| 高并发系统设计细节 | 您所在的位置:网站首页 › 并发3000 › 高并发系统设计细节 |
高并发系统设计细节
|
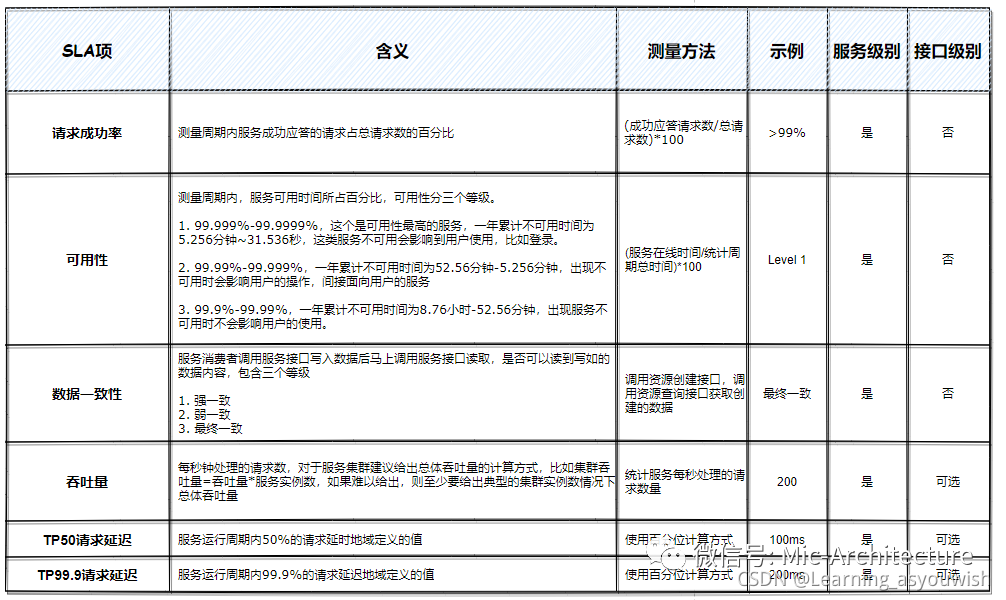
关键指标:响应时间、QPS(每秒查询数)、TPS(每秒处理的事务数)、成功率。根据不同的业务场景,平衡各个指标之间的关系。 响应时间: 当用户在2秒内得到响应,会感觉系统的响应很快; 当用户在2~5秒内得到响应,会感觉系统的响应速度很慢,可以接受; 当用户超过8秒仍不能得到响应,会感觉系统很糟糕,此时会选择离开站点或者发起二次请求。 SLA:服务登记协议,服务提供者对服务消费者的正式承诺,是衡量服务能力等级的关键项。 指标的计算: 假设在一个小时内,有200W用户访问系统,平均每个用户请求的耗时是3秒。 QPS=2000000/(6060)=556 并发数=5563=1668 随着RT的值越大,并发数越多,意味着服务端占用的连接数越多,会消耗内存资源和CPU资源等。在实际业务中,RT的值越小越好,应该缩小RT的值。 2/8法则推算1000W用户的访问量: 1000w用户,每天访问的用户占20%,也就是每天有200w用户来访问。假设平均每个用户过来点击5次,总共的pv=1亿。一天24小时,根据2/8法则,每天8000w(80%)用户活跃的时间点集中在(24*0.2)5小时内。此时的 QPS = 4500(8000w/5小时,平均每秒查询数)。在这5个小时中请求并非非常平均,可能会存在大量的用户集中访问,因此一般情况下访问峰值是平均访问请求的3~4倍左右,此时的QPS大约QPS=18000。 服务器压力估计: TCP连接对于系统资源最大的开销就是内存。 因为tcp连接归根结底需要双方接收和发送数据,那么就需要一个读缓冲区和写缓冲区,这两个buffer在linux下最小为4096字节,可通过cat /proc/sys/net/ipv4/tcp_rmem和cat /proc/sys/net/ipv4/tcp_wmem来查看。 所以,一个tcp连接最小占用内存为4096+4096 = 8k,那么对于一个8G内存的机器,在不考虑其他限制下,最多支持的并发量为:810241024/8 约等于100万。此数字为纯理论上限数值,在实际中,由于linux kernel对一些资源的限制,加上程序的业务处理,所以,8G内存是很难达到100万连接的,当然,我们也可以通过增加内存的方式增加并发量。 如何降低RT的值? 请求执行过程中会做的事情:查询数据库、访问磁盘数据、进行内存运算、调用远程服务。 每一步操作都会消耗一定量的时间,当前客户端的请求只有等到这些操作都完成之后才能返回,因此降低RT可以通过优化业务处理逻辑。 1 数据库优化 当18000个请求进入到服务端并且被接收后,开始执行业务逻辑处理,那么必然会查询数据库。每个请求至少都有一次查询数据库的操作,多的需要查询3~5次以上,我们假设按照3次来计算,那么每秒会对数据库形成54000个请求,假设一台数据库服务器每秒支撑10000个请求(影响数据库的请求数量有很多因素,比如数据库表的数据量、数据库服务器本身的系统性能、查询语句的复杂度),那么需要6台数据库服务器才能支撑每秒10000个请求。如果数据库服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。 数据表数据量过大,比如达到几千万甚至上亿,这种情况下sql的优化已经毫无意义了,因为这么大的数据量查询必然会涉及到运算。 可以缓存来解决读请求并发过高的问题,一般来说对于数据库的读写请求也都遵循2/8法则,在每秒54000个请求中,大概有43200左右是读请求,这些读请求中基本上90%都是可以通过缓存来解决。分库分表,减少单表数据量,单表数据量少了,那么查询性能就自然得到了有效的提升•读写分离,避免事务操作对查询操作带来的性能影响。