| 常见的函数 | 您所在的位置:网站首页 › 帆软排名函数 › 常见的函数 |
常见的函数
|
示例数据:内置数据「CUSTOMER」 2.1 创建模板新建一张模板,新建数据库查询 ds1:SELECT * FROM CUSTOMER,如下图所示:
分别在单元格中输入如下公式: 输入公式返回数值效果公式写法写法说明 = value("ds1",3,2) 将返回 customer 表中的第三列第二行的数据 Washington Value(tabledata,col,row)
返回 TableData 中列号为 col,行号为 row 的值。
Value(tabledata,col,row)
返回 TableData 中列号为 col,行号为 row 的值。
=value("ds1",3) 注:由于返回的是数组,因此设置扩展属性为从上向下扩展。 将返回数据表中的第三列数据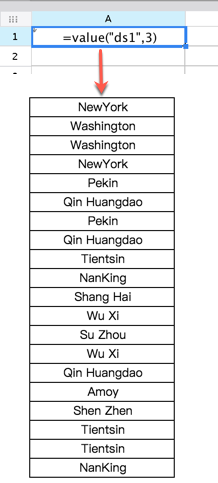 Value(tableData,col)
返回 TableData 中列号为 col 的一列值
Value(tableData,col)
返回 TableData 中列号为 col 的一列值
=value("ds1",3,4,"America") 注:由于返回的是数组,因此设置扩展属性为从上向下扩展。 返回数据表中第三列元素,且该列元素对应的第四列元素的值是 America 的所有数据 Value(tableData,targetCol,orgCol,element)
返回 TableData 中第 targetCol 列中的元素,这些列元素对应的第 orgCol 列的值为 element。
=value("ds1",3,4,"America",1)
返回数据表中第三列元素,且该列元素对应的第四列元素的值是 America 的所有数据中第一个值
Value(tableData,targetCol,orgCol,element)
返回 TableData 中第 targetCol 列中的元素,这些列元素对应的第 orgCol 列的值为 element。
=value("ds1",3,4,"America",1)
返回数据表中第三列元素,且该列元素对应的第四列元素的值是 America 的所有数据中第一个值
 Value(tableData,targetCol,orgCol,element,idx)
返回 Value(tableData,targetCol, orgCol, element)数组的第 idx 个值
Value(tableData,targetCol,orgCol,element,idx)
返回 Value(tableData,targetCol, orgCol, element)数组的第 idx 个值
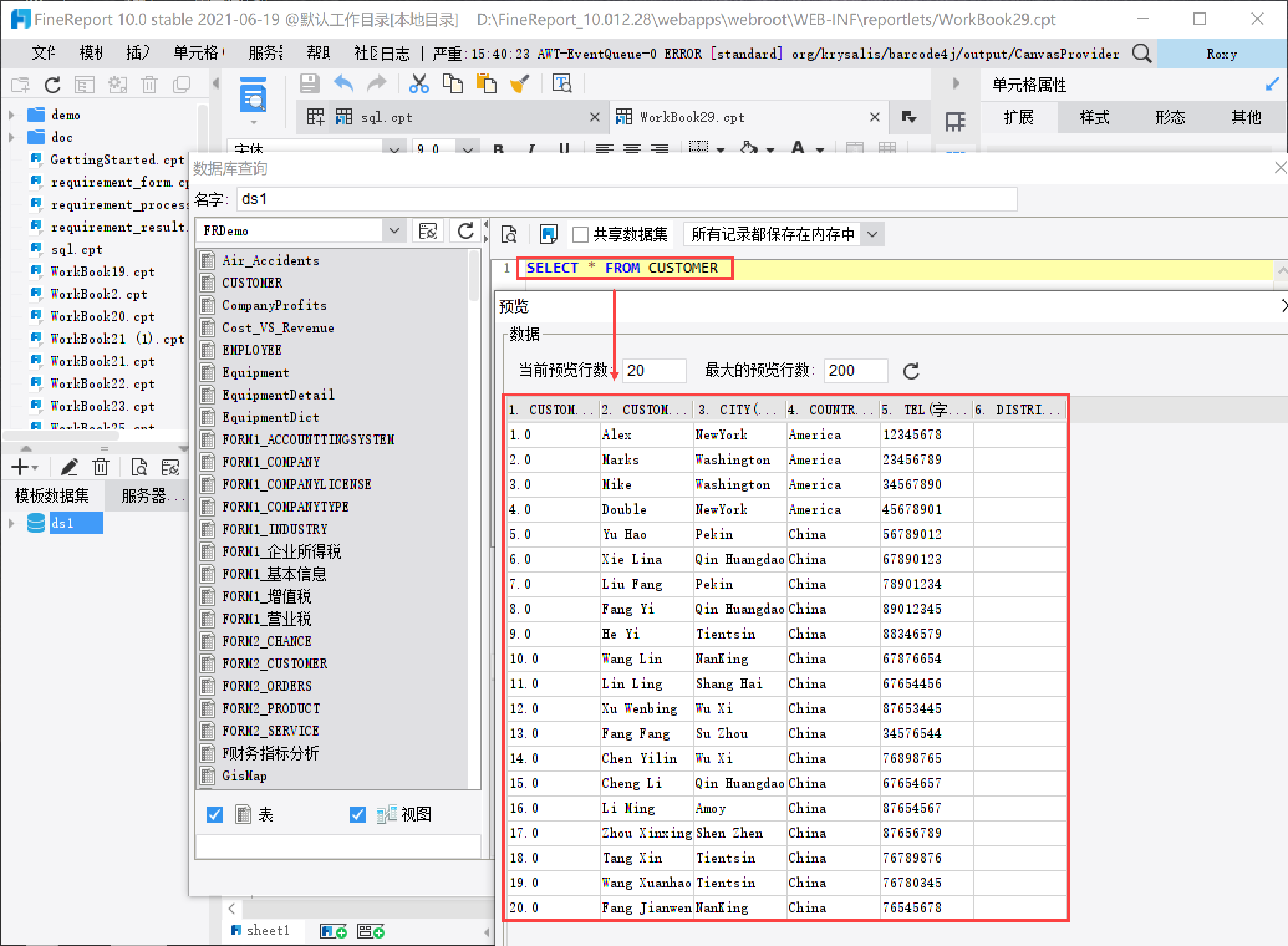
数据集函数概述 1. 概述 1.1 应用场景 将数据集中的数据列直接拖拽到单元格中使用时,如果想要「条件显示」某些数据列的值,那么可以使用数据集函数。 1.2 注意事项1)参数面板中不支持使用。 2)不支持模拟计算,模拟计算详情参见:2.4节。 3)决策报表填报事件不支持使用数据集函数。 2. tablename.select1)概述 语法 tablename.select(colname,筛选条件1&&筛选条件2&&......)筛选出数据集某列中符合条件的数据,返回结果是一个数组,相同数据不会合并 注:当仅返回一条数据时,数据类型是「字符串」而不是数组。 