| 关于抖音抓包的一些分析和抖音视频批量下载 | 您所在的位置:网站首页 › 抖音视频批量 › 关于抖音抓包的一些分析和抖音视频批量下载 |
关于抖音抓包的一些分析和抖音视频批量下载
|
上一篇介绍了抓包软件的使用: Fiddler+夜神模拟器+xposed+justTrustMe手机抓包 这一篇介绍下对抖音里**“喜欢”**的视频批量下载,和一些分析。
https://aweme.snssdk.com/aweme/v1/aweme/favorite/ 1.2 过滤下url: 1.3 headers参数: X-Gorgon:请求所需的加密参数 X-Tt-Token:在搜索接口用于用户身份的标示。 有的接口会有X-SS-STUB用于post请求时body部分的md5值,但是在为空的情况下,有时候不参与加密,有时候参与加密,具体接口需要具体分析。 经过测试,搜索接口的 xgorgon 一个大概可以用2分钟。1秒请求1次,请求130条数据需要重新获取xgorgon。 当然也可以每次请求都重新生成xgorgon。 每个账号每天请求搜索接口有次数限制,大概在300左右。 超过限制需要更换账号,另外params也要改变。 1.4 params参数: 总的有37个参数包括设备信息等。 比如:sec_user_id:加密后的你的抖音id longitude:经度 latitude:纬度 device_type:设备型号 manifest_version_code:抖音代码版本 其他的有两个参数需要注意,max_cursor 和 count 这两个参数 max_cursor : 根据这个参数来返回用户的视频列表 , 第一次访问时 , 本参数为0 , 会返回最新的20个视频 (count为20时) count : 返回视频的数量 第一次请求是20 , 后面每次是10。我修改了count后得到的请求是这样的 其中 play_addr是无水印的视频链接,该链接接做了时间限制,把链接复制出来在浏览器内打开短时间内可以观看和下载,但是超出时间限制则无法访问,那怎么搞?看下面的uri。share_url有水印的视频地址url(长期有效)uri视频的唯一id,把uri复制替换下面的uri,浏览器打开,你会发现一片空白,但是发送到手机或者电脑浏览器用手机模式打开就可以看到原视频了 https://aweme.snssdk.com/aweme/v1/play/?video_id=uri&ratio=720p&line=0或者: https://aweme.snssdk.com/aweme/v1/play/?video_id=uri比如: https://aweme.snssdk.com/aweme/v1/play/?video_id=v0d00ffa0000bvq6d47clnok9ciqf3jg&ratio=720p&line=0 手机模式打开就可以看到无水印视频了,然后复制地址栏的地址就是视频的真实地址了,这个地址手机电脑都能打开播放下载。 抖音apk使用jadx逆向后发现包名、变量、函数名很多都经过了混淆:
