|
python爬虫系列之腾讯文档Excel数据
一、简介二、实现步骤1. 数据准备2. 获取当前用户nowUserIndex3.创建导出任务4. 检查数据准备进度,并下载
三、完整代码四、效果演示
一、简介
本文讲述使用python下载腾讯文档中的Excel数据。
思路
腾讯文档导出流程如下
Created with Raphaël 2.3.0
点击导出
腾讯文档准备数据
数据准备完成?
出现下载excel文件的url
yes
no
使用抓包工具获取导出接口,检测数据是否准备完成接口、下载excel接口,使用requests进行调用,即可完成下载
二、实现步骤
1. 数据准备
提供腾讯文档中excel文档地址,以便进行下载,首先需要进行登陆,获取excel文档地址 document_url = https://docs.qq.com/sheet/DSnhHWFRraGRzSXhC 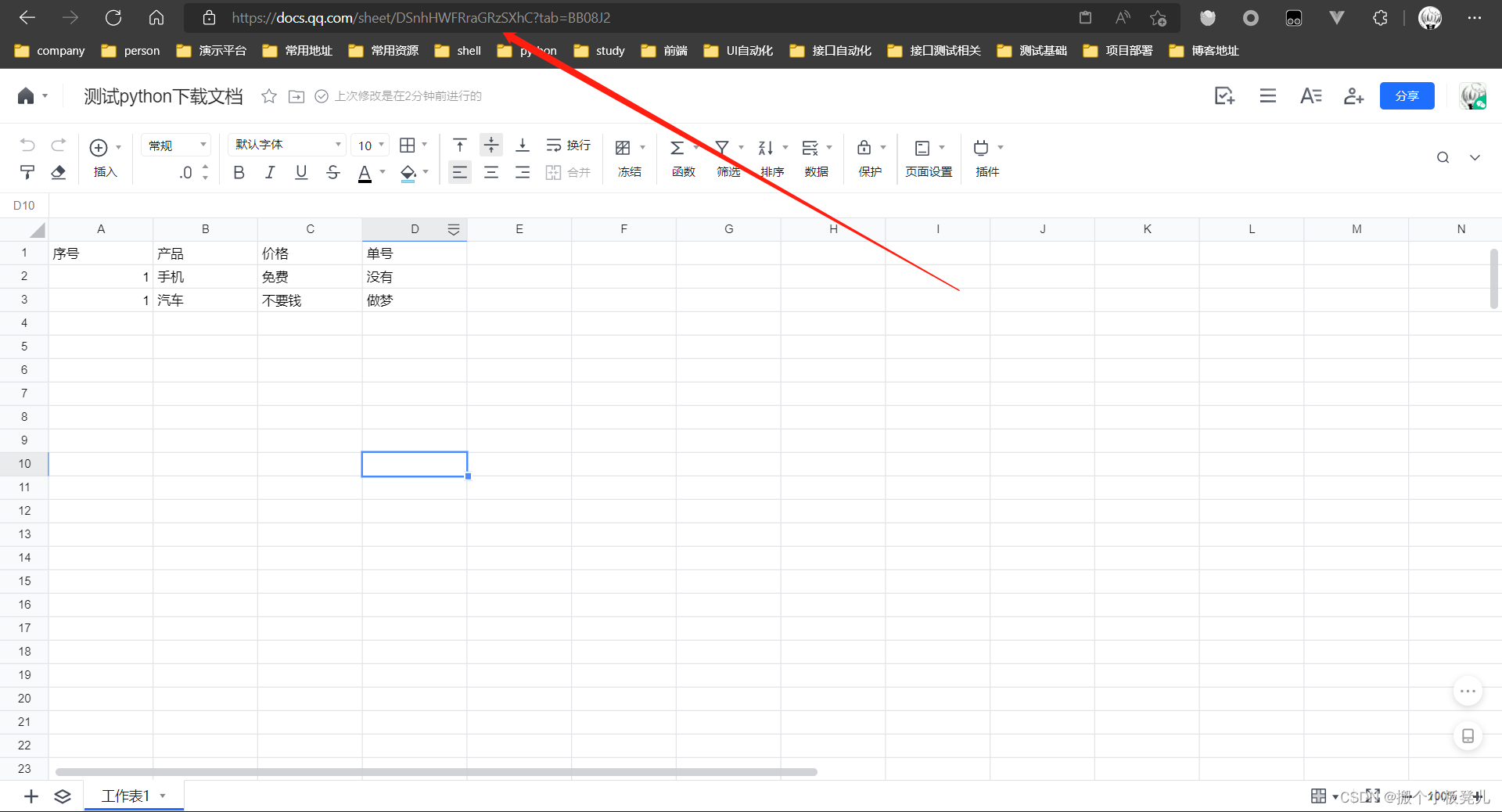 获取文档localPadId,每份文档唯一。打开浏览器控制台,刷新页面,filter中输入doc_info,找到该请求的localPadId local_pad_id = 300000000$TfQWCVvRALvN 获取文档localPadId,每份文档唯一。打开浏览器控制台,刷新页面,filter中输入doc_info,找到该请求的localPadId local_pad_id = 300000000$TfQWCVvRALvN 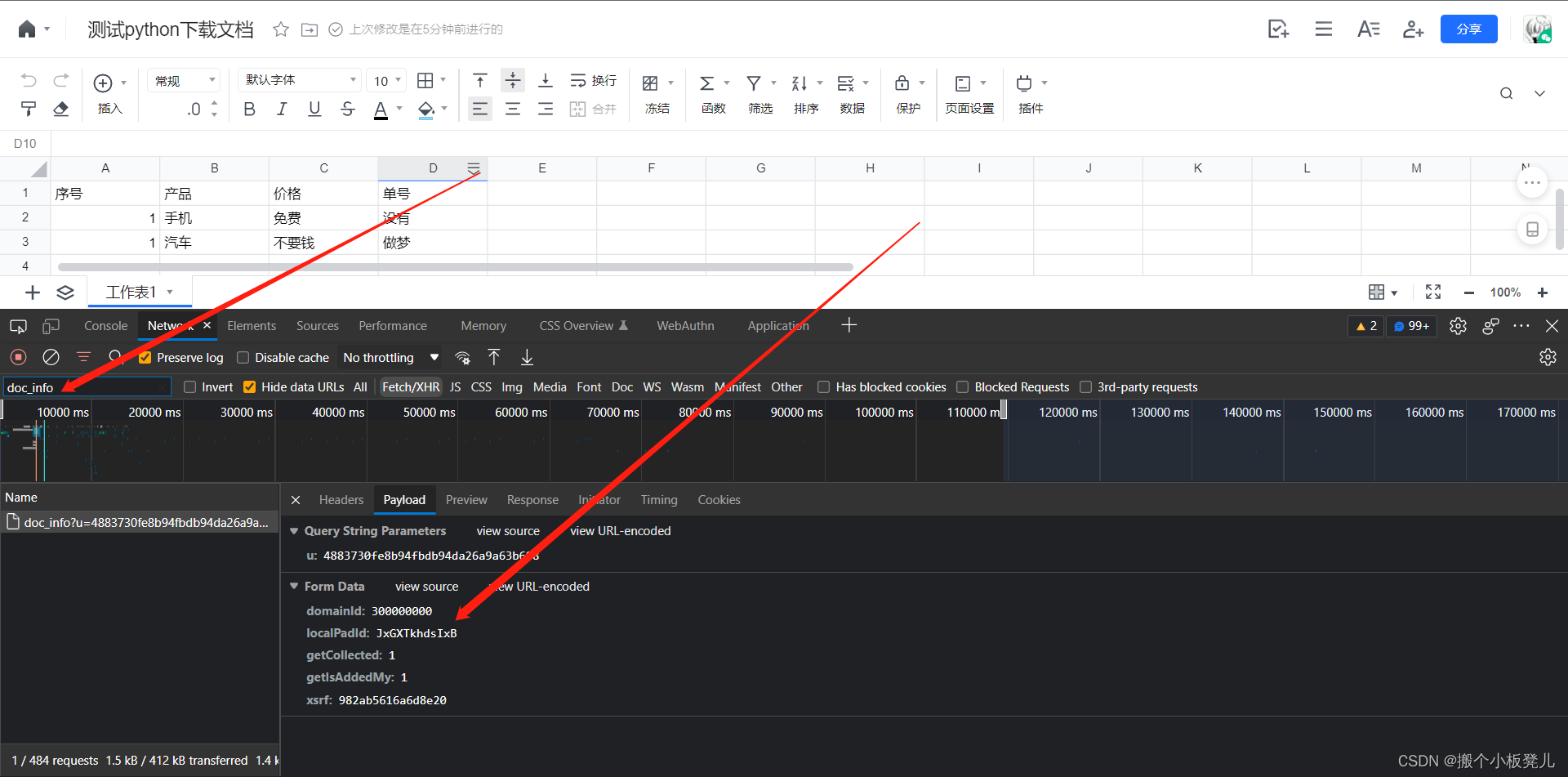 cookie值获取,右键复制即可 cookie_value = ******** cookie值获取,右键复制即可 cookie_value = ******** 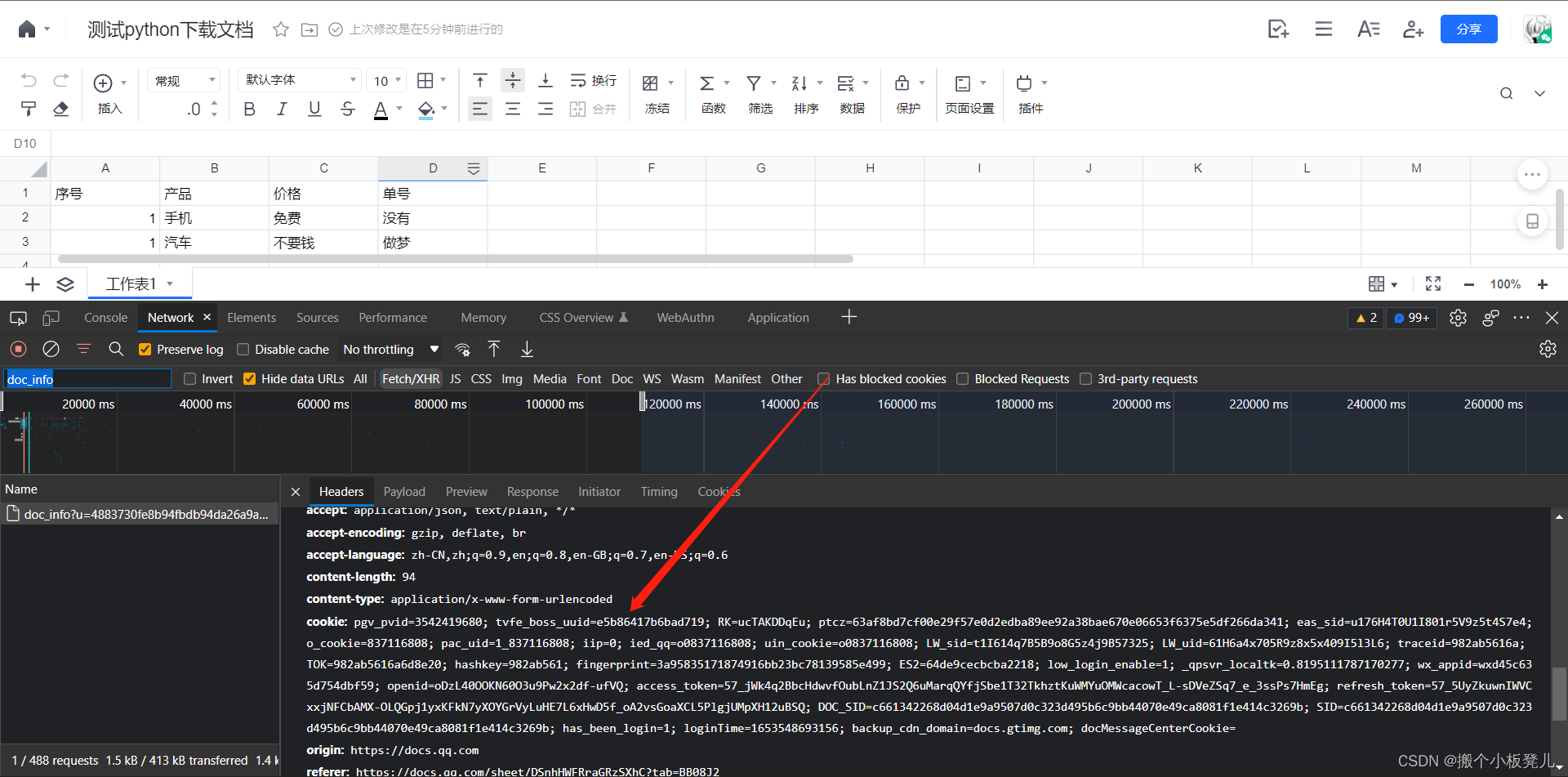 2. 获取当前用户nowUserIndex
