| 2021最新微博爬虫 | 您所在的位置:网站首页 › 微博话题发帖格式 › 2021最新微博爬虫 |
2021最新微博爬虫
|
由于课程大作业需要进行一些有关NLP的分析,在网上没有找到特别好使的代码,所以就干脆自己写一个爬虫,可以根据话题名称对其微博内容、评论内容、微博发布者相关信息进行爬取,目前作者测试是没有特别的问题的。 文章讲解中的代码比较散,要进行测试的话建议测试完整代码。 首先针对效果进行展示,作者测试没有把所有数据爬完,但是也爬取了近八千条数据。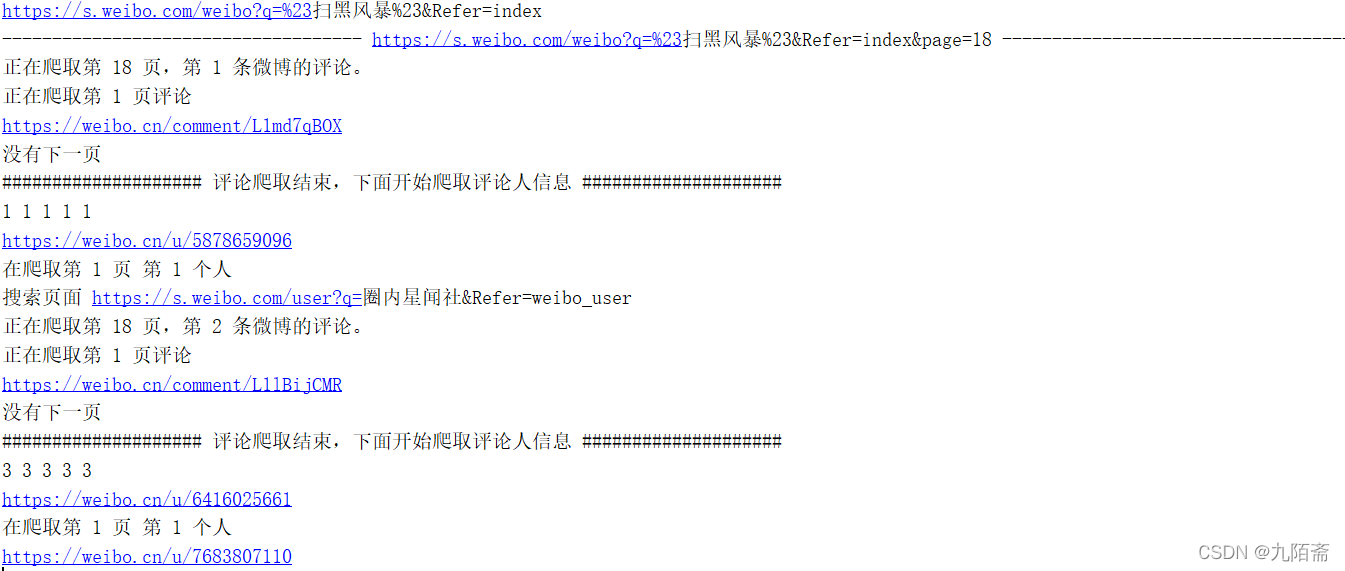 在这里插入图片描述 在这里插入图片描述 在这里插入图片描述 在这里插入图片描述 在这里插入图片描述一、环境准备 在这里插入图片描述一、环境准备这里不多说,用的包是这些,用使用pip install进行安装就行。 代码语言:javascript复制import requests from lxml import etree import csv import re import time import random from html.parser import HTMLParser二、微博数据获取-首先确定抓取微博内容、评论数、点赞数、发布时间、发布者名称等主要字段。选择weibo.com作为主要数据来源。(就是因为搜索功能好使) 知道了爬取目标,进一步就对结构进行分析,需要爬取的内容大致如下: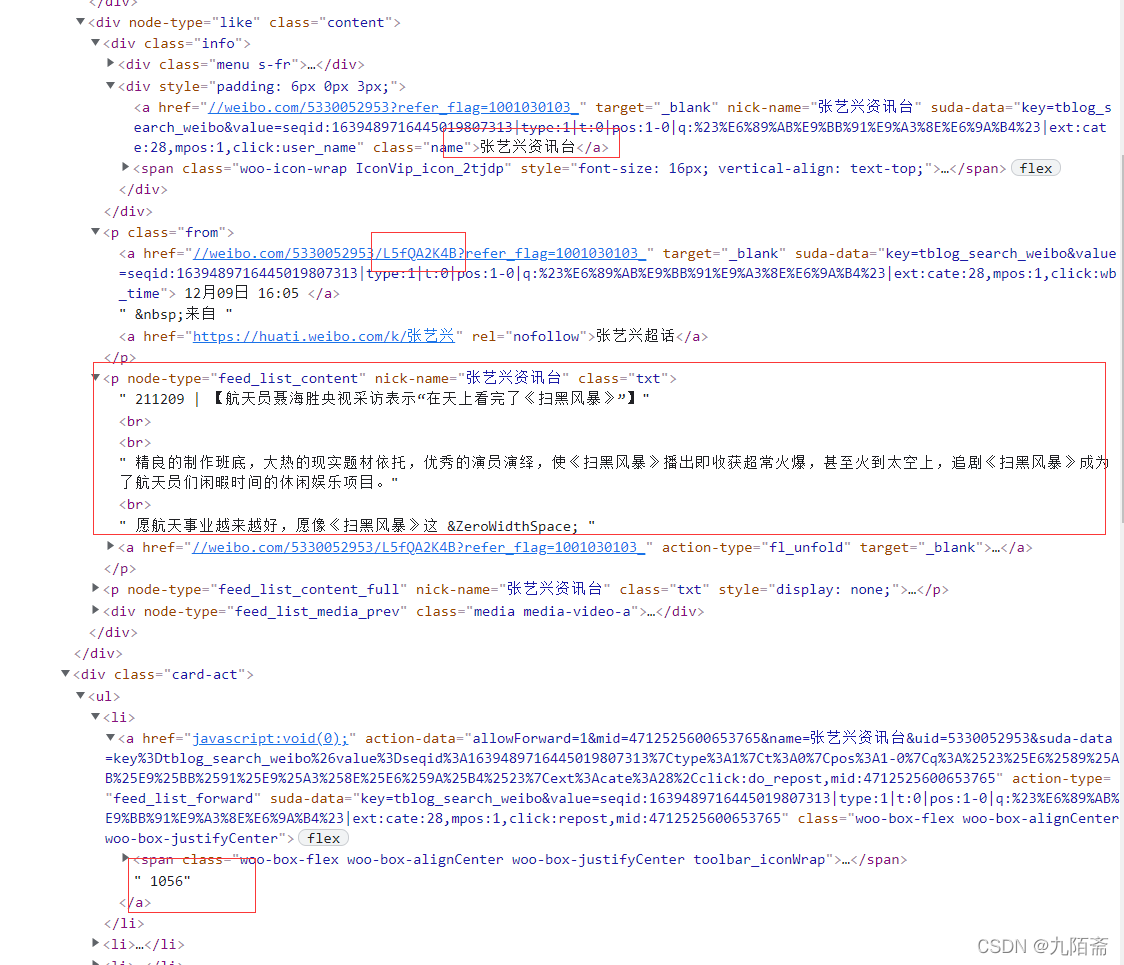 在这里插入图片描述根据翻页查看url的变化,根据观察,url内主要是话题名称与页面数量的变化,所以既定方案如下:代码语言:javascript复制topic = '扫黑风暴'
url = baseUrl.format(topic)代码语言:javascript复制tempUrl = url + '&page=' + str(page)知道了大致结构,便开始提取元素:代码语言:javascript复制 for i in range(1, count + 1):
try:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content_full"]')
contents = contents[0].xpath('string(.)').strip() # 读取该节点下的所有字符串
except:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content"]')
# 如果出错就代表当前这条微博有问题
try:
contents = contents[0].xpath('string(.)').strip()
except:
continue
contents = contents.replace('收起全文d', '')
contents = contents.replace('收起d', '')
contents = contents.split(' 2')[0]
# 发微博的人的名字
name = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/div[1]/div[2]/a')[0].text
# 微博url
weibo_url = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a/@href')[0]
url_str = '.*?com\/\d+\/(.*)\?refer_flag=\d+_'
res = re.findall(url_str, weibo_url)
weibo_url = res[0]
host_url = 'https://weibo.cn/comment/'+weibo_url
# 发微博的时间
timeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a')[0].text.strip()
# 点赞数
likeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[3]/a/button/span[2]')[0].text
hostComment = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[2]/a')[0].text
# 如果点赞数为空,那么代表点赞数为0
if likeA == '赞':
likeA = 0
if hostComment == '评论 ':
hostComment = 0
if hostComment != 0:
print('正在爬取第',page,'页,第',i,'条微博的评论。')
getComment(host_url)