Fiddler和模拟器的使用请参考我另一篇文章 Fiddler+夜神模拟器+xposed+justTrustMe手机抓包 二、批量下载抖音里的点了红心的视频思路:1.参照上面的文章,配置好fiddler和模拟器,打开fiddler开始抓包,模拟器打开抖音登录自己的账号,点击喜欢的视频列表开始滑动。(因为没有使用脚本或其他工具去模拟滑动屏幕操作,所以这里需要手动滑动,我喜欢的视频只有600多个,慢慢的滑的估计只要两分钟可以滑完)。 2.滑完之后fiddler关闭抓包,然后过滤下url,获取所有喜欢列表的请求。 3.选择save保存所有的请求为会话,给本次会话起个名字,然后在左侧会看到本次保存的会话。 4.选择保存的会话右键Export导出,导出格式选择Raw File。Raw File格式可以将所有响应保存为json文件。 代码主要用到的jar包: fastjson-1.2.70.jar httpclient-4.5.12.jar httpcore-4.4.13.jar commons-lang3-3.3.9.jar jar包已上传百度云,提取码:di81 三、主要的代码:响应文件解析获取url类: path 改成上面导出的文件夹里的favorite文件夹地址 package utils; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONObject; import java.io.*; import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; public class Douyin { /** * 存放所有的响应文件名 */ private List files = new ArrayList(); /** * 存放所有视频名称和url, */ private Map videoMap = new ConcurrentHashMap(); /** * 要解析的响应文件存放路径 */ private String path = "D:\\fiddlerSaveFile\\2021-1-14\\aweme.snssdk.com\\aweme\\v1\\aweme\\favorite\\"; private int number=1; public String getPath() { return path; } public void setPath(String path) { this.path = path; } /** * 获取响应文件中的视频url地址(aweme_list中的play_addr到videoMap) * * @param filePath * @return */ public void getVideoUrl(String filePath) { StringBuilder jaonstr = new StringBuilder(); try ( //读取文件为字节流 FileInputStream file = new FileInputStream(filePath); //字节流转化为字符流,以UTF-8读取防止中文乱码 InputStreamReader in = new InputStreamReader(file, "UTF-8"); //加入到缓存 BufferedReader buf = new BufferedReader(in); ) { String str = ""; while ((str = buf.readLine()) != null) { //按行读取,到达最后一行返回null jaonstr.append(str); } } catch (IOException e) { e.printStackTrace(); } JSONObject