2. 获取当前用户nowUserIndex
用户nowUserIndex字段为后续下载excel文件接口的u字段,这里通过调用接口document_url获取
def get_now_user_index(self):
"""
# 获取当前用户信息,供创建下载任务使用
:return:
# nowUserIndex = '4883730fe8b94fbdb94da26a9a63b688'
# uid = '144115225804776585'
# utype = 'wx'
"""
response_body = requests.get(url=self.document_url, headers=self.headers, verify=False)
parser = BeautifulSoup(response_body.content, 'html.parser')
global_multi_user_list = re.findall(re.compile('window.global_multi_user=(.*?);'), str(parser))
if global_multi_user_list:
user_dict = json.loads(global_multi_user_list[0])
print(user_dict)
return user_dict['nowUserIndex']
return 'cookie过期,请重新输入'
3.创建导出任务
创建导出任务的接口通过点击导出按钮获取,其中u字段值即为nowUserIndex字段,创建导出任务接口会返回一个operationId字段,是检测数据准备进度的入参。 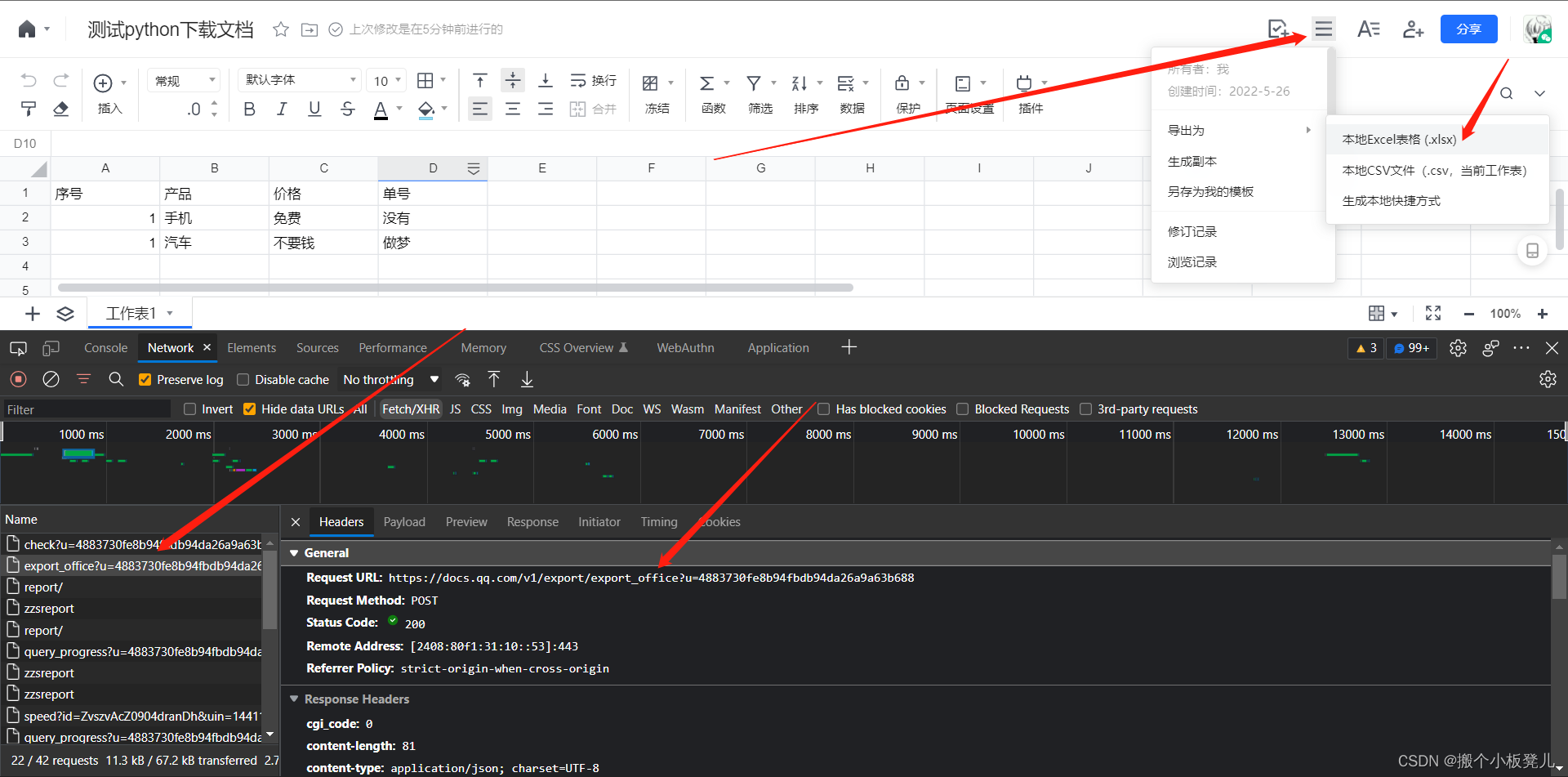 export_excel_url = f'https://docs.qq.com/v1/export/export_office?u={now_user_index}' export_excel_url = f'https://docs.qq.com/v1/export/export_office?u={now_user_index}'
def export_excel_task(self, export_excel_url):
"""
导出excel文件任务,供查询文件数据准备进度
:return:
"""
body = {
'docId': self.localPadId, 'version': '2'
}
res = requests.post(url=export_excel_url,
headers=self.headers, data=body, verify=False)
operation_id = res.json()['operationId']
return operation_id
4. 检查数据准备进度,并下载
查询数据准备进度的接口为 check_progress_url = f'https://docs.qq.com/v1/export/query_progress?u={now_user_index}&operationId={operation_id}',在点击导出excel时会出现该接口信息,频繁调用该接口,当progress进度为100时,该接口返回值会出现file_url信息。