写操作本身耗费资源数据库写操作为IO写入,写入过程中通常会涉及唯一性校验、建索引、索引排序等操作,对资源消耗比较大。一次写操作的响应时间往往是读操作的几倍甚至几十倍。锁争用写操作很多时候需要加锁,包括表级锁、行级锁等,这类锁都是排他锁,一个会话占据排它锁之后,其他会话是不能读取数据的,这会会极大影响数据读取性能。所以MYSQL部署往往会采用读写分离方式,主库用来写入数据及部分时效性要求很高的读操作,从库用来承接大部分读操作,这样数据库整体性能能够得到大幅提升。为什么数据放入redis缓存中能提升性能? (1)redis存储的是k-v数据,时间复杂度是0(1),MySQL存储引擎的底层实现是B+树,时间复杂度是O(logn)。 (2)Mysql数据存储是存储在表中,查找数据时要先对表进行全局扫描或根据索引查找,这涉及到磁盘IO,磁盘查找如果是单点查找可能会快点,但是顺序查找就比较慢。而redis不用这么麻烦,本身就是存储在内存中,会根据数据在内存的位置直接取出。 (3)Redis是单线程的多路复用IO,单线程避免了线程上下文切换的开销,而多路复用IO避免了IO等待的开销,在多核处理器下提高处理器的使用效率可以对数据进行分区,然后每个处理器处理不同的数据。2 磁盘数据访问优化 对磁盘的访问主要是读和写操作,优化方案如下: (1)磁盘的页缓存,借助缓存IO,充分利用系统缓存,降低实际IO的次数。 (2)顺序读写,可以用追加写代替随机写,减少寻址开销,加快IO写的速度。 (3)SSD代替HDD,固态硬盘的IO效率远远高于机械硬盘。 (4)在需要频繁读写同一块磁盘空间时,可以用mmap(内存映射)代替读写,减少内存的拷贝次数。 (5)在需要同步写的场景下,尽量将写请求合并,而不是让每个请求都同步写入磁盘,可以用fsync。 3 合理利用内存 充分利用内存缓存,把一些经常访问的数据和对象保存在内存中,这样可以避免重复加载或者避免数据库访问带来的性能损耗。比如利用redis缓存热点数据。 4 调用远程服务 远程服务调用的影响IO性能因素: 远程调用等待返回结果的阻塞、异步通信、网络通信的耗时、内网通信、增加网络带宽、远程服务通信的稳定性。 5 异步化架构 微服务中的逻辑复杂处理时间长的情况,在高并发下,导致服务线程消耗尽,不能创建线程处理请求。可以考虑在架构上做调整,先返回结果给客户端,让用户可以继续使用客户端的其他操作,再把服务端的复杂逻辑处理模块做异步化处理。异步化处理适用于客户端对处理结果不敏感不要求实时的情况,比如群发邮件、群发消息等。 |
 TPS:每秒处理的事务数,从客户端发起请求开始计时,等收到服务器端响应结果后结束计时,在计算这个时间段内总共完成的事务个数。一个事务指的是客户端发起一个请求,并且等到请求返回之后的整个过程。 QPS:每秒的查询请求数,表示服务器端每秒能够响应的查询次数。一个TPS中可能会包括多个QPS。 RT:响应时间,表示客户端发出请求到服务端返回的时间间隔,一般表示平均响应时间。 并发数:指的是系统同时能处理的请求数量。如果QPS=1000,表示每秒钟客户端会发起1000个请求到服务端,而如果一个请求的处理耗时是3s,那么意味着总的并发=1000*3=3000,也就是服务端会同时有3000个并发。
TPS:每秒处理的事务数,从客户端发起请求开始计时,等收到服务器端响应结果后结束计时,在计算这个时间段内总共完成的事务个数。一个事务指的是客户端发起一个请求,并且等到请求返回之后的整个过程。 QPS:每秒的查询请求数,表示服务器端每秒能够响应的查询次数。一个TPS中可能会包括多个QPS。 RT:响应时间,表示客户端发出请求到服务端返回的时间间隔,一般表示平均响应时间。 并发数:指的是系统同时能处理的请求数量。如果QPS=1000,表示每秒钟客户端会发起1000个请求到服务端,而如果一个请求的处理耗时是3s,那么意味着总的并发=1000*3=3000,也就是服务端会同时有3000个并发。【本文地址】