json = JSONObject.parseObject(jaonstr.toString());//字符串转json对象 JSONArray jsonArray = json.getJSONArray("aweme_list"); for (int i = 0; i //获取path路径下的所有文件绝对路径到files File file = new File(path); File[] tempList = file.listFiles(); for (int i = 0; i files.add(tempList[i].toString()); } } //遍历files解析每个文件获取url到videoMap files.forEach(v -> getVideoUrl(v)); return this.videoMap; } }视频下载类: package utils; import com.alibaba.fastjson.JSON; import org.apache.commons.lang3.StringUtils; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.HttpStatus; import org.apache.http.client.HttpClient; import org.apache.http.client.config.RequestConfig; import org.apache.http.clienthods.CloseableHttpResponse; import org.apache.http.clienthods.HttpGet; import org.apache.http.clienthods.HttpPost; import org.apache.http.entity.ContentType; import org.apache.http.entity.StringEntity; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import java.io.*; import java.util.Map; public class HttpUtil { private static RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(60000).setConnectTimeout(60000).build(); private static String chaset = "UTF-8"; // 默认编码 private static String videoDownLoadPath = "D:\\video\\"; // 默认视频下载的位置 /** * 发送 GET 请求(HTTP),无参数 * * @param url * @return */ public static String doGet(String url) { if (StringUtils.isBlank(url)) { return "url不能为空"; } // 创建http GET请求 //logger.info("url:{}", url); HttpGet httpGet = new HttpGet(url); // 设置请求和传输超时时间 