# print(name,weibo_url,contents, timeA,likeA, hostComment)
try:
hosturl,host_sex, host_location, hostcount, hostfollow, hostfans=getpeople(name)
list = ['微博', name, hosturl, host_sex, host_location, hostcount, hostfollow, hostfans,contents, timeA, likeA]
writer.writerow(list)
except:
continue 在这里插入图片描述根据翻页查看url的变化,根据观察,url内主要是话题名称与页面数量的变化,所以既定方案如下:代码语言:javascript复制topic = '扫黑风暴'
url = baseUrl.format(topic)代码语言:javascript复制tempUrl = url + '&page=' + str(page)知道了大致结构,便开始提取元素:代码语言:javascript复制 for i in range(1, count + 1):
try:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content_full"]')
contents = contents[0].xpath('string(.)').strip() # 读取该节点下的所有字符串
except:
contents = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@node-type="feed_list_content"]')
# 如果出错就代表当前这条微博有问题
try:
contents = contents[0].xpath('string(.)').strip()
except:
continue
contents = contents.replace('收起全文d', '')
contents = contents.replace('收起d', '')
contents = contents.split(' 2')[0]
# 发微博的人的名字
name = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/div[1]/div[2]/a')[0].text
# 微博url
weibo_url = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a/@href')[0]
url_str = '.*?com\/\d+\/(.*)\?refer_flag=\d+_'
res = re.findall(url_str, weibo_url)
weibo_url = res[0]
host_url = 'https://weibo.cn/comment/'+weibo_url
# 发微博的时间
timeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a')[0].text.strip()
# 点赞数
likeA = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[3]/a/button/span[2]')[0].text
hostComment = html.xpath('//div[@class="card-wrap"][' + str(i) + ']/div[@class="card"]/div[2]/ul[1]/li[2]/a')[0].text
# 如果点赞数为空,那么代表点赞数为0
if likeA == '赞':
likeA = 0
if hostComment == '评论 ':
hostComment = 0
if hostComment != 0:
print('正在爬取第',page,'页,第',i,'条微博的评论。')
getComment(host_url)
# print(name,weibo_url,contents, timeA,likeA, hostComment)
try:
hosturl,host_sex, host_location, hostcount, hostfollow, hostfans=getpeople(name)
list = ['微博', name, hosturl, host_sex, host_location, hostcount, hostfollow, hostfans,contents, timeA, likeA]
writer.writerow(list)
except:
