| 使用Python提取PDF文件中指定页面的内容 | 您所在的位置:网站首页 › 怎么复制pdf的某些页码 › 使用Python提取PDF文件中指定页面的内容 |
使用Python提取PDF文件中指定页面的内容
|
在日常工作和学习中,我们经常需要从PDF文件中提取特定页面的内容。在本篇文章中,我们将介绍如何使用Python编程语言和两个强大的库——pymupdf和wxPython,来实现这个任务。 1. 准备工作首先,确保你已经安装了以下两个Python库: pymupdf:用于处理PDF文件的库,提供了读取、提取和创建PDF文件的功能。wxPython:一个基于wxWidgets的Python包,用于创建跨平台的图形用户界面(GUI)应用程序。你可以使用以下命令通过pip安装这两个库: pip install pymupdf wxPython 2. 创建GUI应用程序首先,我们将创建一个简单的GUI应用程序,它将允许用户选择要打开的PDF文件,并输入开始页码和结束页码。然后,点击"Extract"按钮将提取指定范围内的页面并将其保存为新的PDF文件。 D:\spiderdocs\splitPDFfromx2y.py import fitz import wx class PDFExtractor(wx.Frame): def __init__(self, parent, title): super(PDFExtractor, self).__init__(parent, title=title, size=(400, 200)) self.panel = wx.Panel(self) self.file_picker = wx.FilePickerCtrl(self.panel, style=wx.FLP_DEFAULT_STYLE | wx.FLP_USE_TEXTCTRL) self.start_page_input = wx.TextCtrl(self.panel) self.end_page_input = wx.TextCtrl(self.panel) self.extract_button = wx.Button(self.panel, label="Extract", size=(100, 30)) self.extract_button.Bind(wx.EVT_BUTTON, self.extract_pages) self.sizer = wx.BoxSizer(wx.VERTICAL) self.sizer.Add(self.file_picker, 0, wx.EXPAND|wx.ALL, 10) self.sizer.Add(wx.StaticText(self.panel, label="Start Page:"), 0, wx.LEFT|wx.TOP, 10) self.sizer.Add(self.start_page_input, 0, wx.EXPAND|wx.ALL, 10) self.sizer.Add(wx.StaticText(self.panel, label="End Page:"), 0, wx.LEFT|wx.TOP, 10) self.sizer.Add(self.end_page_input, 0, wx.EXPAND|wx.ALL, 10) self.sizer.Add(self.extract_button, 0, wx.ALIGN_CENTER|wx.ALL, 10) self.panel.SetSizerAndFit(self.sizer) self.Show() def extract_pages(self, event): file_path = self.file_picker.GetPath() start_page = int(self.start_page_input.GetValue()) end_page = int(self.end_page_input.GetValue()) doc = fitz.open(file_path) output_doc = fitz.open() for page_num in range(start_page-1, end_page): output_doc.insert_pdf(doc, from_page=page_num, to_page=page_num) output_path = file_path.replace(".pdf", "_extracted.pdf") output_doc.save(output_path) output_doc.close() doc.close() wx.MessageBox("Extraction complete!", "Success", wx.OK | wx.ICON_INFORMATION) app = wx.App() PDFExtractor(None, title="PDF Extractor") app.MainLoop() 3. 运行程序将以上代码保存为一个Python脚本文件(例如pdf_extractor.py),然后运行脚本。你将看到一个简单的窗口,其中包含一个文件选择器、开始页码和结束页码的输入框,还有一个"Extract"按钮。 点击文件选择器,选择要打开的PDF文件。在开始页码输入框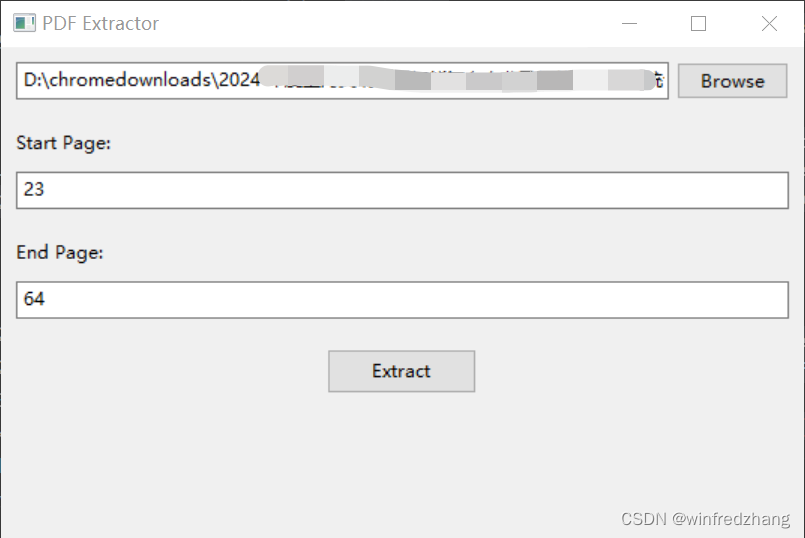 4. 总结
4. 总结
在本篇文章中,我们学习了如何使用Python编程语言和pymupdf、wxPython库来提取PDF文件中指定范围的页面内容。我们创建了一个简单的GUI应用程序,让用户能够选择要打开的PDF文件,并输入开始页码和结束页码。点击"Extract"按钮后,程序将提取指定范围内的页面,并将其保存为新的PDF文件。 这个示例展示了Python在处理PDF文件和创建GUI应用程序方面的强大能力。你可以根据需要对代码进行扩展和定制,以满足更具体的要求。 |
【本文地址】
公司简介
联系我们