httpGet.setConfig(requestConfig); String result = ""; try (CloseableHttpClient httpclient = HttpClients.createDefault();// 创建Httpclient对象 CloseableHttpResponse response = httpclient.execute(httpGet);// 执行请求 ) { int statusCode = response.getStatusLine().getStatusCode(); if (statusCode == HttpStatus.SC_OK) { result = EntityUtils.toString(response.getEntity(), chaset); //logger.info("HttpGet方式请求成功!返回结果:{}", result); } else { // logger.info("HttpGet方式请求失败!状态码:" + statusCode); } } catch (IOException e) { e.printStackTrace(); } return result; } /** * 发送 GET 请求(HTTP),有参数 * * @param url * @param params * @return */ public static String doGet(String url, Map params) { if (null != params) { StringBuffer extraUrl = new StringBuffer(); int temp = 0; for (String key : params.keySet()) { if (temp == 0) { extraUrl.append("?"); } else { extraUrl.append("&"); } extraUrl.append(key).append("=").append(params.get(key)); temp++; } url += extraUrl; } return doGet(url); } /** * 发送 POST 请求(HTTP),无参数 * * @param url * @return */ public static String doPost(String url) { return doPost(url, null); } /** * 发送 POST 请求(HTTP),有参数 * * @param url * @return */ public static String doPost(String url, Map params) { // 创建http POST请求 HttpPost httpPost = new HttpPost(url); httpPost.setConfig(requestConfig); httpPost.setHeader("Content-Type", "application/json"); if (params != null) { httpPost.setEntity(new StringEntity(JSON.toJSONString(params), ContentType.create("application/json", "utf-8"))); } String