| 手机上UC浏览器书签导出备份为HTML文件并导入到其他浏览器的方法 python实现 | 您所在的位置:网站首页 › 手机uc浏览器的收藏怎么导出 › 手机上UC浏览器书签导出备份为HTML文件并导入到其他浏览器的方法 python实现 |
手机上UC浏览器书签导出备份为HTML文件并导入到其他浏览器的方法 python实现
|
文章目录
前言一、迁移方案二、相关代码及过程***运行代码前记得换 cookie和 x-csrf-token,自己浏览器F12开发者工具找***
三、导入其他浏览器总结
前言
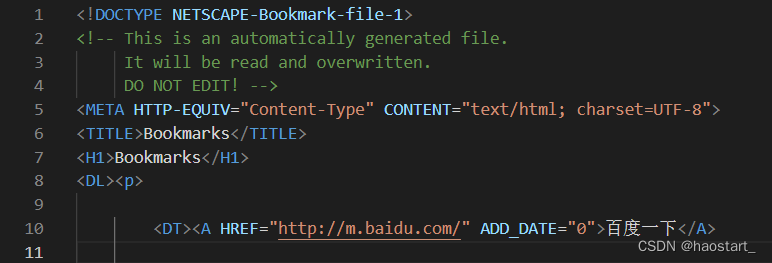
由于历史惯性等原因,手机上一直使用的UC浏览器,用了这么多年。 最近觉得Via浏览器比较简洁方便,所以准备切换过去,那我最宝贵的书签肯定要迁移过去的, 但万恶的资本家不想你这么做,你要走了我的钱怎么办? 所以UC浏览器离谱的没有书签导出功能(以前有),气死我了,正好自己会Python,于是就有了这篇文章。 一、迁移方案 通过UC云的API获取到所有书签。将书签保存为HTML格式的导出文件,方便其他浏览器导入。 登陆UC云获取到token和cookies 通过UC云的API获取到所有书签 将书签保存为HTML格式的导出文件方便其他浏览器导入最后要变成的书签HTML文件格式如下图所示: 首先进入书签官网,登陆进去: https://cloud.uc.cn/home/phone UC书签官网 然后浏览器按F12进入开发者模式,按图点
记得换 下面代码的cookie和 x-csrf-token 记得换 cookie和 x-csrf-token 记得换 cookie和 x-csrf-token 只需简单一点代码,Github同样代码 import json,requests,time host = f'https://cloud.uc.cn/api/bookmark/listdata' headers = { 'Accept': 'application/json, text/plain, */*', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-Hans-CN, zh-Hans; q=0.5', 'Connection': 'Keep-Alive', 'origin': 'https://cloud.uc.cn', 'referer': 'https://cloud.uc.cn/home/phone', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36', 'x-csrf-token': 'okpv0j1zpChodmXpmlilE9X5', #这里换上自己的token,登录后在浏览器开发者工具里找。 