然后requests调用file_url,就可以拿到文件流,写到excel文件中即可完成下载。 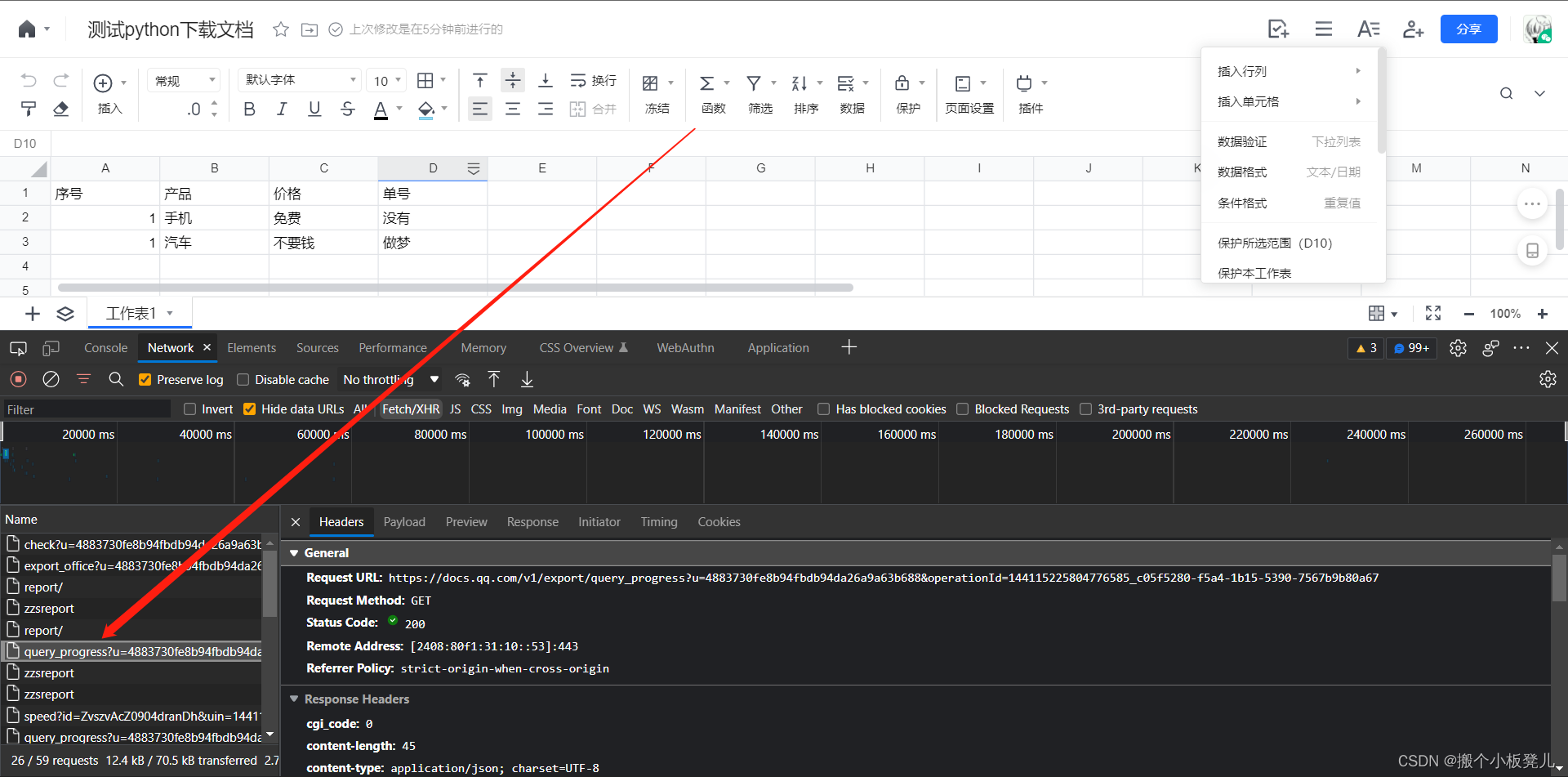
def download_excel(self, check_progress_url, file_name):
"""
下载excel文件
:return:
"""
# 拿到下载excel文件的url
start_time = time.time()
file_url = ''
while True:
res = requests.get(url=check_progress_url, headers=self.headers, verify=False)
progress = res.json()['progress']
if progress == 100:
file_url = res.json()['file_url']
break
elif time.time() - start_time > 30:
print("数据准备超时,请排查")
break
if file_url:
self.headers['content-type'] = 'application/octet-stream'
res = requests.get(url=file_url, headers=self.headers, verify=False)
with open(file_name, 'wb') as f:
f.write(res.content)
print('下载成功,文件名: ' + file_name)
