| yolov5训练详解 | 您所在的位置:网站首页 › 指定软件走哪个网卡 › yolov5训练详解 |
yolov5训练详解
|
最近跑了一下yolov5,在此给大家介绍一下如何用yolov5训练自己的数据集, github官方代码https://github.com/ultralytics/yolov5 官方权重我已经下载下来了,见https://download.csdn.net/download/qq_41334243/12572600 【注】本文所说的训练只针对官方代码。 1)数据集制作 数据集选择:(1)自己做的数据集(2)开源数据集 (1)自己做的数据集 本人使用精灵标注助手做了一个猫狗识别,把每张图片上的猫和狗都框出来,导出格式为xml,没用过的可以试一下,很简单。 完整代码见链接:https://pan.baidu.com/s/1Fc2u6YDK3ddyuBFmxChpvQ 提取码:alse 免费下载,根据每张图片的框生成相应的txt,然后根据上述的文件目录格式把文件放进去就好。 (2)开源数据集 简单聚两个例子: celeba:首先要理解开源数据集的结构,数据存储的是什么值,list_bbox_celeba.txt存储的是image_id(图片名)、 x_1(框的左上角x)、 y_1(框的左上角y)、 width(框的宽)、 height(框的高),把这些数据取出来转换成yolov5要求的格式即可 # # 由于celeba样本不好,做矫正 #x,y左上角坐标,w,h框的宽和高 x1, y1, x2, y2 = int(x + w * 0.12), int(y + h * 0.1), int(x + w * 0.9), int(y + h * 0.85) x, y, w, h = x1, y1, x2 - x1, y2 - y1 # cx, cy = int(x + w / 2), int(y + h / 2) # **************************** dw = 1. / (int(img_w)) dh = 1. / (int(img_h)) x = (x1 + x2) / 2.0 - 1 y = (y1 + y2) / 2.0 - 1 w = x2 - x1 h = y2 - y1 x = x * dw w = w * dw y = y * dh h = h * dh # **************************** f.write(f"0 {x} {y} {w} {h}\n") f.flush() f.close()完整代码见链接:https://pan.baidu.com/s/1Fc2u6YDK3ddyuBFmxChpvQ 提取码:alse wideface数据集同理,转换以下就好 完整代码见链接:https://pan.baidu.com/s/1Fc2u6YDK3ddyuBFmxChpvQ 提取码:alse 再次提醒:图片和标签的位置要对应,如下目录结构 (2) 第二个需要更改的配置文件(model文件夹下的yaml文件):
(3)更改train.py文件部分配置 #设置训练批次 parser.add_argument('--epochs', type=int, default=300) #设置batch-size,根据自己电脑性能来填 parser.add_argument('--batch-size', type=int, default=4) #选择需要加载的模型,此处我是用的是yolov5s模型 parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path') #选择自己数据配置文件 parser.add_argument('--data', type=str, default='data/dog_cat.yaml', help='*.data path') #这个官方默认是没有填写的,如果你不想从头训练,此处default=''改成模型对应的预训练的权重 parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')一切搞定,开启训练之旅吧。 再补充一点: yolov5训练的保存权重默认有两个,last.pt和best.pt,本人测试的last权重在大部分训练情况下较best要好点,具体情况自己测试以下就好。 以下是train.py文件的权重设置,想更改位置或权重名称的自己看着修改 wdir = 'weights' + os.sep # weights dir os.makedirs(wdir, exist_ok=True) last = wdir + 'last.pt' best = wdir + 'best.pt' results_file = 'results.txt'关于yolov5训练后权重较大的原因: yolov5官方的预训练权重是基于FP16的,训练的时候使用的是FP32,此处储存空间就增加了一倍;同时官方预训练权重是不包含optimizer参数的,而我们训练的时候是把optimizer参数保存了的,这个可以打印出来看一下,所以最终我们训练的权重比预训练权重大很多。 我在另一篇文章中就以上问题进行了详细的说明 关于yolov5训练后权重较大的原因及其解决方案 如果还有其他问题,可能是环境不兼容,关于yolov5部署踩坑问题,下篇给介绍。 小编初来乍到,如有写错的地方,还请指教,谢谢 【参考文章】 https://github.com/DataXujing/YOLO-v5 |
 左边为导出的文件,每个 图片对应一个xml,其中为左上角,为右下角,而yolov5要求的训练集是每张图片对应一个txt,且目录格式如下图:
左边为导出的文件,每个 图片对应一个xml,其中为左上角,为右下角,而yolov5要求的训练集是每张图片对应一个txt,且目录格式如下图: 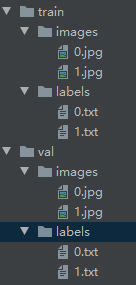 yolov5训练的txt数据内容为:classes(类别)、center_x(中心点x)、 center_y(中心点y)、 w(框的宽)、 h(框的高),如下图
yolov5训练的txt数据内容为:classes(类别)、center_x(中心点x)、 center_y(中心点y)、 w(框的宽)、 h(框的高),如下图  可是除了类别,其他的值为什么都是小数呢,此处有一个坑,根据yolov5要求,数据需要预处理,否则根据官方代码的反算数据就会有问题,如下预处理代码:
可是除了类别,其他的值为什么都是小数呢,此处有一个坑,根据yolov5要求,数据需要预处理,否则根据官方代码的反算数据就会有问题,如下预处理代码: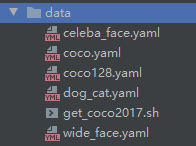 创建一个自己数据集的yaml文件,如我之前做的celeba人脸识别,代码如下:
创建一个自己数据集的yaml文件,如我之前做的celeba人脸识别,代码如下: 这个看你训练想用哪个模型,yolov5分为四个不同级别的模型,5s、5m、5l、5x
这个看你训练想用哪个模型,yolov5分为四个不同级别的模型,5s、5m、5l、5x  从图中就能看出5s性能稍微低点,5s是最小的一个模型,我这里使用的是5s模型,你可以自己选择,这里主要是更改分类数,默认都是80个分类,来源于coco数据集80个分类,所以你需要改成自己需要的分类数;
从图中就能看出5s性能稍微低点,5s是最小的一个模型,我这里使用的是5s模型,你可以自己选择,这里主要是更改分类数,默认都是80个分类,来源于coco数据集80个分类,所以你需要改成自己需要的分类数;【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |