| 线性回归名词解释 | 您所在的位置:网站首页 › 拟合度名词解释 › 线性回归名词解释 |
线性回归名词解释
|
回归表各项含义
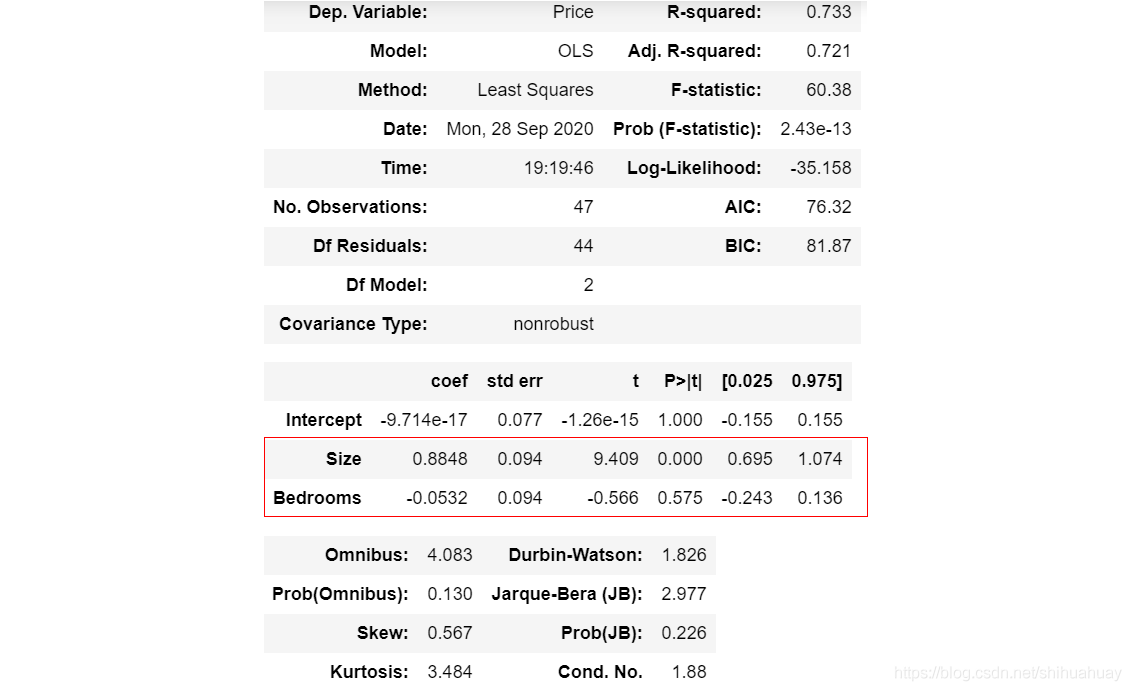
1.数据2.回归结果3.名词解释3.1 自变量对因变量的影响:回归系数、std err、t、P、[0.025,0.975]3.2 回归拟合程度-决定系数R方3.3 模型的有效性:F检验
1.数据
import pandas as pd
path = 'ex1data2.txt'
data2 = pd.read_csv(path, header=None, names=['Size', 'Bedrooms', 'Price'])
data2.head()
#标准化
data = (data2 - data2.mean()) / data2.std()
data.head()
中心极限定理(central limit theorem):In probability theory, the central limit theorem (CLT) establishes that, in some situations, when independent random variables are added, their properly normalized sum tends toward a normal distribution (informally a bell curve) even if the original variables themselves are not normally distributed. 3.1 自变量对因变量的影响:回归系数、std err、t、P、[0.025,0.975]coef: 回归系数 std err:回归系数的标准差 t: t值 P:P值 [0.025,0.975]: 回归系数的95%的置信区间 接下来按照假设检验的步骤对这几个名词进行解释: 建立假设:零假设: β = 0 \beta=0 β=0;备择假设: β ≠ 0 \beta\not=0 β=0回归分析零假设的标准差,回归栏报告的标准差就是这个标准差(此处不对回归系数标准差公式进行推导),如图中size变量回归系数的标准差为0.094。 补充:多元回归系数的方差 V a r ( β 1 ) = σ 2 S S T x ( 1 − R 2 ) Var(\beta_1)=\frac{\sigma^2}{SST_x(1-R^2)} Var(β1)=SSTx(1−R2)σ2其中, σ 2 \sigma^2 σ2为残差的方差, S S T x = ∑ i = 1 n ( x i − x ˉ ) 2 SST_x=\sum_{i=1}^n {(x_i-\bar{x})^2} SSTx=∑i=1n(xi−xˉ)2对于所有变量而言,残差方差相同, R 2 R^2 R2相同,差异在每个变量的 S S T x SST_x SSTx而对于标准化处理之后的变量,均值为0,方差为1。 S S T x SST_x SSTx等于样本量(标准化后自变量的标准差乘以样本量)。