result = ""; try (CloseableHttpClient httpclient = HttpClients.createDefault();// 创建Httpclient对象 CloseableHttpResponse response = httpclient.execute(httpPost);// 执行请求 ) { //logger.info("httpPost:{}", httpPost); int statusCode = response.getStatusLine().getStatusCode(); if (statusCode == HttpStatus.SC_OK) { result = EntityUtils.toString(response.getEntity(), chaset); //logger.info("HttpPost方式请求成功!返回结果:{}", result); } else { //logger.info("HttpPost方式请求失败!状态码:" + statusCode); } } catch (IOException e) { e.printStackTrace(); } return result; } /** * 发通过url下载视频,下载到默认目录D:\video\,下载的文件名是数字 * * @param url * @return */ public static String downloadVideo(String url) { return downloadVideo(url, null, videoDownLoadPath); } /** * 发通过url下载视频,默认下载到D:\video\,文件名是传入的fileName * * @param url * @param fileName 下载到本地的文件名 * @return */ public static String downloadVideo(String url, String fileName) { return downloadVideo(url, fileName, videoDownLoadPath); } /** * 发通过url下载视频,下载的视频文件名是数字 * * @param url * @param fileName 保存的视频名,为空则保存为数字 * @param filepath 下载到本地的路径,为空则保存到默认路径D:\video\ * @return */ public static String downloadVideo(String url, String fileName, String filepath) { String filename = ""; try { if (StringUtils.isBlank(url)) { return "url不能为空"; } //获取视频流 HttpClient client = HttpClients.createDefault(); HttpGet httpget = new HttpGet(url); HttpResponse response = client.execute(httpget); HttpEntity entity = response.getEntity(); InputStream