| 深度优先搜索之记忆化dfs | 您所在的位置:网站首页 › 广度优先搜索是一个递归过程对吗 › 深度优先搜索之记忆化dfs |
深度优先搜索之记忆化dfs
|
文章目录
前言朴素dfs的求解思路记忆化dfs的求解思路将整数按权重排序题目描述解题思路朴素dfs记忆化dfs小结
矩阵中的最长递增路径题目描述解题思路朴素dfs记忆化dfs小结
统计所有可行路径题目描述解题思路朴素dfs记忆化dfs小结
学生出勤记录 II题目描述朴素dfs记忆化dfs小结
“马”在棋盘上的概率题目描述记忆化dfs
骑士拨号器题目描述记忆化dfs
记忆化dfs与棋结语
前言
前不久,我写一篇bfs的进阶版双向bfs:广度优先搜索之双向bfs 这篇文章主要是讲述对于一些特定的bfs问题,可以使用两头齐搜的双向bfs方式来解决其搜索空间爆炸的问题。 同样,对于普通的dfs而言,它的时间复杂度是指数级别,这个时间复杂度是非常恐怖的,很容易就出现最经典的超出时间限制。正是因为如此,所以往往在使用dfs的时候回出现一些剪枝手段,来大幅减少搜索的时间复杂度,其中最有效的就莫过于记忆化dfs。 记忆化dfs,顾名思义就是使用缓存来记录搜索的数据,当再次搜索到相同的状态时直接使用缓存数据即可,从而能够将指数级别的时间复杂度降低到幂数级别的时间复杂度,这可是完全降低了一个档次啊。 同样,接下来我分别详细讲述朴素dfs的实现思路以及记忆化dfs的求解思路,然后结合真题进行实操。 朴素dfs的求解思路朴素dfs实质上就是递归,在递归的过程中获取我们想要的数据。 记忆化dfs的求解思路记忆化dfs的核心是在朴素dfs的基础上新增了一个记录递归中间状态和数据的容器,当再次递归到相同的状态时,直接使用容器的缓存结果即可,从而实现剪枝的效果,这也是一种空间换时间的策略。 而记忆化dfs的时间复杂度之所以降低到幂数级别,是因为由于缓存容器的存在,搜索的空间由原来的递归栈变成了容器的大小,简单来说,当容器填满时dfs将不再进行所有的数据都可以从容器中直接获取,所有其时间复杂度变相的变成填满容器的幂数级别。 而记忆化dfs的难点也正是在于其容器的定义,并且在很多情况下,记忆化dfs都能够转变为动态规划,而缓存容器也就是动态规划的dp数组,只不过记忆化dfs填充容器是通过“暴力”搜索来实现,而动态规划填充dp是通过状态转移方程来实现。 下面题目我都只使用dfs进行实现,若大家有兴趣,可以自行尝试将记忆化dfs改造成动态规划。 将整数按权重排序 题目描述
一种很直接的想法:获取到lo到hi之间所有位置的权重,然后按照位置和权重进行排序,最后返回第k个位置是的数据即可。 思路不难,直接上代码: function getKth(lo: number, hi: number, k: number): number { const dfs = (num: number) => { // ... } const res: number[][] = []; for (let i = lo; i { if (a[1] !== b[1]) { return a[1] - b[1]; } return a[0] - b[0]; }); return res[k - 1][0]; };接下来就是dfs的实现。 朴素dfs const dfs = (num: number) => { if (num === 1) { return 0; } return num % 2 === 0 ? dfs(num / 2) + 1 : dfs(3 * num + 1) + 1; }根据条件很容易写出上述朴素版的dfs,但是显然,它一定会超出时间限制。因为我们外层有for循环在计算每一个数字的权重,那么这其中必然会重复计算很多相同的状态,所以此时记忆化dfs登场。 记忆化dfs const cache = new Array(1000010).fill(0); const dfs = (num: number) => { if (num === 1) { return 0; } // 直接获取缓存的数据 if (cache[num] !== 0) { return cache[num]; } // 默认当前查找需要一步 let res = 1; res += num % 2 === 0 ? dfs(num / 2) : dfs(3 * num + 1); // 保存当前值的计算结果 cache[num] = res; return res; }这里,我们使用cache来记录递归中的重复状态,cache[num]代表数字为num时的权重大小。 小结一维cache热身结束,接下来我们来试试二维cache。 矩阵中的最长递增路径 题目描述
