|
上次我们研究了使用公众号后台接口获取任意公众号历史文章的方式。查看点这里 今天我们研究第二种方案,使用微信PC端,访问任意公众号,然后获取历史文章的方式。 本次以“java-tech”公众号为例,手把手教你爬取公众号文章。
1、准备工作
使用Charles抓包工具获取微信访问公众号和文章的接口。Charles下载地址:https://www.charlesproxy.com/download,我们也可以换Fiddler或者Wireshake。 当访问下面公众号时就可以在Charles看到有接口交互。 * 下图中的mp.wixin.qq.com就是微信相关接口。我们从里面找到公众号相关API。 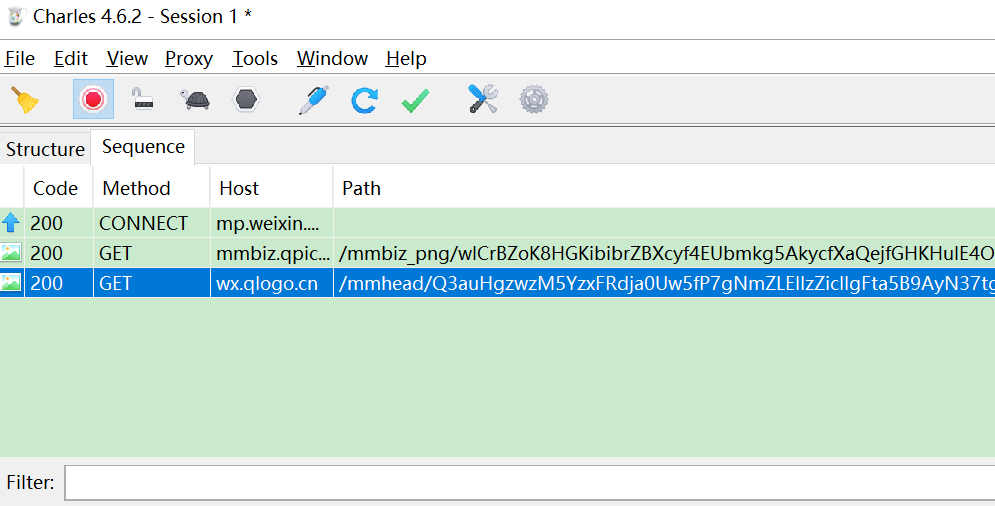 一开始,我们没有在charles配置SSL 代理,所以应该看不到接口内容,都是 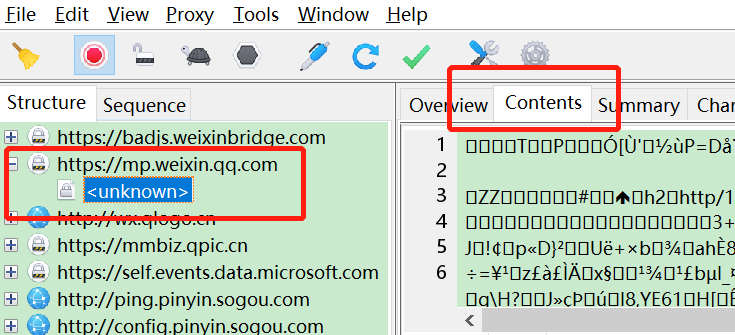 安装charles证书,配置SSL代理,设置:mp.weixin.qq.com:443 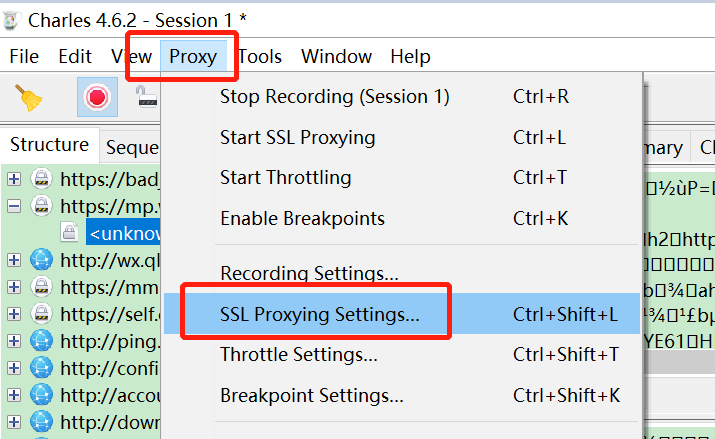 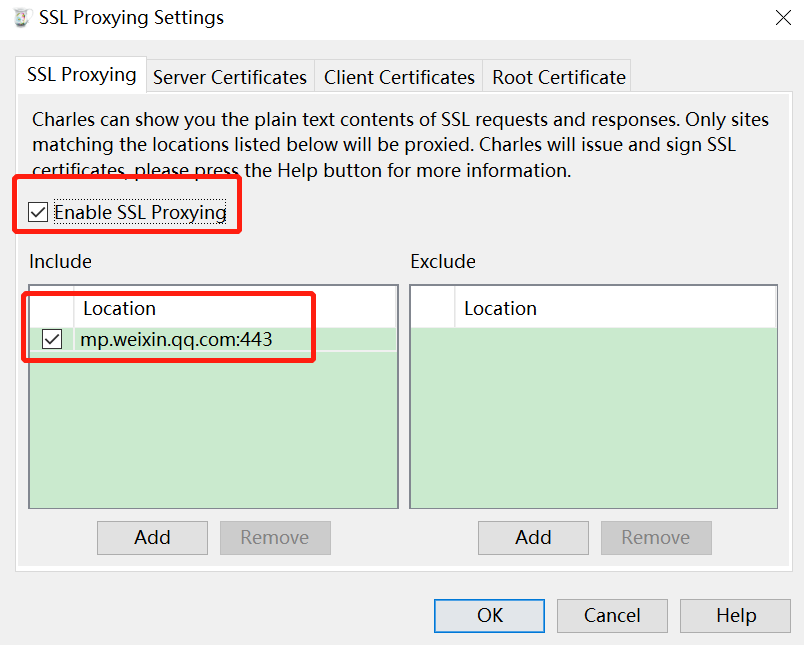 再次访问公众号,应该就能看到API交互内容了。我们在filter里面查看mp.weixin.qq.com的消息。 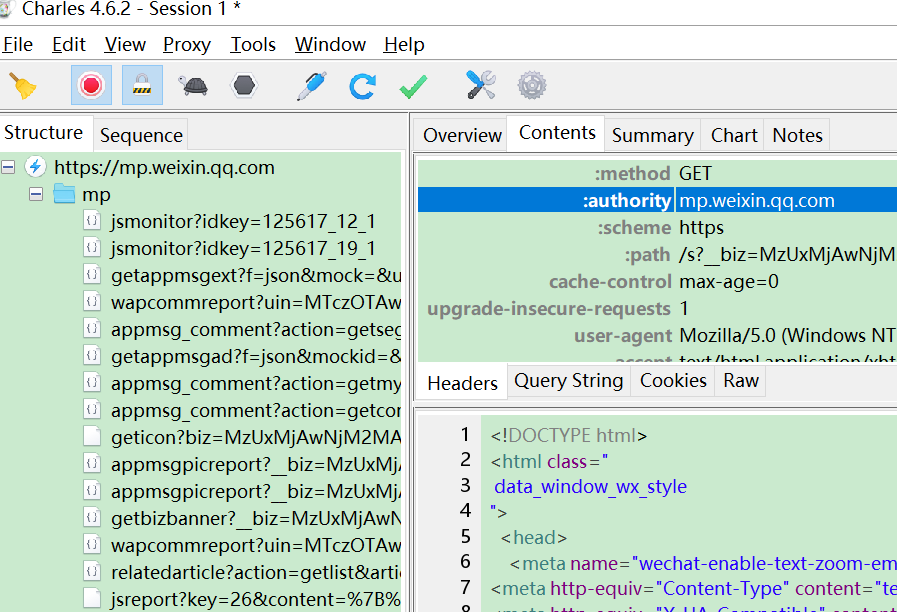 注意: 如果微信PC提示访问链接不安全,请点击继续访问。 注意: 如果微信PC提示访问链接不安全,请点击继续访问。 定位查看历史消息的url:https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=,关键请求字段有__biz=标记某个公众号id,uin=当前用户id,key=包含过期时间的字段,offset是文章起始位置,count=返回数量,其他字段可以忽略。 响应general_msg_list里面有作者,发布时间,文章地址,标题等。 
2、技术实现
提取关键请求信息,比如biz, uin, key, offset, count等。构造请求消息。解析响应,提取一篇文章关键信息,包括日期、标题、题图、链接 。判断是否存在下一页信息。保存信息到excel或者csv。进一步,可以把每篇文章保存成pdf。
3、代码献上
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import csv
import json
import time
from datetime import date
import requests
__art_infos = []
'''
日期:2024年2月23日
公众号ID:java-tech
