| Hadoop学习(12) | 您所在的位置:网站首页 › 批量注册陌陌流程图怎么做的 › Hadoop学习(12) |
Hadoop学习(12)
|
1 陌陌聊天数据分析案例需求
1.1 目标
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表。
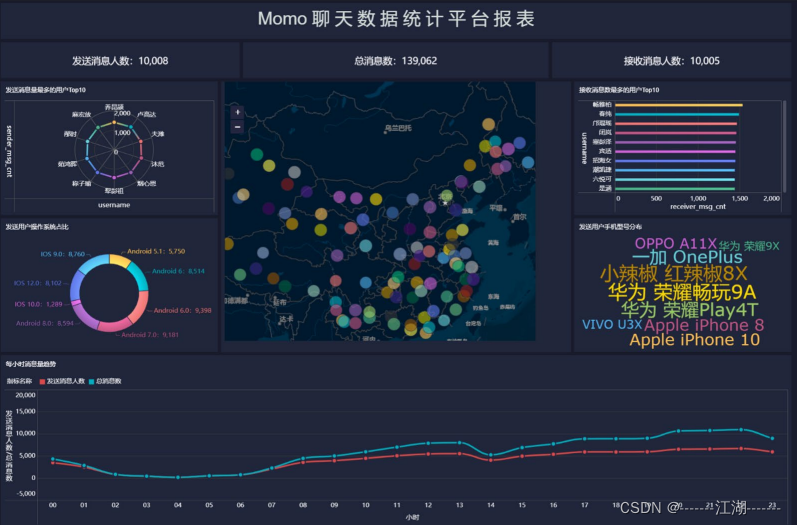
数据来源:聊天业务系统中导出的2021年11月01日一天24小时的用户聊天数据,以TSV文本形式存储在文件中。 查看结果 select msg_time,dayinfo,hourinfo,sender_gps,sender_lng,sender_lat from db_msg.tb_msg_etl limit 10; 2.3 需求指标统计 2.3.1 指标1:统计今日消息总量 --保存结果表 create table if not exists tb_rs_total_msg_cnt comment "今日消息总量" as select dayinfo, count(*) as total_msg_cnt from db_msg.tb_msg_etl group by dayinfo; 2.3.2 指标2:统计每小时消息量、发送和接收用户数 --保存结果表 create table if not exists tb_rs_hour_msg_cnt comment "每小时消息量趋势" as select dayinfo, hourinfo, count(*) as total_msg_cnt, count(distinct sender_account) as sender_usr_cnt, count(distinct receiver_account) as receiver_usr_cnt from db_msg.tb_msg_etl group by dayinfo,hourinfo; 2.3.3 指标3:统计今日各地区发送消息总量 --保存结果表 create table if not exists tb_rs_loc_cnt comment "今日各地区发送消息总量" as select dayinfo, sender_gps, cast(sender_lng as double) as longitude, cast(sender_lat as double) as latitude, count(*) as total_msg_cnt from db_msg.tb_msg_etl group by dayinfo,sender_gps,sender_lng,sender_lat; 2.3.4 指标4:统计今日发送和接收用户人数 --保存结果表 create table if not exists tb_rs_usr_cnt comment "今日发送消息人数、接受消息人数" as select dayinfo, count(distinct sender_account) as sender_usr_cnt, count(distinct receiver_account) as receiver_usr_cnt from db_msg.tb_msg_etl group by dayinfo; 2.3.5 指标5:统计发送消息条数最多的Top10用户 --保存结果表 create table if not exists tb_rs_susr_top10 comment "发送消息条数最多的Top10用户" as select dayinfo, sender_name as username, count(*) as sender_msg_cnt from db_msg.tb_msg_etl group by dayinfo,sender_name order by sender_msg_cnt desc limit 10; 2.3.6 指标6:统计接收消息条数最多的Top10用户 --保存结果表 create table if not exists tb_rs_rusr_top10 comment "接受消息条数最多的Top10用户" as select dayinfo, receiver_name as username, count(*) as receiver_msg_cnt from db_msg.tb_msg_etl group by dayinfo,receiver_name order by receiver_msg_cnt desc limit 10; 2.3.7 指标7:统计发送人的手机型号分布情况 --保存结果表 create table if not exists tb_rs_sender_phone comment "发送人的手机型号分布" as select dayinfo, sender_phonetype, count(distinct sender_account) as cnt from tb_msg_etl group by dayinfo,sender_phonetype; 2.3.8 指标8:统计发送人的操作系统分布 --保存结果表 create table if not exists tb_rs_sender_os comment "发送人的OS分布" as select dayinfo, sender_os, count(distinct sender_account) as cnt from tb_msg_etl group by dayinfo,sender_os; 3 基于FineBI实现可视化报表 3.1 FineBI的介绍及安装 FineBI 是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品。FineBI 是定位于自助大数据分析的 BI 工具,能够帮助企业的业务人员和数据分析师,开展以问题导向的探索式分析。FineBI的特点 通过多人协作来实现最终的可视化构建不需要通过复杂代码来实现开发,通过可视化操作实现开发适合于各种数据可视化的应用场景支持各种常见的分析图表和各种数据源支持处理大数据 3.2 FineBI配置数据源及数据准备 FineBI与Hive集成的官方文档 3.2.1 驱动配置 问题:如果使用FineBI连接Hive,读取Hive的数据表,需要在FineBI中添加Hive的驱动jar包。解决:将Hive的驱动jar包放入FineBI的lib目录下。 找到提供的【Hive连接驱动】
将这些文件放入FineBI的安装目录下的:webapps\webroot\WEB-INF\lib目录中。 3.2.2 插件安装 问题:我们自己放的Hive驱动包会与FineBI自带的驱动包产生冲突,导致FineBI无法识别我们自己的驱动包。解决:安装FineBI官方提供的驱动包隔离插件。 找到隔离插件
|













【本文地址】
公司简介
联系我们