is = entity.getContent(); //文件保存路径为空则使用默认路径 if (StringUtils.isBlank(filepath)) { filepath = videoDownLoadPath; } //filepath不是斜杠结束的在末尾添加斜杠 if (filepath.length() - 1 != filepath.lastIndexOf("\\")) { filepath += "\\"; } //如果没有文件夹,则创建 File file = new File(filepath); if (!file.exists() && !file.isDirectory()) { file.mkdirs(); } if (StringUtils.isBlank(fileName)) { //获取文件夹下的文件数量,文件数量加一作为要下载的文件名 int fileCount = 0; File[] list = file.listFiles(); for (int i = 0; i fileCount++; } } fileCount += 1; filename = filepath + fileCount + ".mp4"; } else { //windows里文件名不能有特殊符号,fileName里去除\/:*?"| fileName = fileName.replaceAll(":", "").replaceAll("\\?", "") .replaceAll("\"", "").replaceAll("\\|", "") .replaceAll("/", "").replaceAll("\\\\", "") .replaceAll("\\*", "").replaceAll("\\", ""); //fileName作为要下载的文件名 filename = filepath + fileName + ".mp4"; } //如果文件不存在则创建文件 File file_name = new File(filename); if (!file_name.exists()) { //创建文件 file_name.createNewFile(); } //视频流写入文件 FileOutputStream fileout = new FileOutputStream(file_name); BufferedInputStream buf = new BufferedInputStream(is); byte[] buffer = new byte[1024]; int ch = 0; while ((ch = buf.read(buffer)) != -1) { fileout.write(buffer, 0, ch); } is.close(); fileout.flush(); fileout.close(); } catch (Exception e) { e.printStackTrace(); } return "下载成功!文件名:" + filename + ",url:" + url; } }下载测试: import utils.Douyin; import utils.HttpUtil; import java.io.IOException; import java.util.