continue其中,这个微博url特别重要,因为后续爬取其下面的内容需要根据这个url寻找相关内容。 代码语言:javascript复制 weibo_url = html.xpath('//div[@class="card-wrap"][' + str(i) +']/div[@class="card"]/div[1]/div[2]/p[@class="from"]/a/@href')[0] url_str = '.*?com\/\d+\/(.*)\?refer_flag=\d+_' res = re.findall(url_str, weibo_url) weibo_url = res[0] host_url = 'https://weibo.cn/comment/'+weibo_url主要就是需要下面图中的内容  在这里插入图片描述根据页面元素判断是否翻页代码语言:javascript复制 try:
if pageCount == 1:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a')[0].text
print(pageA)
pageCount = pageCount + 1
elif pageCount == 50:
print('没有下一页了')
break
else:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a[2]')[0].text
pageCount = pageCount + 1
print(pageA)
except:
print('没有下一页了')
break结果字段如下:代码语言:javascript复制name,weibo_url,contents, timeA,likeA, hostComment三、微博发布者信息获取 在这里插入图片描述根据页面元素判断是否翻页代码语言:javascript复制 try:
if pageCount == 1:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a')[0].text
print(pageA)
pageCount = pageCount + 1
elif pageCount == 50:
print('没有下一页了')
break
else:
pageA = html.xpath('//*[@id="pl_feedlist_index"]/div[5]/div/a[2]')[0].text
pageCount = pageCount + 1
print(pageA)
except:
print('没有下一页了')
break结果字段如下:代码语言:javascript复制name,weibo_url,contents, timeA,likeA, hostComment三、微博发布者信息获取weibo.com中的信息不够直观,所以在weibo.cn中进行相关数据爬取,页面结构如下:  在这里插入图片描述要进入对应的用户界面就需要获取到相关url,本文的方案是根据上一步获取到的用户名称,在weibo.com中进行相关搜索,我们只需要获取到搜索的第一个人的相关url就行,因为获取到的用户名称都是完整的,所以对应第一个就是我们需要的内容。 在这里插入图片描述要进入对应的用户界面就需要获取到相关url,本文的方案是根据上一步获取到的用户名称,在weibo.com中进行相关搜索,我们只需要获取到搜索的第一个人的相关url就行,因为获取到的用户名称都是完整的,所以对应第一个就是我们需要的内容。
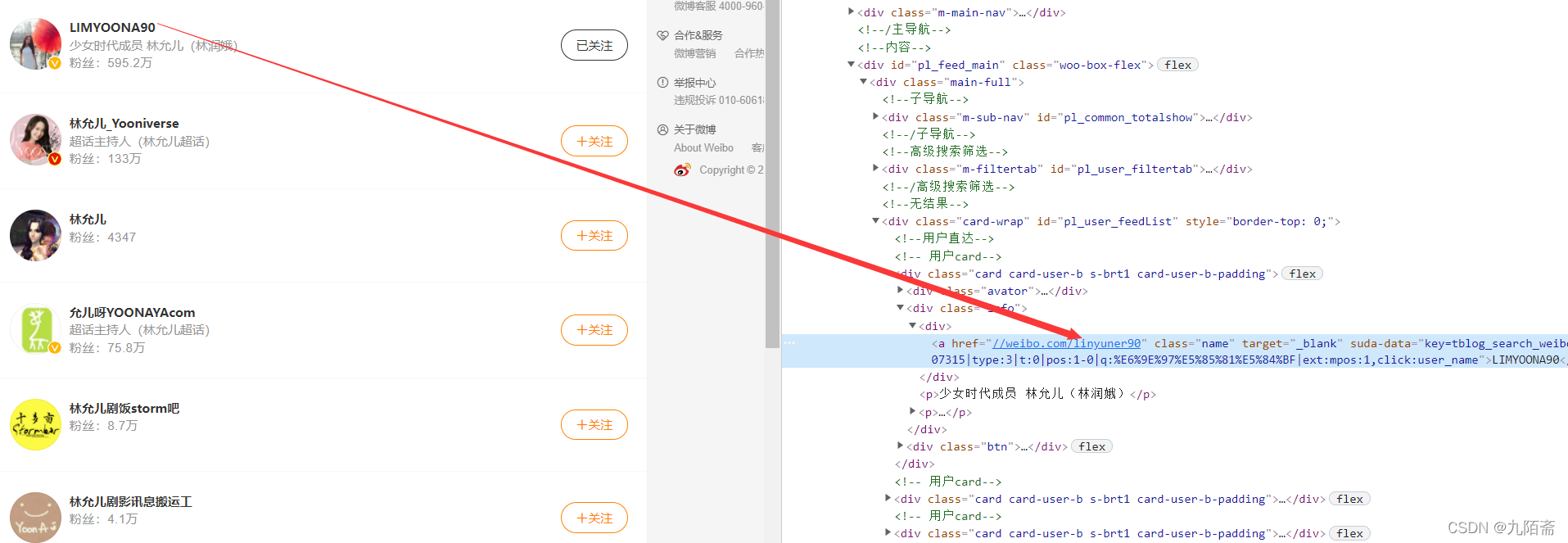 在这里插入图片描述相关代码如下:代码语言:javascript复制 url2 = 'https://s.weibo.com/user?q='
while True:
try:
response = requests.post('https://weibo.cn/search/?pos=search', headers=headers_cn,data={'suser': '找人', 'keyword': name})
tempUrl2 = url2 + str(name)+'&Refer=weibo_user'
print('搜索页面',tempUrl2)
response2 = requests.get(tempUrl2, headers=headers_com_1)
html = etree.HTML(response2.content, parser=etree.HTMLParser(encoding='utf-8'))
# print('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a')
hosturl_01 =html.xpath('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a/@href')[0]