公众号:Java实用技术手册
声明:本文仅供技术研究,请勿用于非法采集,后果自负。
'''
class ArtInfo(object):
"""
文章信息:包括日期、标题、题图、链接
"""
def __init__(self, pub_date, json_info):
self.pub_date = pub_date
self.title = json_info.get('title')
self.cover = json_info.get('cover')
self.content_url = json_info.get('content_url')
def get_history(offset=0, count=10, continue_flag=True):
biz = '你的biz'
uin = '你的uin'
key = '你的key'
# pass_ticket = 'tS1eMbmDmdNLrZP5/55e6BrLg9TWDuGOFkOXYPIXM8N1SWkZbAEGALDh6kaMQO/GPFT1emxuf j0Rnxxlq iUw=='
url = f'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz={biz}&f=json&offset={offset}&count={count}&is_ok=1&scene=124&uin={uin}&key={key}'
res = requests.get(url)
print(res.json())
js = res.json()
# print(js.get('general_msg_list').get('list'))
general_msg_list_str = js.get('general_msg_list')
msg_list_json = json.loads(general_msg_list_str)
art_list = msg_list_json.get('list')
for art in art_list:
get_art_info(art)
# can_msg_continue 是用来判断是否可以继续获取文章的
if js.get('can_msg_continue') and continue_flag:
offset = (offset+1) * count
print(f'===继续获取下一页,offset={offset}')
time.sleep(10) # 防封
get_history(offset, 10, False) # 测试一次就不继续
else:
print('结束,没有更多文章。')
def get_art_info(json_art_info):
comm_msg_info = json_art_info.get('comm_msg_info')
