| 监督学习(回归和分类)常见算法总结 | 您所在的位置:网站首页 › 招标平均价格算法有哪些 › 监督学习(回归和分类)常见算法总结 |
监督学习(回归和分类)常见算法总结
|
根据训练期间接受的监督数量和监督类型,可以将机器学习分为以下四种类型:监督学习、非监督学习、半监督学习和强化学习。
本期将对监督学习常见算法进行简述。
一,概述
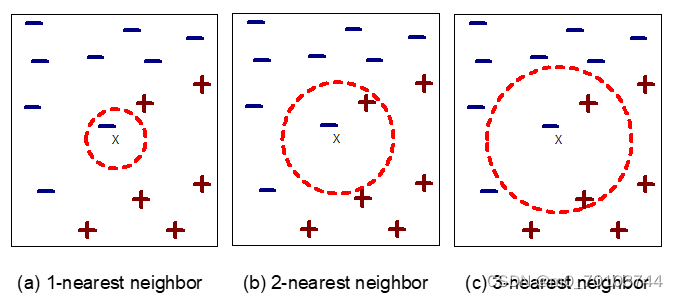
监督学习的目的是让模型能够从已知的输入和输出之间的关系中学习,并且能够对新的输入做出正确的预测。在监督学习的范畴中,又可以划分为回归和分类算法。 一,分类算法 1.KNN(k近邻算法) (1)核心思想:给定一个训练数据集,对于新的待分类的输入实例,计算训练数据集中与该输入实例最相近的k个实例,则这k个实例的多数属于某个类,就把该输入实例分为这个类中。 (2)工作原理:1) 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。 2) 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。 3) 计算新数据与样本数据集中每条数据的距离。 4) 对求得的所有距离进行排序(从小到大,越小表示越相似)。 5) 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。 6) 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
1)计算测试数据与各个训练数据之间的距离; 2)按照距离的递增关系进行排序; 3)选取距离最小的K个点; 4)确定前K个点所在类别的出现频率; 5)返回前K个点中出现频率最高的类别作为测试数据的预测分类 (4)KNN三要素:k值的选择、距离度量及分类决策规则是k近邻法的三个基本要素 1)k值的选择 : 如果 k 太小, 则对噪声点敏感;如果 k 太大, 邻域可能包含很多其他类的点;经验就是k=3,上限k=sqrt(n) 2)距离度量: 特征空间中的两个实例点的距离是两个实例点相似程度的反映。 使用的距离最常用的是欧氏距离,但也可以是其他距离。 3)分类决策规则 k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类,决定输入实例的类。 (5)实战算法流程代码总结(鸢尾花):一.准备操作 1.导入数据:data=pd.read_csv('iris.csv') 2.查看数据信息:data.info() 3.删除不需要的项:data=data.drop('Unnamed: 0',axis=1) 二.离散值处理 1.画出箱型图查看是否有离群值存在:sns.boxplot(data=data,orient='h',palette='Set1') 2.利用天花板—地板法 或者四分法对离群值进行消除 def std_data(data) 在+-3 std 范围内的为正常值 if item =-3*std: sep_w.append(item) 超过这个范围,将其赋值为天花板值或者地板值 item |
【本文地址】