*; public class Test { public static void main(String[] args) throws IOException { Douyin douyin = new Douyin(); Map map = douyin.getAllVideoUrlToMap(); int count = 1; System.out.println("-------------------------------------------------------------"); System.out.println(" "); System.out.println("共" + map.size() + "个视频,开始下载"); System.out.println("-------------------------------------------------------------"); System.out.println(" "); for (Map.Entry m : map.entrySet()) { System.out.println("开始下载第" + count + "个视频,视频信息:" + m.getKey()+",url:"+m.getValue()); String a= HttpUtil.downloadVideo(m.getValue()); System.out.println("第" + count + "个视频下载完成!"); System.out.println(" "); count += 1; } } }
参考: 抖音平台分析 抖音X-GorgonXgorgon等参数算法在线生成算法 抖音APP接口分析 抖音爬虫解决方案 获取用户视频/信息 java+appium1.7.2+夜神模拟器+fiddler4 抖音APP的视频数据采集方法(简书首发) 抖音短视频x-gorgon算法入口定位查找过程笔记 Android 反编译利器,jadx 的高级技巧 |


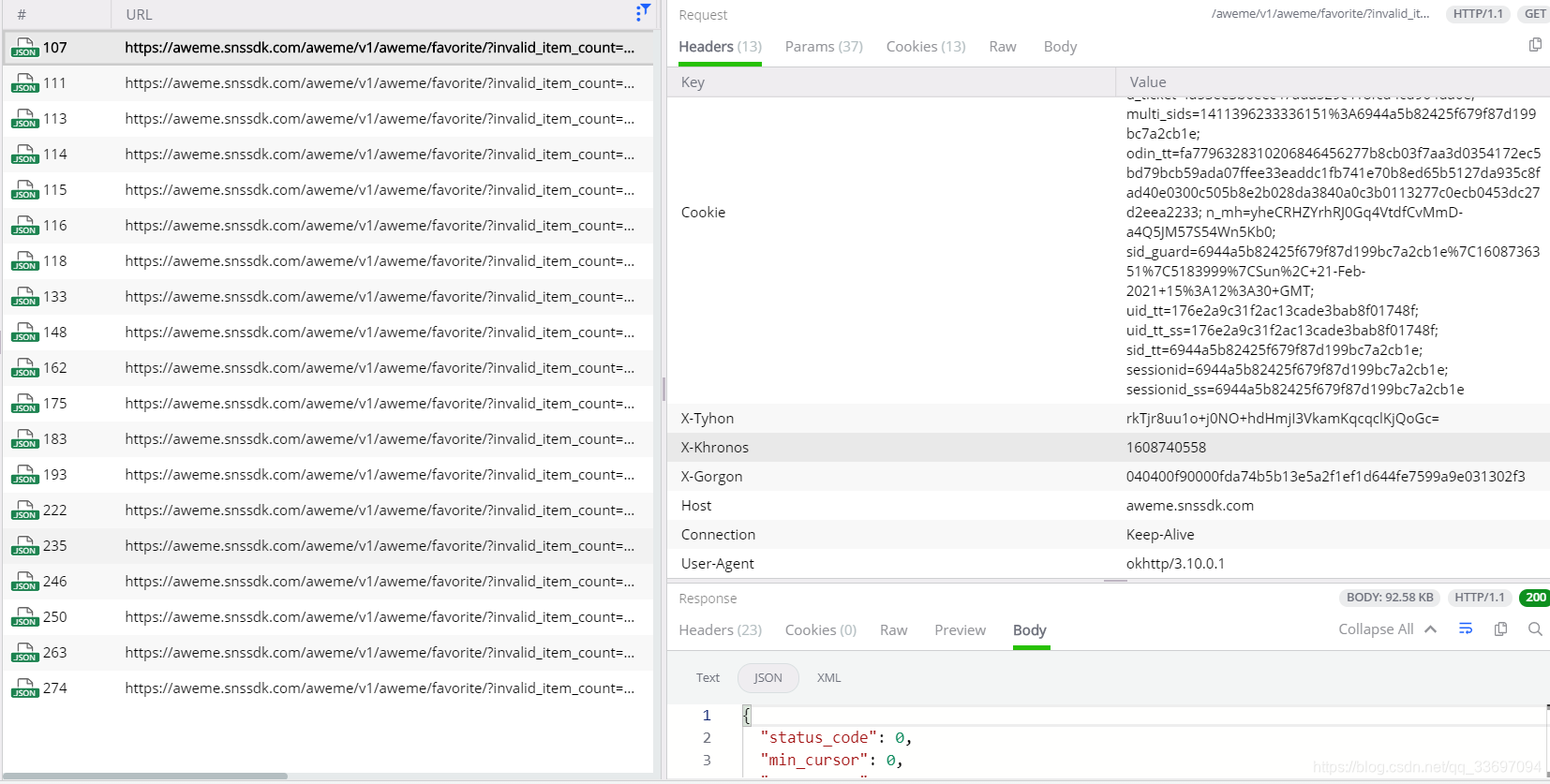
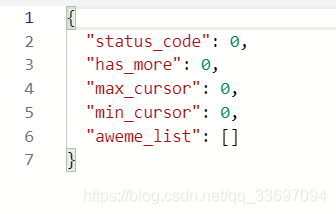 估计是headers部分的参数有对params进行了md5校验,所以修改了参数校验不通过导致没有数据返回。
估计是headers部分的参数有对params进行了md5校验,所以修改了参数校验不通过导致没有数据返回。
 太难顶了。
太难顶了。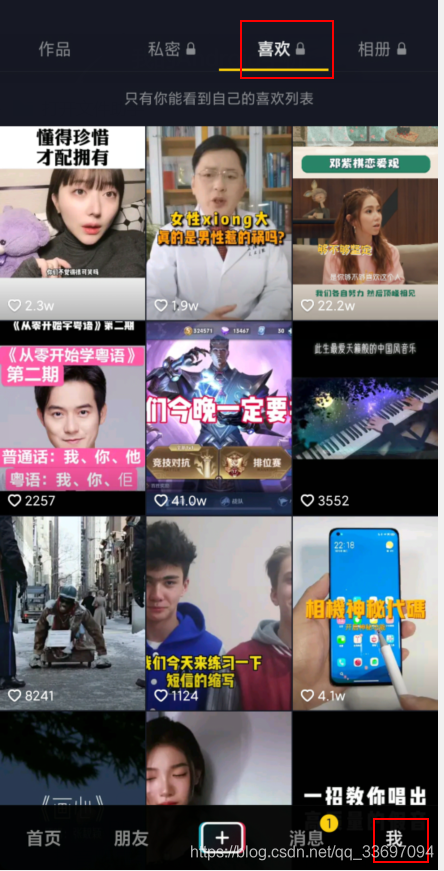
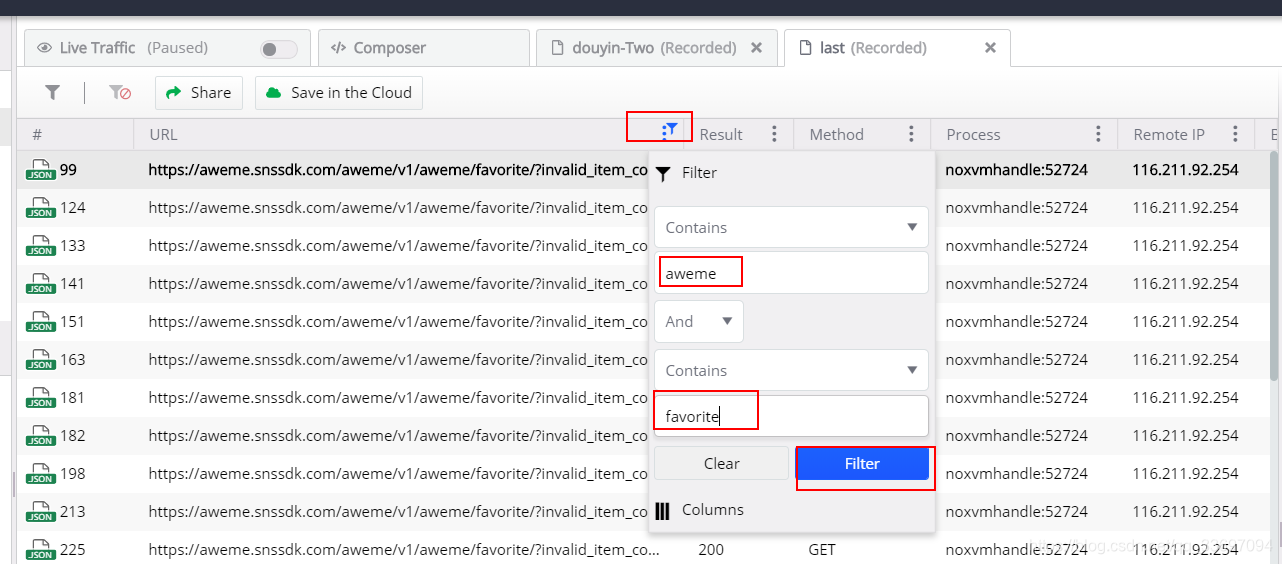 过滤出的请求就是所有喜欢列表的的请求,每个请求里的响应就包含了视频url、封面、描述等信息。
过滤出的请求就是所有喜欢列表的的请求,每个请求里的响应就包含了视频url、封面、描述等信息。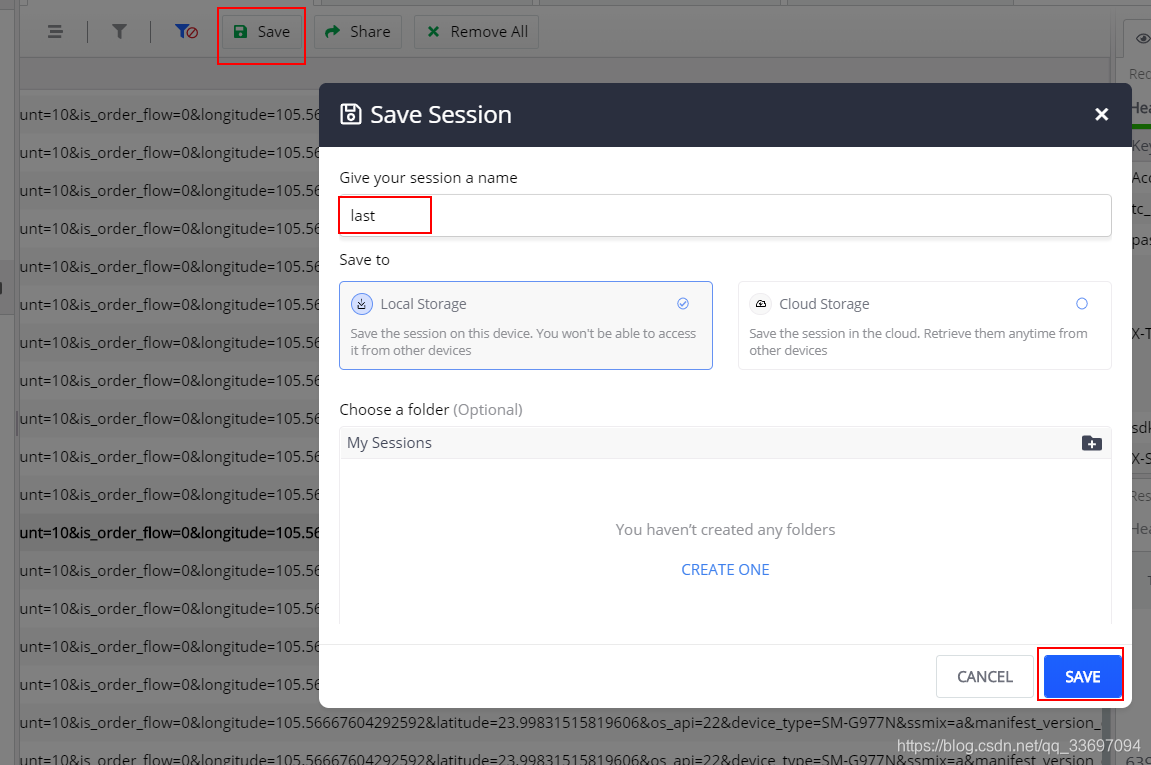
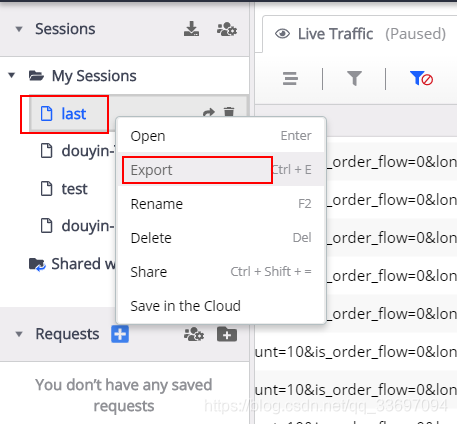
 5.写代码解析上面获得的响应文件,从响应文件中获取url和视频信息,然后通过url下载视频。
5.写代码解析上面获得的响应文件,从响应文件中获取url和视频信息,然后通过url下载视频。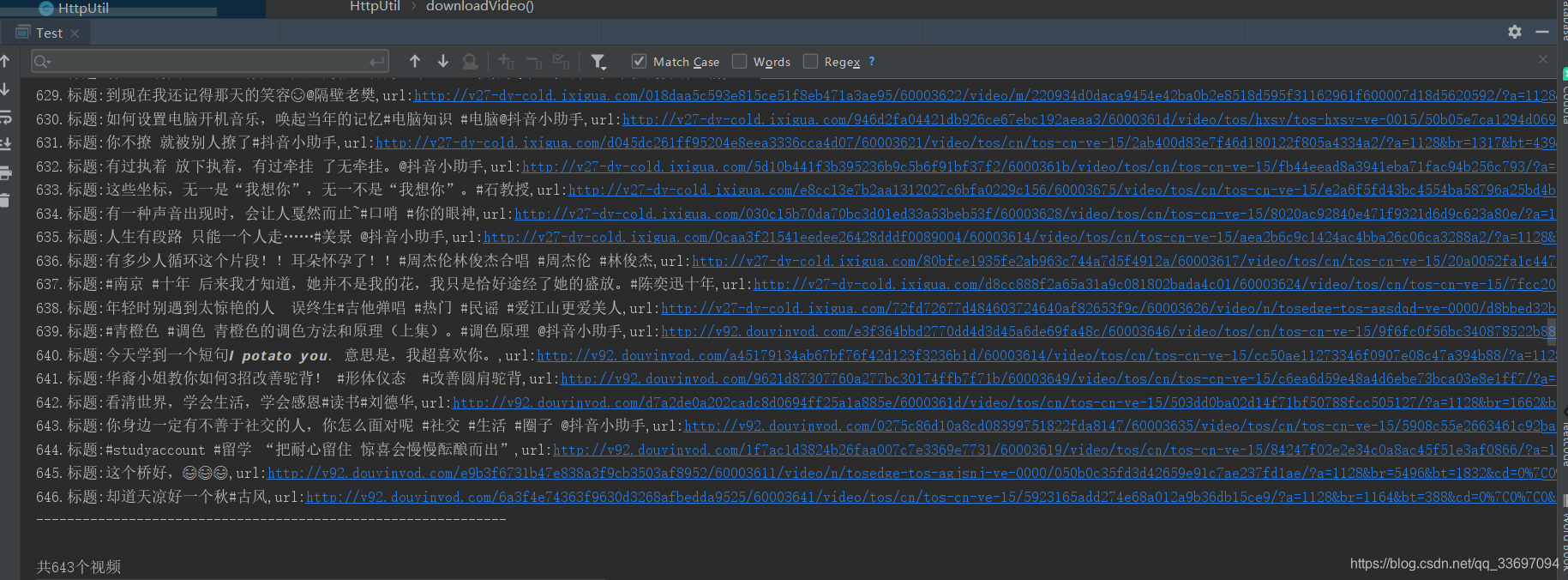
 至此,完结!
至此,完结! 
【本文地址】