# 获取发文时间
datetime_ms = comm_msg_info.get('datetime')
pub_datetime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(datetime_ms))
print('pub_datetime=', pub_datetime)
pub_date = str(date.fromtimestamp(datetime_ms))
info = json_art_info.get('app_msg_ext_info')
if info:
# 头条消息
art_info0 = ArtInfo(pub_date, info)
# art_info0.parse(info)
print('头条:', art_info0.__dict__)
__art_infos.append(art_info0)
# 次消息
multi_item_list = info.get('multi_app_msg_item_list')
if multi_item_list:
for item in multi_item_list:
art_info = ArtInfo(pub_date, item)
print('次头条:', art_info.__dict__)
__art_infos.append(art_info)
# break
def save_art_info(art_infos):
with open('art_infos.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['pub_date', 'title', 'cover', 'content_url'])
for info in art_infos:
writer.writerow([info.pub_date, info.title, info.cover, info.content_url])
def main():
get_history()
save_art_info(__art_infos)
if __name__ == '__main__':
main()
4、爬取结果

5、常见问题
本文使用的微信PC版本为V2.6.4,如果你用的是最新的V3.x,你可能看不到/mp/profile_ext链接,虽然新版本链接被屏蔽了,但是这个接口依然可以调通。。。微信官网没有V2.6.4了,可以在本公众号 java-tech 回复 wx264 下载。charles调测时需要打开电脑代理。py调测报错:ssl.SSLError: [SSL: WRONG_VERSION_NUMBER] wrong version number,请关闭本地代理。
声明:本文仅供技术研究,请勿用于非法采集。
|