| 火爆全网的“蚂蚁呀嘿”AI变脸特效,是如何实现的? | 您所在的位置:网站首页 › 抖音很火的号 › 火爆全网的“蚂蚁呀嘿”AI变脸特效,是如何实现的? |
火爆全网的“蚂蚁呀嘿”AI变脸特效,是如何实现的?
|
当互联网大佬们集体唱歌,会擦出怎样的火花?现在,火爆抖音的AI特效,一键就可以实现梦幻联动。 最近你是不是也被“蚂蚁牙黑”刷屏?打开任意一个社交软件,都可能被这个魔性的音乐洗脑!
 简单点说,就是把一张静态照片,通过软件制作成一个的动态小视频魔性的表情,加上洗脑的音乐,给不少人带来一波欢乐。 效果之魔性,有网友表示,最近是咋滴啦?!一打开抖音,好像捅了蚂蚁窝。  只需要一张照片 大家一起“蚂蚁呀嘿”! 这款火遍全网的AI特效,只需要一张照片,火速让任何人都可以“蚂蚁呀嘿”。正因为这么便捷,果不其然,马上成为了抖音网友们的“新宠”。  “永不过时”的《还珠格格》,也赶上了这趟潮流列车。  王者峡谷里的英雄们,网友们也是没有放过。  除了上面这种九宫格模式外,高端的操作还可以实现集体同框。于是,“爱玩”的德云社就以这种方式亮相了。  AI黑科技是如何 让照片“动起来唱歌”? AI,是如何搞定各位大佬来唱歌的呢? 让一张照片动起来,人脸跟着音乐一起挤眉弄眼,需要一个叫做一阶运动模型 (First Order Motion Model)来搞定。 技术原理借鉴了去年意大利特伦托大学的一项研究,入选了NIPS 2019。  当时的例子是这样的。  以川建国同志为参考,来自《冰与火之歌》的演员照片瞬间做到了神同步。 不光是脸动,一个模特换pose、奔腾的马也都不在话下。  模型框架主要由2部分构成,运动估计模块和图像生成模块。 运动估计模块的目的,是预测一个密集的运动场。研究人员假设存在一个抽象的参考框架,并且独立估计两个变换,分别是“从参考到源”和“从参考到驱动”,这样就能够独立处理源帧和驱动帧。 而这两种变换,通过使用以自监督方式学习的关键点来获得。利用局部仿射变换对每个关键点附近的运动进行建模。 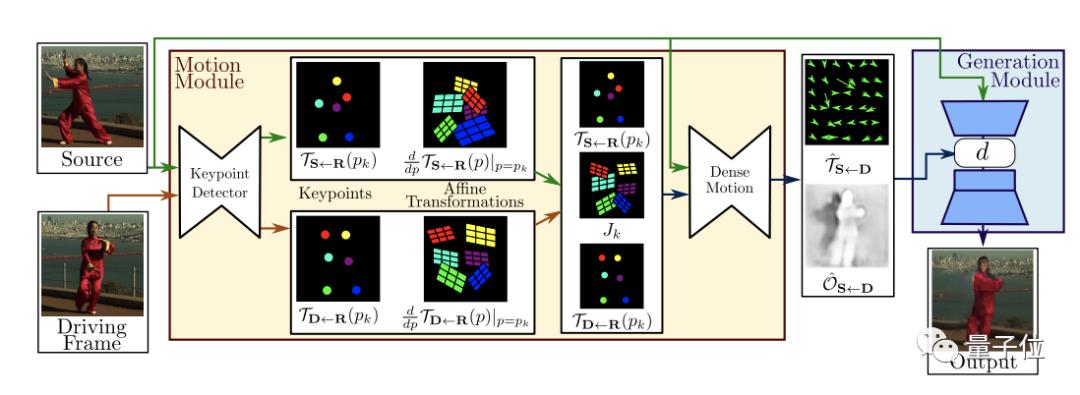 随后,密集运动网络结合局部近似得到密集运动场。 