| 常见的判断网站cms方法 | 您所在的位置:网站首页 › 怎样识别海鱼名称 › 常见的判断网站cms方法 |
常见的判断网站cms方法
|
今天有同事给了个域名让我判断这个是什么cms,判断完后记录一下cms的几种判断方法。 1.robots.txt文件robots.txt文件我们写过爬虫的就知道,这个文件是告诉我们哪些目录是禁止爬取的。但是大部分的时候我们都能通过robots.txt文件来判断出cms的类型 如: 从wp路径可以看出这个是WordPress的cms 这个就比较明显了直接告诉我们是PageAdmin cms 也有些robots.txt里面写得不是很清楚。我们看看织梦的
从robots.txt不能直接看出来是什么cms,我们就直接把他复制到百度去查询
这样就找到了是织梦的cms 2.通过版权信息进行查询 一般直接拉到底部查看版权信息,有些站点会显示出来,比如织梦这个
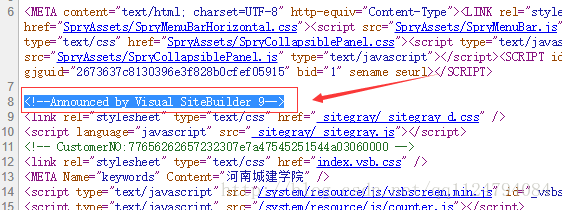
3.通过查看网页源码的方式 有些站点没有robot.txt,也把版本信息改了,这时候首页查看网页源码可能找得到,如图
4.通过比较网站md5值 有些cms的扫描器就是用这个原理的,先收集某个cms的某个路径的文件的md5值,要求这个文件一般不会被使用者修改的。然后访问这个网站同样的路径下是否存在这个文件,存在的话比较md5值。相同能报出cms类型。这个比较考验字典的能力。
|





【本文地址】
公司简介
联系我们