首先,大家不要被这个困难难度所吓倒,其实它并没有想象中的那么难。 我们来梳理一下解题思路:遍历矩阵的每一个点,并获取每一个点的最大递增路径长度,最后返回最大的那个长度即可。 function longestIncreasingPath(matrix: number[][]): number { const n = matrix.length; const m = matrix[0].length; const dfs = (i: number, j: number) => { //... } let max = 0; for (let i = 0; i < n; i++) { for (let j = 0; j < m; j++) { max = Math.max(dfs(i, j), max); } } return max; }; 朴素dfs const dfs = (i: number, j: number) => { let max = 1; for (let dir of dirs) { const [x, y] = dir; const newI = i + x; const newJ = j + y; if (newI >= 0 && newI < n && newJ >= 0 && newJ < m && matrix[newI][newJ] > matrix[i][j]) { max = Math.max(max, dfs(newI, newJ) + 1); } } return max; }细心的朋友应该有发现这个dfs和一般的递归不太一样,貌似没有递归的终止条件即开头return语句。 其实它是有的,因为它在进行下一次递归之前进行了剪枝,不满足条件的状态不进行下一层递归。 它也可以改造成传统的首部剪枝的递归形式,只不过在本题上如果使用那种方式,dfs还需要额外维护一个参数:上一个位置的值大小。 同样,我们还是需要记忆化dfs来维护重复计算的状态。 记忆化dfs有了上题的经验,那么这道题的cache应该是什么呢?没错,首先它肯定是一个二维数组,并且cache[i][j]表示矩阵中坐标为i,j点的最长路径长度。 直接上代码: const cache = new Array(n).fill(0).map(() => new Array(m).fill(0)); const dirs = [[0, 1], [1, 0], [0, -1], [-1, 0]]; const dfs = (i: number, j: number) => { if (cache[i][j] !== 0) { return cache[i][j]; } let max = 1; for (let dir of dirs) { const [x, y] = dir; const newI = i + x; const newJ = j + y; if (newI >= 0 && newI < n && newJ >= 0 && newJ < m && matrix[newI][newJ] > matrix[i][j]) { max = Math.max(max, dfs(newI, newJ) + 1); } } cache[i][j] = max; return max; } 小结是不是突然间感觉困难题也不过如此,是不是感觉不得劲,那么接下来再来一道二维cache的困难题,只不过这题的cache就不是那么容易构造了。 统计所有可行路径 题目描述
一个比较直接的想法是:从start开始进行dfs,在满足剩余fuel大于0的情况下统计出所有能到达finish的总数。 function countRoutes(locations: number[], start: number, finish: number, fuel: number): number { const MOD = 1000000007; const n = locations.length; const dfs = (res: number, cur: number) => { //... } return dfs(fuel, start); }; 朴素dfs const dfs = (res: number, cur: number) => { if (res < 0) { return 0; } let sum = 0; // 由于finish也可以被执行多次,所以这里不能return if (cur === finish) { sum++; } for (let i = 0; i < n; i++) { if (i === cur) { continue; } sum += dfs(res - Math.abs(locations[i] - locations[cur]), i); sum %= MOD; } return sum; }每次递归时都遍历locations,把所有的可能性求和。