参数1 tablename 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 参数2 colname 表示列名,不区分大小写。2)注意事项 筛选条件中的判断既可以使用单等号,也可以使用双等号; 字符串也同时可以使用单引号或者是双引号,对结果均没有影响; tablename.select() 与 sql() 的区别主要在于 tablename.select() 是从数据集取数,sql() 是从数据库取数,不需要先定义一个数据集。详情参见 SQL 函数 在公式中,以 0 开头的字符串在匹配判断时,例如:ds1.select(colname,ID="003") 结果会返回对应 ID 为 0、03、003…… 的结果。若只希望返回 003 ,可以使用 EXACT 来做匹配判断。例如:ds1.select(colname,exact(ID,"003")) 如果想要进行模糊查询,可通过与 Find 函数 嵌套实现,例如公式:ds1.select(产品名称,FIND("苹果",产品名称)!=0),如下图所示:
3)示例 例如数据集 ds1 取出内置 FRDemo 数据库中的「S产品」表,分别在单元格中输入以下公式:
返回数据集 ds1 产品名称列中的所有产品名称。
返回数据集 ds1 库存量大于 20 且订购量大于 30 的产品。
返回数据集 ds1 供应商为1或者库存量大于 30 的产品。
1)概述 语法 tablename.group(colname,筛选条件 1 && 筛选条件 2,升降序) 筛选出数据集某列中符合条件的数据,若相邻数据相同则进行合并,还可以按照该列进行升降序排列。 参数1 tablename 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 参数2 colname 表示列名,不区分大小写。 参数3 升降序为布尔值,true 表示升序,false 表示降序。 注:若使用升降序参数,那么必须写筛选条件参数,若没有筛选条件,可以用 true 或者空格代替:例如=ds1.group(销售员,true,false)或者=ds1.group(销售员, ,false) 2)示例 如数据集 ds1 取出内置 FRDemo 数据库中的「销量」表: 公式说明 在单元格中输入=ds1.group(销售员) 返回数据集 ds1 销售员列中的值,并且相邻数据若相同会进行合并。 在单元格中输入=ds1.group(销售员,地区 = "华东"&&销量 > 200)返回数据集 ds1 华东地区销售总额超过 200 的销售员,并且相邻数据若相同会进行合并。
返回数据集 ds1 销售员列中的值,并且其中只要数据相同就会进行合并,结果为降序排列,中间的参数为过滤条件,若没有条件,可以用空替代或者使用 true 。
返回数据集 ds1 华东地区的销售员,并且相邻数据若相同会进行合并。 在单元格中输入=ds1.group(销售员,地区=="华东",true) 返回数据集 ds1 华东地区的销售员,并且会合并所有相同项,结果为升序排列。 4. tablename.select(#数字)
1)概述 语法 tablename.select(#数字) 返回数据集中的行号或者对应列数据 参数1 tablename 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 参数2 数字表示列号。 如果tablename.select(#0)则输出数据表行号数组(数据条数) tablename.select(#1)则输出数据库表中第一列的数组数据 2)注意事项
填报场景下 ds1.select(#0) 这个公式如果联动计算有异常,需要检查父子格关系。例如出现下图所示的计算结果时:
