 分类器并在测试集上进行预测,最后计算并输出模型的准确率。 AdaBoost 是 boosting 方法中的一个基本算法,除此之外,还有其他的 boosting 方法,如 Gradient Boosting 和 XGBoost 等,它们在处理各种机器学习问题时非常有效。这些方法提供了不同的策略来调整后续模型重点关注的数据点,从而改进模型的性能。 GBDT 随机森林XGBoostLightGBMCatBoost 新的模型聚合工作 (2023 ACL) LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion:聚合LLM,先比较LLM之间的细微差别,然后组合排名靠前的candidates,生成增强后的输出(2024 ICLR) FuseLLM:Knowledge Fusion of Large Language Models:提出了一种多语言模型知识融合的新范式,它利用源语言模型生成的概率分布矩阵,将集体知识和各自优势转移到目标模型。与模型聚合方法(需要并行部署多个模型)相比, FuseLLM支持将不同架构的多个源语言模型融合到目标模型中。(2024) FuseChat: Knowledge Fusion of Chat Models 模型融合与聚合的应用模型融合和聚合广泛应用于各种机器学习任务中,包括但不限于图像识别、自然语言处理、推荐系统等领域。通过结合不同模型的独特优势,可以显著提升任务的性能。 结论模型融合和模型聚合是提升机器学习模型性能的重要手段。虽然这些方法增加了模型的复杂性,但它们在提高预测准确性、减少过拟合方面发挥着不可替代的作用。未来,随着机器学习领域的不断发展,我们期待出现更多高效的融合与聚合技术。 参考资料 我还没看 (2009 周志华) Ensemble Learning(2018 WIREs Data Mining Knowl Discov) Ensemble learning: A survey 【模型融合】集成学习(boosting, bagging, stacking)原理介绍、python代码实现(sklearn)、分类回归任务实战_stacking集成模型-CSDN博客:看了一点。感觉整体写得很全面、有概括性,以后慢慢细看,看了整理信息到我的博文里。 |
【本文地址】