url_str = '.*?com\/(.*)'
res = re.findall(url_str, hosturl_01)
hosturl = 'https://weibo.cn/'+res[0]获取到url后,进入weibo.cn进行相关数据爬取:代码语言:javascript复制 while True:
try:
response = requests.get(hosturl, headers=headers_cn_1)
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
# 微博数
hostcount = html.xpath('/html/body/div[4]/div/span')[0].text
hostcount = re.match('(\S\S\S)(\d+)', hostcount).group(2)
# 关注数
hostfollow = html.xpath('/html/body/div[4]/div/a[1]')[0].text
hostfollow = re.match('(\S\S\S)(\d+)', hostfollow).group(2)
# 粉丝数
hostfans = html.xpath('/html/body/div[4]/div/a[2]')[0].text
hostfans = re.match('(\S\S\S)(\d+)', hostfans).group(2)
# 性别和地点
host_sex_location = html.xpath('/html/body/div[4]/table/tr/td[2]/div/span[1]/text()')
break
except:
print('找人失败')
time.sleep(random.randint(0, 10))
pass
try:
host_sex_locationA = host_sex_location[0].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
except:
host_sex_locationA = host_sex_location[1].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
# print('微博信息',name,hosturl,host_sex,host_location,hostcount,hostfollow,hostfans)
return hosturl,host_sex, host_location, hostcount, hostfollow, hostfans三、评论数据获取 第一步中获取到了微博相关的标识与weibo.cn的url,所以我们根据url进行爬取即可: 在这里插入图片描述相关代码如下:代码语言:javascript复制 url2 = 'https://s.weibo.com/user?q='
while True:
try:
response = requests.post('https://weibo.cn/search/?pos=search', headers=headers_cn,data={'suser': '找人', 'keyword': name})
tempUrl2 = url2 + str(name)+'&Refer=weibo_user'
print('搜索页面',tempUrl2)
response2 = requests.get(tempUrl2, headers=headers_com_1)
html = etree.HTML(response2.content, parser=etree.HTMLParser(encoding='utf-8'))
# print('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a')
hosturl_01 =html.xpath('/html/body/div[1]/div[2]/div/div[2]/div[1]/div[3]/div[1]/div[2]/div/a/@href')[0]
url_str = '.*?com\/(.*)'
res = re.findall(url_str, hosturl_01)
hosturl = 'https://weibo.cn/'+res[0]获取到url后,进入weibo.cn进行相关数据爬取:代码语言:javascript复制 while True:
try:
response = requests.get(hosturl, headers=headers_cn_1)
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
# 微博数
hostcount = html.xpath('/html/body/div[4]/div/span')[0].text
hostcount = re.match('(\S\S\S)(\d+)', hostcount).group(2)
# 关注数
hostfollow = html.xpath('/html/body/div[4]/div/a[1]')[0].text
hostfollow = re.match('(\S\S\S)(\d+)', hostfollow).group(2)
# 粉丝数
hostfans = html.xpath('/html/body/div[4]/div/a[2]')[0].text
hostfans = re.match('(\S\S\S)(\d+)', hostfans).group(2)
# 性别和地点
host_sex_location = html.xpath('/html/body/div[4]/table/tr/td[2]/div/span[1]/text()')
break
except:
print('找人失败')
time.sleep(random.randint(0, 10))
pass
try:
host_sex_locationA = host_sex_location[0].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
except:
host_sex_locationA = host_sex_location[1].split('\xa0')
host_sex_locationA = host_sex_locationA[1].split('/')
host_sex = host_sex_locationA[0]
host_location = host_sex_locationA[1].strip()
# print('微博信息',name,hosturl,host_sex,host_location,hostcount,hostfollow,hostfans)
return hosturl,host_sex, host_location, hostcount, hostfollow, hostfans三、评论数据获取 第一步中获取到了微博相关的标识与weibo.cn的url,所以我们根据url进行爬取即可:
 在这里插入图片描述 分析一下大致的情况 在这里插入图片描述 分析一下大致的情况
 在这里插入图片描述 发现它每一页的评论数量不一样,而且评论所在标签也没有什么唯一标识,所以根据xpath获取有点麻烦,便改用正则表达式进行数据获取。 在这里插入图片描述 发现它每一页的评论数量不一样,而且评论所在标签也没有什么唯一标识,所以根据xpath获取有点麻烦,便改用正则表达式进行数据获取。
 在这里插入图片描述 评论内容部分爬取代码如下:
代码语言:javascript复制 page=0
pageCount=1
count = []#内容
date = []#时间
like_times = []#赞
user_url = []#用户url
user_name = []#用户昵称
while True:
page=page+1
print('正在爬取第',page,'页评论')
if page == 1:
url = hosturl
else:
url = hosturl+'?page='+str(page)
print(url)
try:
response = requests.get(url, headers=headers_cn)
except:
break
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
user_re = ' 在这里插入图片描述 评论内容部分爬取代码如下:
代码语言:javascript复制 page=0
pageCount=1
count = []#内容
date = []#时间
like_times = []#赞
user_url = []#用户url
user_name = []#用户昵称
while True:
page=page+1
print('正在爬取第',page,'页评论')
if page == 1:
url = hosturl
else:
url = hosturl+'?page='+str(page)
print(url)
try:
response = requests.get(url, headers=headers_cn)
except:
break
html = etree.HTML(response.content, parser=etree.HTMLParser(encoding='utf-8'))
user_re = ' |
【本文地址】
公司简介
联系我们