同样,它也会存在大量重复递归的问题。 记忆化dfs根据前面的经验,我们不难知道很多sum是重复的,我们需要使用cache来保存sum,那么sum究竟是什么呢?sum保存的是cache[cur][res],即在cur位置剩余res油量时的总情况数。 const cache = new Array(n).fill(0).map(() => new Array(fuel + 1).fill(-1)); const dfs = (res: number, cur: number) => { if (res < 0) { return 0; } if (cache[cur][res] !== -1) { return cache[cur][res]; } let sum = 0; if (cur === finish) { sum++; } for (let i = 0; i < n; i++) { if (i === cur) { continue; } sum += dfs(res - Math.abs(locations[i] - locations[cur]), i); sum %= MOD; } cache[cur][res] = sum; return sum; } 小结是不是感觉有点上头了,那么接下来试试三维的cache吧。 后面的题目我就不给出解题思路的,具体可参看代码注释。 学生出勤记录 II 题目描述
还有两道虽然是中等题但是难度不亚于困难题的三维cache,这道题我就直接给出记忆化dfs代码仅做参考。 “马”在棋盘上的概率 题目描述
能跟到这里,相信大家应该都已经很熟悉记忆化dfs的模板套路了。一般情况化其实朴素dfs已经足够了,那么记忆化dfs究竟是否有其实际的作用呢?这不在棋类算法中,记忆化dfs就充当着不可或缺的重要作用价值。 对于设计棋类算法,我们知道其核心算法是采用Alpha Beta的极大化极小值搜索,那么记忆化dfs的作用在哪呢? 首先,我们知道记忆化dfs的原理在于其使用缓存的方式作用于dfs,直接从缓存中获取结果从而达到剪枝效果。那么在棋类算法中也是同样的道理,以中国象棋为例,不知道大家有发现电脑在开局时的计算速度会非常快,那是因为它直接使用了缓存中的开局库。这些都已经是认证过的最优解可以直接使用。通过残局也是同样的道理。还有一个细节,就是当电脑就算出绝杀棋的时候也会计算得特别快,因为当计算出杀棋时,把其中所以的情形状态路径都放置到缓存容器,然后后续的支招直接从缓存容器中取出即可。 通俗点说,记忆化dfs就是背谱,查谱的速度那肯定比算棋的速度要快得多。 再扩展点来说,以五子棋为例,不管是无禁手还是有禁手,其实执黑都是必胜的,理论上来说,只要把所有的必胜步骤都记录到缓存容器中,那么电脑下棋无需再思考,只用根据棋局直接从缓存中读取下一步必胜方案即可。但是事实上这是不可行的,暂不说算是否有指数级别的缓存空间,哪怕其总的时间复杂度也没有任何变化,原因很简单,把所有指数级别的可能性扁平化放到一个数组里,那么遍历这个数组和前者的递归查找是一模一样的。 结语到此,本篇有关记忆化dfs的讲述已临近尾声,细细品味,这些高级算法还是挺有意思的,如果大家有疑问,欢迎评论区留言或者私信我。下期再会。 |
 题目描述不是重点,所以我直接用截图,想看原题的可以直接点链接跳转过去。 原题地址: 将整数按权重排序
题目描述不是重点,所以我直接用截图,想看原题的可以直接点链接跳转过去。 原题地址: 将整数按权重排序 原题地址:矩阵中的最长递增路径
原题地址:矩阵中的最长递增路径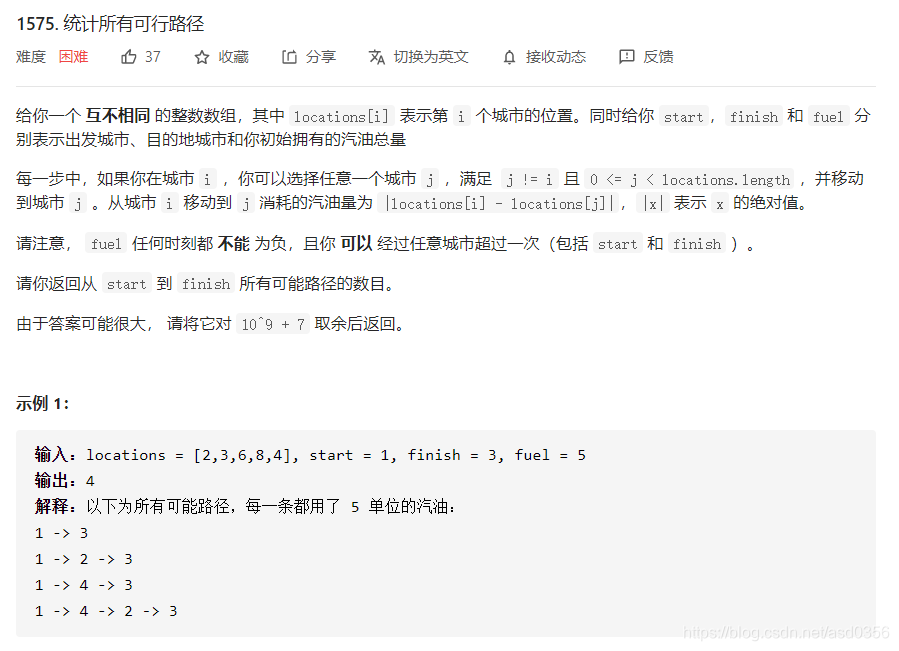 原题地址:统计所有可行路径
原题地址:统计所有可行路径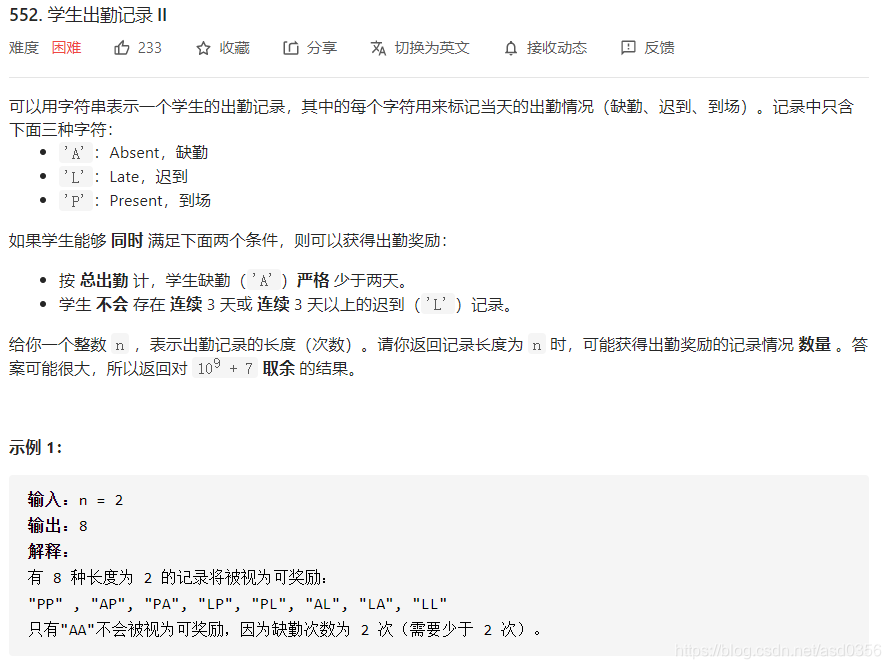 原题地址:学生出勤记录 II
原题地址:学生出勤记录 II 原题地址:“马”在棋盘上的概率
原题地址:“马”在棋盘上的概率 原题地址:骑士拨号器
原题地址:骑士拨号器【本文地址】