| unet++:使用自己的数据测试效果 | 您所在的位置:网站首页 › 怎样测量自己是不是胖 › unet++:使用自己的数据测试效果 |
unet++:使用自己的数据测试效果
|
问题:为什么换数据后,val模块报错?
最近跑了一下unet++模型(网上和B站上有源码),直接进入主题:写模块跑自己的图像。 但是里面不知道怎么去测试自己的图片,里面只有验证的代码模块:
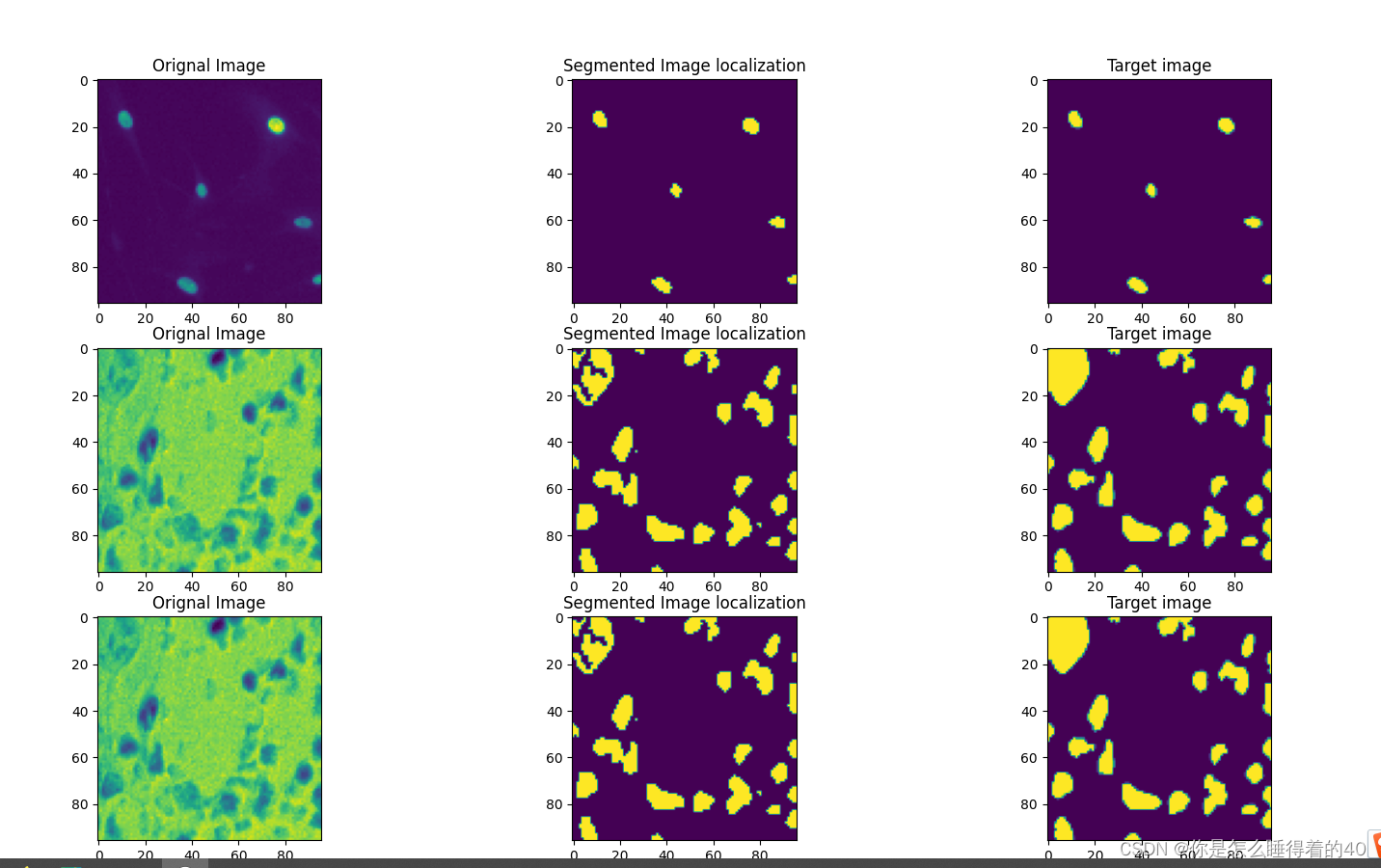
环境配置好了以后,跑出来的结果是这样:
这里面他是从input里面划分的部分数据集随机抽取的几张图片,再用模型分割的。 那么我想用自己的几张数据去用这个模型,只要换一下数据就行了吗? 然后并不是,换了数据之后,或者是裁剪一半input里面的数据之后马上报错,报错的源头来自于dataloder: 当我更改dataset的目录时候,img_ids和msk_dir改成自己想要的路径。 val_dataset = Dataset( img_ids=val_img_ids, img_dir=os.path.join('predict', 'images'), mask_dir=os.path.join('predict', , 'masks'), img_ext=config['img_ext'], mask_ext=config['mask_ext'], num_classes=config['num_classes'], transform=val_transform) print('yoyoyo',val_dataset) val_loader = torch.utils.data.DataLoader( val_dataset, batch_size=config['batch_size'], # 发送数据的吞吐量 shuffle=False, # =True打乱数据集 num_workers=config['num_workers'], # 工作进程数量,过大寻batch快(cpu负载大),根据电脑配置设置 drop_last=False) # 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch for input, target, meta in tqdm(val_loader, total=len(val_loader)): # 设置进度条 print("input\n",input.shape) input = input.cuda() target = target.cuda()运行以后上面的for循环就会报错,原因是input读不出来信息。 写新的predict模块上面的问题,应该是源自我没能把tqdm原理搞明白,或者是val_loader里面打印的时候只返回二进制,没有有用的信息,那我只好另外写新的代码了。 首先进入config.yml看看网络的结构:
这是网络输入的时候要求【3,96,96】的张量,(但是在后面他要求输入四维张量,后面再说) 在开始之前借用一下val.py里面的权重导入: def parse_args(): parser = argparse.ArgumentParser() parser.add_argument('--name', default=None, help='model name') args = parser.parse_args() return args def main(): args = parse_args() with open('models/dsb2018_96_NestedUNet_woDS/config.yml', 'r') as f: # 加载训练权重 config = yaml.load(f, Loader=yaml.FullLoader) # 读取为字典 print('-'*20) for key in config.keys(): # 按键打印 print('%s: %s' % (key, str(config[key]))) # 打印训练结果数据 print('-'*20) cudnn.benchmark = True # 为各层搜索卷积层最适合的卷积算法。 # create model print("=> creating model %s" % config['arch']) model = archs.__dict__[config['arch']](config['num_classes'], # config里面的属性字典 config['input_channels'], config['deep_supervision']) # model = model() model = model.cuda() # 调GPU首先第一步是导入图片,这里使用CV2导入 # 导入测试图片 img0=cv2.imread('test0/test1.png') # print(img0) model.load_state_dict(torch.load('models/%s/model.pth' % config['name'])) # 加载模型参数(.pth文件) model.eval() # 使用model.eval()时就是将模型切换到测试模式,在这里,模型就不会像在训练模式(model.train)下一样去更新权重。第二步是对我们数据的尺寸处理,尺寸必须是符合网络输入尺寸的,input_H和input_w也是要相应对应,这段代码在train和val.py里面都有相应的。 val_transform = Compose([ albu.Resize(config['input_h'], config['input_w']), albu.Normalize(), # 重组输入尺寸,标准化 ])在这一步中切记要先定义val=albu.Resize()(只写一个示例),然后再去调用input=val(img0): 然后打印一下input,它的数据是numpy,而模型需要的是tensor数据。(具体可以去看看网上numpy和tensor之间的转换) 为了方面我把尺寸归一化和tensor化写在一起: predict_transforms = transforms.Compose([transforms.ToPILImage(), # Here transforms.RandomHorizontalFlip(), transforms.Resize((96, 96)), transforms.ToTensor()])接下来只需要去调用即可: img=predict_transforms(img0)第三步,这时候又出现了一个问题,我用三维张量【3,96,96】(print(img.shape)就能看到)去输入模型的时候它却要求输入的是四维张量,然后我回到val打印input的时候: 那只好再去构建一下张量,它这里的2是来自于Dataloder里面的一个参数batch_size(自己可以去了解一下,很重要的一个东西)。而这里面的2就是图片数量 那我自己只有一张图片需要测试,那么: input = img.reshape(1, 3, 96, 96) # 将三维张量变为四维张量这就解决了输入问题: 第四步,那就是一阵哐哐哐代入模型了: input = input.cuda() output = model(input) # outputs = model.__call__(forward(inputs)) output = torch.sigmoid(output).cpu().detach().numpy() # output掩码, # 待转换类型的PyTorch Tensor变量带有梯度,直接将其转换为numpy数据将破坏计算图。 # 如果自己在转换数据时不需要保留梯度信息,可以在变量转换之前添加detach()调用。 for i in range(len(output)): for c in range(config['num_classes']): cv2.imwrite(os.path.join('test', 'predict.jpg'), # 预测图像保存路径 (output[i, c] * 255).astype('uint8')) # 掩码转换为png torch.cuda.empty_cache() # 清空显存缓冲区 |


【本文地址】