这个网络还能输出遮挡的mask,指示哪些图像的驱动部分可以通过源图像的扭曲(warping)来重建,哪些部分应该被绘制(根据上下文推断)。 在生成模块按照驱动视频中,提供的源对象移动的图像进行渲染。 此处,研究人员还使用一个生成器网络,根据密集的运动对源图像进行扭曲,并对源图像中被遮挡的图像部分进行着色。 训练阶段,研究人员采用了大量的视频序列集合来训练模型,这当中包含了相同类别的对象。  随后在测试阶段,研究人员将模型应用于由源图像和驱动视频的每一帧组成的对,并执行源对象的图像动画。 最终在质量评估中,这一方法在所有基准上都明显优于当前先进技术。 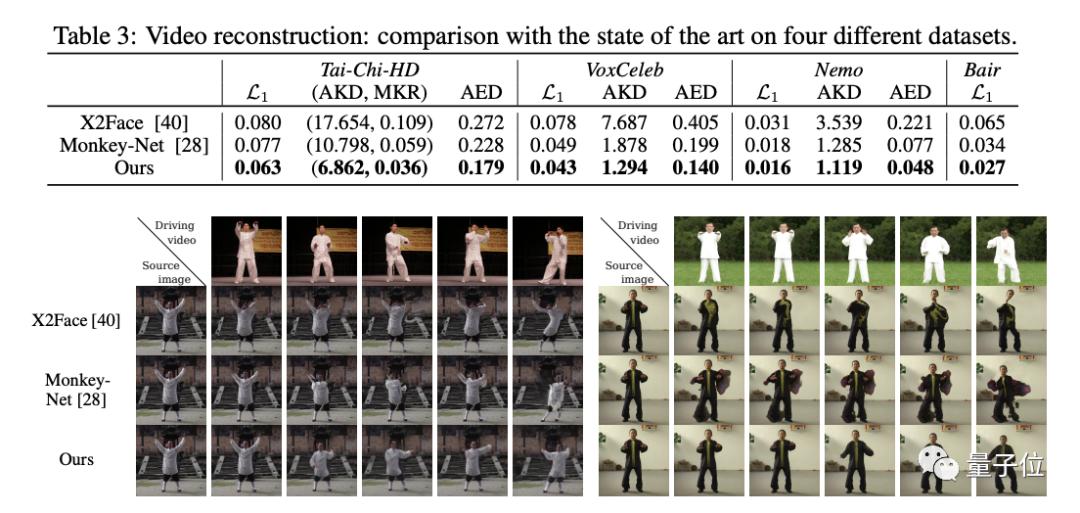 此前类似研究也很火爆 这种AI特效能够如此火爆,甚至“破圈”,让大家玩得不亦乐乎,最主要的原因是方便——不需要任何编程知识,便可完成。 但在此之前,其实这种AI特效在圈里也是有火过,但都需要一定的计算机能力才可以实现。 比如,一张名人照片和一个你说话的视频,就可以让梦露学你说话。  还有印度程序员开发的实时动画特效。你一动,蒙娜丽莎跟着你一起动。  跟风玩AI特效? 当心存在侵犯肖像权风险! “蚂蚁呀嘿”虽然很有趣 但还是有必要提醒一下大家 如果使用别人的照片进行制作 可能还存着侵犯肖像权的风险 如果把自己清晰的正面照片上传 一旦“丢脸”将面临哪些风险? ↓↓↓ 滑动查看详细规定 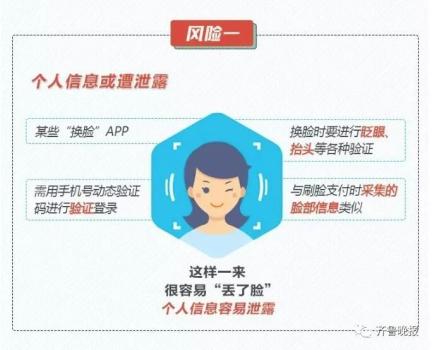 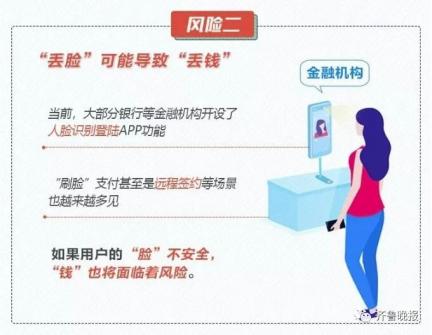 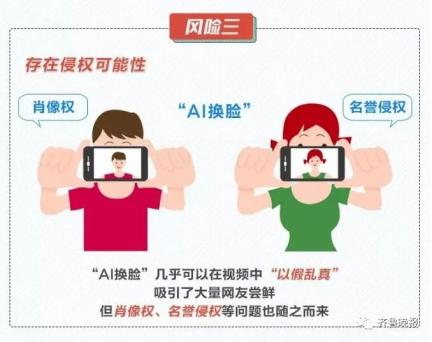 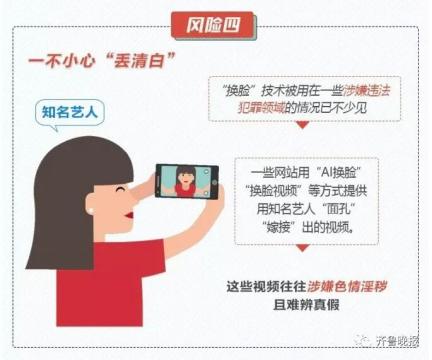 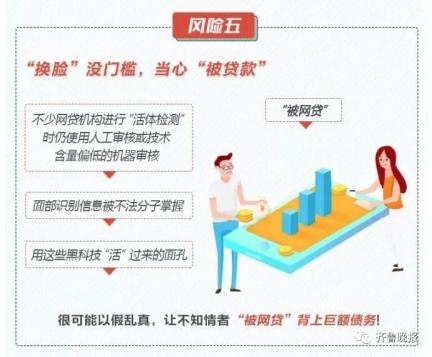 虽然说这些都是潜在的风险 但大家开心的同时 还是要注意: 跟风虽快乐,风险需自知 今日推荐视频 智能手环抢着增加的这个新功能 厉害在哪里? 近年来智能手环厂商争相增加 监测“血氧饱和度”功能 这个指标重要在哪里? 小小一个手环又如何监测? 热门阅读 (点击图片即可阅读) 原标题:《火爆全网的“蚂蚁呀嘿”AI变脸特效,是如何实现的?》 阅读原文 |
【本文地址】