|
最近刚学完FP-tree,写个简单的实现巩固一下。其中原始项目集只能以字符串的形式读入,输出结果为强规则,中间过程的条件模式基以及频繁模式都可以输出。
知识点:
1.理清楚FP-tree算法流程(这个是必须的)。
2.递归求string的所有子序列。
3.树的灵活运用。(多叉树,father指针,特定结点链表指针)
优点:
实现的还是很详细的,每个小阶段的结果都可以输出。另外使用的方法都是比较简单易懂的。
缺点:
代码技巧性不足导致效率较低。
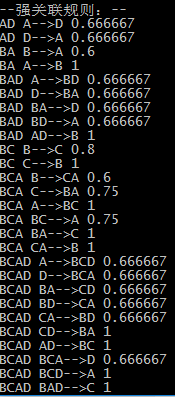
运行截图:


#include
using namespace std;
struct cmp1{
bool operator()(const pair a,const pair b){
if(a.second == b.second)return a.first > b.first;
return a.second < b.second;
}
};
priority_queueQt;//用于数据内部排序
stack St,S;//存储预处理前数据。预处理后数据
mapM,hd;//用于统计数据出现次数。记录头指针的编号。
mapFP;//用于存频繁模式
//-----------------------------------树相关结构及函数定义----------------------------------------
typedef struct Node* node;
node head[10005];
struct Node {//结点定义
char key;
int value;
node next,father;
vector child;
};
node CreateNode(char _key,char _value){//创建结点
node p = new Node;
p->key = _key;
p->value = _value;
p->father = p->next = NULL;
return p;
}
node getNode(char _key,char _value,node _father){//得到处理后的结点
node p = CreateNode(_key,_value);
p->father = _father;
p->next = head[hd[_key]];
head[hd[_key]] = p;
return p;
}
void SolveDate(string s,node rt){//将数据转换到树上
node p = rt;
for(int i=0 ; ichild).empty()){
(p->child).push_back(getNode(s[i],1,p));
p = (p->child).back();
}
else {
vector::iterator it;
for(it=(p->child).begin() ; it!=(p->child).end() ; ++it){
if((*it)->key == s[i]){
(*it)->value++;
p = *it;
break;
}
}
if(it == (p->child).end()){
(p->child).push_back(getNode(s[i],1,p));
p = (p->child).back();
}
}
}
}
int Combination2(string s,int temp,int num,string a,string b,int ZCD,double MC){//求关联规则时求string的所有子序列
if(s.length()-temp < num)return 0;
if(temp == s.length()){//这里不能num==0就停,因为b串未全。
if(FP.find(a) == FP.end() || FP[a] < ZCD)return 0;
if(FP.find(b) == FP.end() || FP[b] < ZCD)return 0;
double de = 1.0*FP[s]/FP[a];
if(de >= MC){
cout |