else:
print("下载文件地址获取失败, 下载excel文件不成功")
三、完整代码
# -*- coding: UTF-8 -*-
"""
@Project :small-tools
@File :tengxun.py
@Author :silen
@Time :2022/5/26 15:42
@Description :
"""
import json
import os
import re
import time
from datetime import datetime
from time import sleep
import click
import pandas as pd
import requests
from bs4 import BeautifulSoup
class TengXunDocument():
def __init__(self, document_url, local_pad_id, cookie_value):
# excel文档地址
self.document_url = document_url
# 此值每一份腾讯文档有一个,需要手动获取
self.localPadId = local_pad_id
self.headers = {
'content-type': 'application/x-www-form-urlencoded',
'Cookie': cookie_value
}
def get_now_user_index(self):
"""
# 获取当前用户信息,供创建下载任务使用
:return:
# nowUserIndex = '4883730fe8b94fbdb94da26a9a63b688'
# uid = '144115225804776585'
# utype = 'wx'
"""
response_body = requests.get(url=self.document_url, headers=self.headers, verify=False)
parser = BeautifulSoup(response_body.content, 'html.parser')
global_multi_user_list = re.findall(re.compile('window.global_multi_user=(.*?);'), str(parser))
if global_multi_user_list:
user_dict = json.loads(global_multi_user_list[0])
print(user_dict)
return user_dict['nowUserIndex']
return 'cookie过期,请重新输入'
def export_excel_task(self, export_excel_url):
"""
导出excel文件任务,供查询文件数据准备进度
:return:
"""
body = {
'docId': self.localPadId, 'version': '2'
}
res = requests.post(url=export_excel_url,
headers=self.headers, data=body, verify=False)
operation_id = res.json()['operationId']
return operation_id