'cookie': r"123" #这里换上自己的cookie,登录UC云后在浏览器开发者工具里找。 } session = requests.session() count=0 def get_text(guid): global text global count for i in range(1,200): #假设最多加载200页,有200多页书签的话改这里 time.sleep(0.1) post_data={'cur_page': i, 'type': "phone", 'dir_guid': str(guid)} response = session.post(host, headers=headers,data=post_data).json() print(f'dir_guid: {guid} cur_page:{i} ') if response['msg']!='ok': print(f"i:{i},quit{response['msg']}") break try: data=response['data']['list'] print(f'i:{i}') except: print('error') continue for book in data: if book['is_directory']==1: #如果是书签目录,则递归调用,相当于DFS print('it is a directory') bk=f"\t{book['name']}\n\t\n" text+=bk get_text(book['guid']) #这里是递归遍历目录 text+="\t \n" else: bk=f"\t |
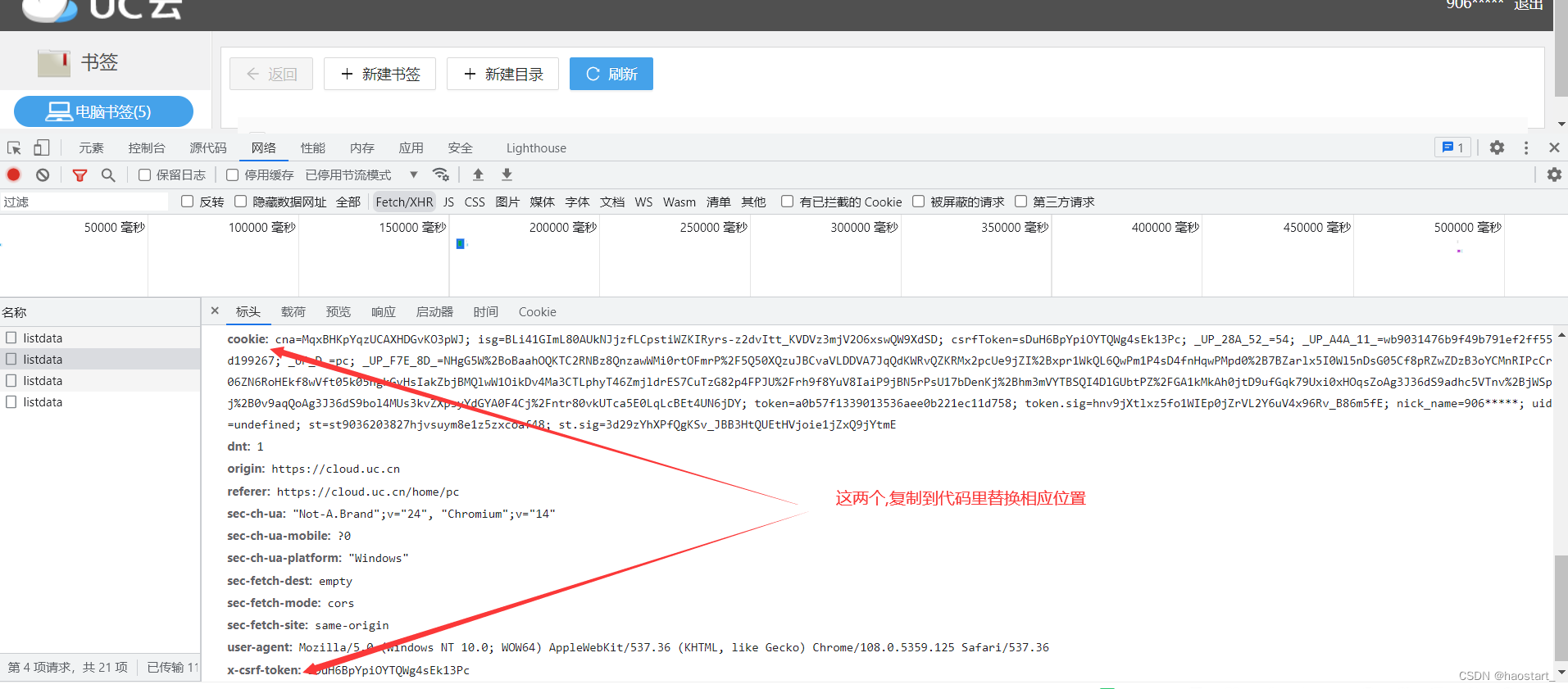
 然后刷新书签页面
然后刷新书签页面 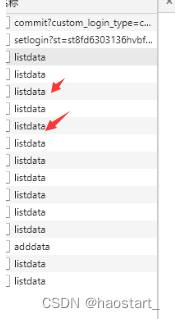 随便选一个listdata,然后找到cookie和 token,将它们的值放到代码相应位置.
随便选一个listdata,然后找到cookie和 token,将它们的值放到代码相应位置. 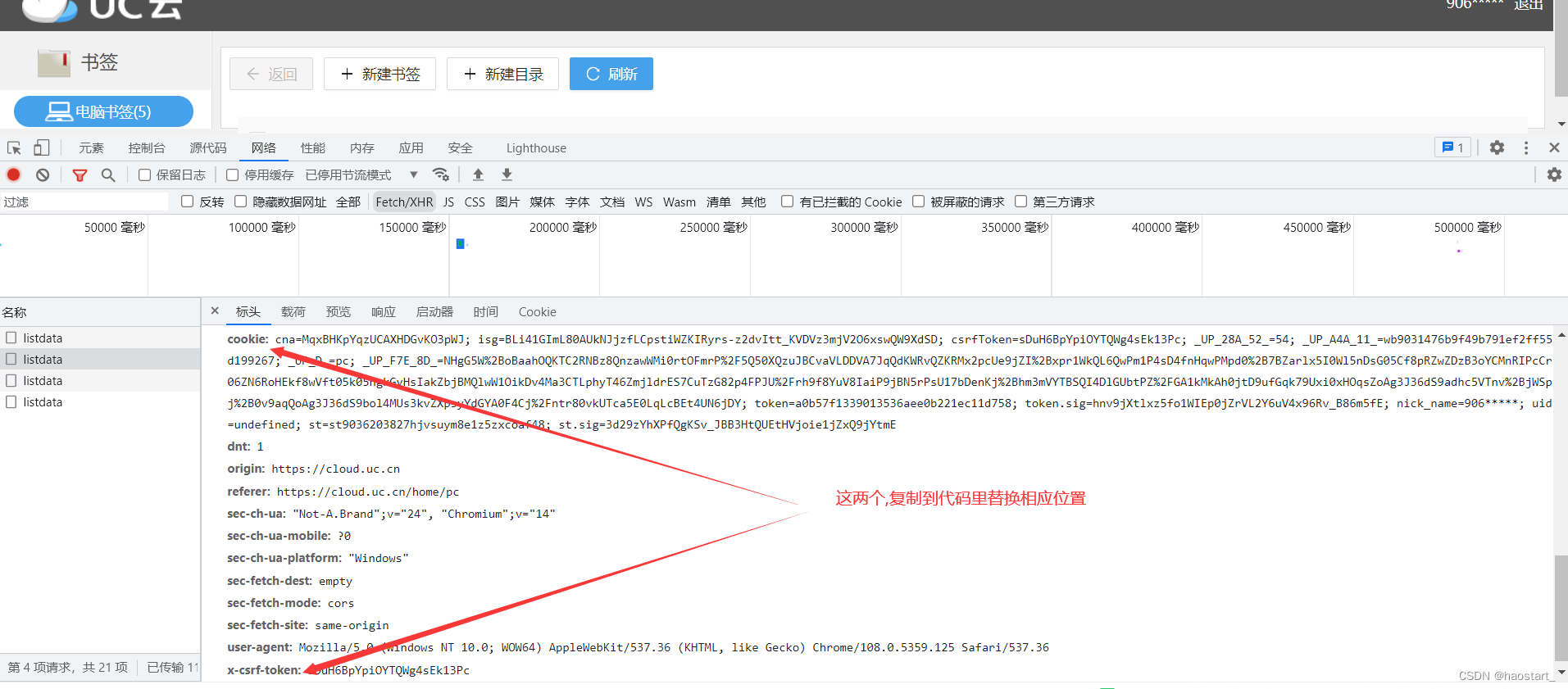

【本文地址】
公司简介
联系我们