因此,经过标准化处理的自变量的回归系数的标准差一样,这也是为什么下图的两个变量(size,bedrooms)回归系数的标准差一样的原因。 计算统计量: t o r z = β − 0 s t d t\ or\ z=\frac{\beta-0}{std} t or z=stdβ−0 t s = x − m e a n ( x ) s t d ( x ) = 0.8848 − 0 0.094 = 9.412 t_s= \frac{x-mean(x)}{std(x)} = \frac{0.8848-0}{0.094}=9.412 ts=std(x)x−mean(x)=0.0940.8848−0=9.412 t b = x − m e a n ( x ) s t d ( x ) = − 0.0532 − 0 0.094 = − 0.566 t_b=\frac{x-mean(x)}{std(x)} = \frac{-0.0532-0}{0.094}=-0.566 tb=std(x)x−mean(x)=0.094−0.0532−0=−0.566查询统计量对应P值若P值小于0.05,拒绝原假设,接受备择假设。说明回归系数不等于0,自变量显著影响因变量 而回归系数的95%的置信区间的计算其实就是[coef-1.96std,coef+1.96std],如果区间包含0,则说明回归系数的1.96个标准差范围内有0出现,不足以拒绝原假设。判断系数显著的方法 1)P 值(常用)-用它! 2)t值或z值(z值为1.96,系数在0.05的显著性水平下显著) 3)置信区间是否包含0,包含0则说明在回归表报告的显著性水平(图中为0.05)下不显著。 3.2 回归拟合程度-决定系数R方 在说明F检验之前,先说明回归平方和、残差平方和等几个概念。先摆出一个公式(可自行推导): F检验,检验模型的显著性,至少有一个变量是重要的。F检验的思想是零假设所有的变量都不起作用,备择假设是至少有一个变量起作用。 |

 此公式背后的逻辑是:回归时总的回归平方和(其实就是数据的方差分子的部分),一部分是由回归涉及的变量解释,另一部分归残差所有。回归平方和越大,说明模型自变量对因变量的解释力越强。这也是R方想要说的事。虽然对于同一个因变量,回归平方和就可以描述自变量对因变量的解释力。但可能考虑到不同的因变量的总偏差平方和不同,R方就成了下面的形式。
此公式背后的逻辑是:回归时总的回归平方和(其实就是数据的方差分子的部分),一部分是由回归涉及的变量解释,另一部分归残差所有。回归平方和越大,说明模型自变量对因变量的解释力越强。这也是R方想要说的事。虽然对于同一个因变量,回归平方和就可以描述自变量对因变量的解释力。但可能考虑到不同的因变量的总偏差平方和不同,R方就成了下面的形式。 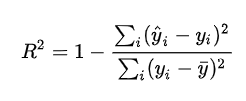 但是,R方统计并不完美。它有一个主要缺陷。不管我们在回归模型中添加多少变量,它的值永远不会减少。因此,调整R方就出世了。
但是,R方统计并不完美。它有一个主要缺陷。不管我们在回归模型中添加多少变量,它的值永远不会减少。因此,调整R方就出世了。 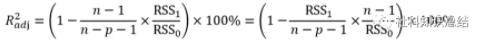

【本文地址】