def download_excel(self, check_progress_url, file_name):
"""
下载excel文件
:return:
"""
# 拿到下载excel文件的url
start_time = time.time()
file_url = ''
while True:
res = requests.get(url=check_progress_url, headers=self.headers, verify=False)
progress = res.json()['progress']
if progress == 100:
file_url = res.json()['file_url']
break
elif time.time() - start_time > 30:
print("数据准备超时,请排查")
break
if file_url:
self.headers['content-type'] = 'application/octet-stream'
res = requests.get(url=file_url, headers=self.headers, verify=False)
with open(file_name, 'wb') as f:
f.write(res.content)
print('下载成功,文件名: ' + file_name)
else:
print("下载文件地址获取失败, 下载excel文件不成功")
if __name__ == '__main__':
# excel文档地址
document_url = 'https://docs.qq.com/sheet/DSnhHWFRraGRzSXhC'
# 此值每一份腾讯文档有一个,需要手动获取
local_pad_id = '300000000$JxGXTkhdsIxB'
# 打开腾讯文档后,从抓到的接口中获取cookie信息
cookie_value = '****'
tx = TengXunDocument(document_url, local_pad_id, cookie_value)
now_user_index = tx.get_now_user_index()
# 导出文件任务url
export_excel_url = f'https://docs.qq.com/v1/export/export_office?u={now_user_index}'
# 获取导出任务的操作id
operation_id = tx.export_excel_task(export_excel_url)
check_progress_url = f'https://docs.qq.com/v1/export/query_progress?u={now_user_index}&operationId={operation_id}'
current_datetime = datetime.strftime(datetime.now(), '%Y_%m_%d_%H_%M_%S')
file_name = f'{current_datetime}.xlsx'
tx.download_excel(check_progress_url, file_name)
四、效果演示
成功下载的文档如下所示 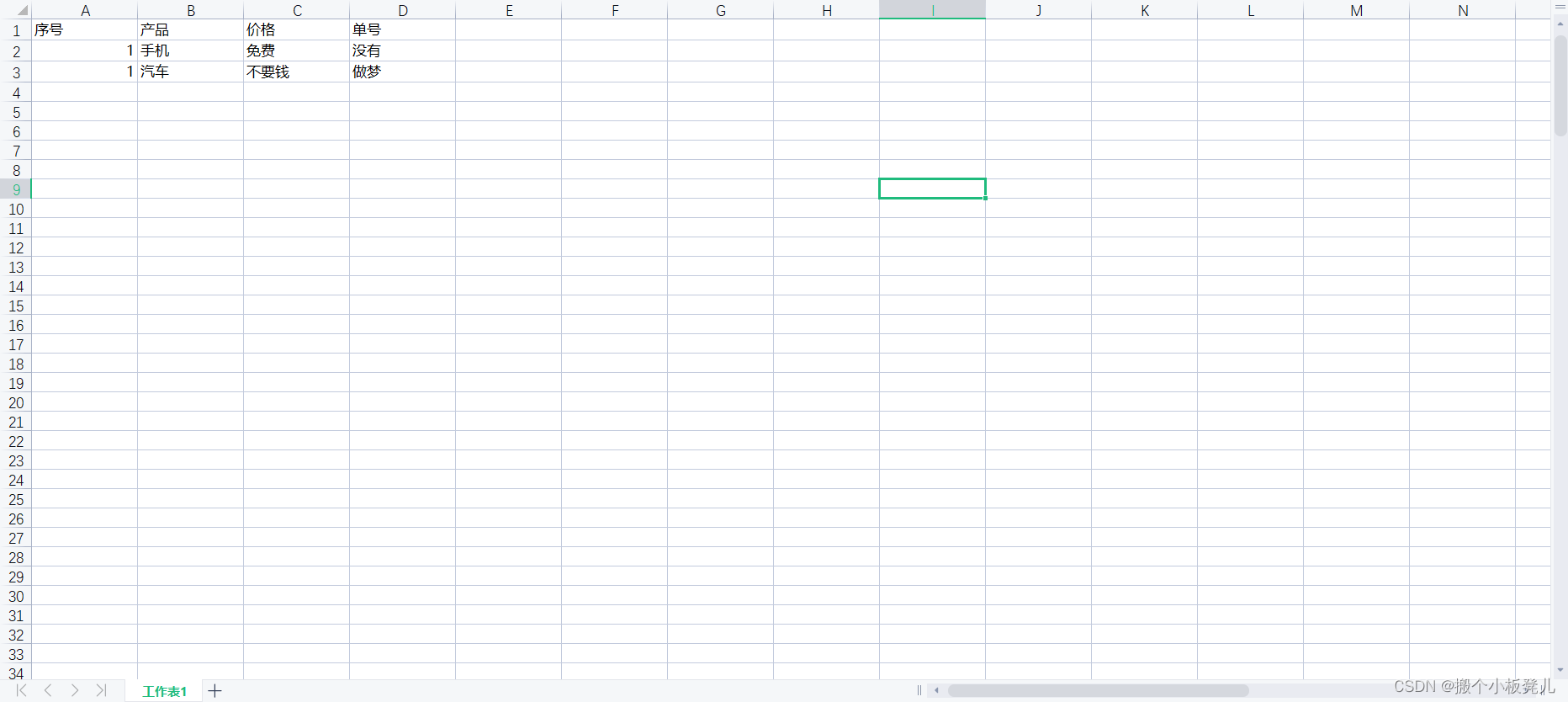
如果我的文章对你有帮助,感谢你点的关注~
|