remoteEvaluate(String) 方法不支持 tablename.select 函数。 3)示例 例如数据集 ds1 取出内置 FRDemo 数据库中的「销量」表: 公式结果 在单元格中输入=ds1.select(#0)返回数据集中的行号
返回数据集中对应列数据
1)概述 语法 tablename.value(row,col/colname) 获取数据集 ds1 中某行某列的值。 参数1 tablename 表示数据集名称,注意是「报表数据集」或者是「服务器数据集」名,而非数据库中的表名。 参数2 row表示行号 参数3 col/colname 表示列号或者列名2)注意事项 报表的图表标题不支持该函数。 决策报表里的图表块不支持该函数。 JavaScript 中不支持该函数。 3)示例 例如数据集 ds1 取出内置 FRDemo 数据库中的「销量」表: 公式说明 在单元格中输入=ds1.value(3,2) 返回数据集 ds1 中第 3 行第 2 列的值 在单元格中输入=ds1.value(3,"销售员") 返回数据集 ds1 中第 3 行销售员列的值 6. 应用 6.1 根据不同条件选择使用哪个字段在单元格中输入如下公式: =if(条件,ds1.group(customerid),ds2.group(customerid)) 并设置其扩展属性为从上到下。 公式说明: 公式说明 =if(条件,ds1.group(customerid),ds2.group(customerid))条件为真,单元格使用数据集 ds1 中的 customerid 列,否则使用 ds2 中的 customerid 列 。 6.2 对数据集函数返回的数据再进行运算 在单元格输入公式=sum(ds1.select(销量)),返回数据集 ds1 销量列的总和。 sum 求和公式也可以换用其他如 count、max 等。 7. 注意事项 7.1 数据集函数返回的数据进行扩展直接将数据列拖拽到单元格时会自动从上到下扩展。但是使用数据集函数获得数据为一个数组,是显示在一个单元格中的,需要另外给单元格设置扩展属性,数据才会进行扩展。 例如在单元格输入公式=ds1.group(销售员,地区=="华东",true),设置扩展房方向为「纵向」,如下图所示:
预览报表如下图所示:
将日期型转化为中文形式 1. 描述 因政府、事业单位的正式文件中的落款日期都是中文的。 如:在 FineReport 中制作填报模板,使用了日期控件,希望在做填报时,将当前日期控件中选择的日期值(FR 中默认是yyyy-MM-dd的日期格式),能够以中文的方式输出显示,然后再入库,但入库的数据还是默认的数值型的 yyyy-MM-dd 的日期格式。 实现效果如下图:
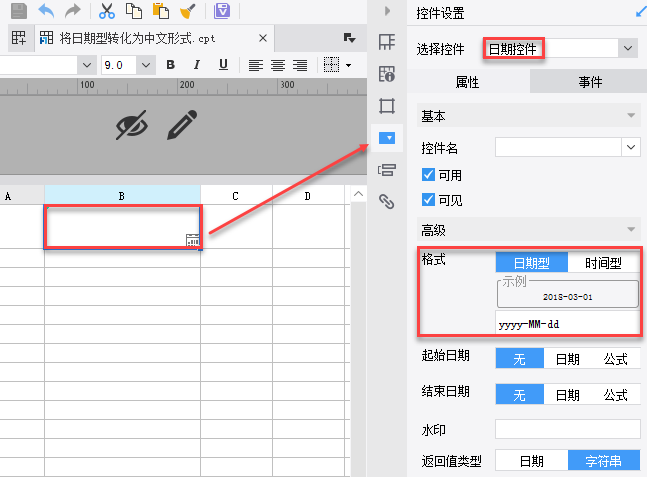
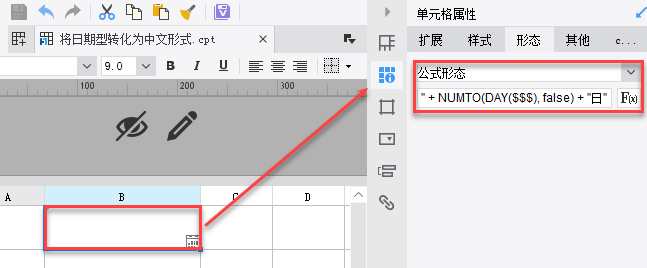
2. 思路 使用NUMTO()函数,通过字符转化方式,将其转化为中文输出即可。 NUMTO(number,bool):返回 number 的中文表示。 注:其中 bool 用于选择中文表示的方式,当没有 bool 时,采用默认方式(false)显示。 示例:NUMTO(2345,true)返回值为二三四五 示例:NUMTO(2345,false)返回值为二千三百四十五 示例:NUMTO(2345)返回值为二千三百四十五 3. 示例 3.1 控件设置 新建一张普通报表,右击任意单元格,选择控件设置,选择控件为日期控件,格式为 yyyy-MM-dd。如下:
3.2 属性设置 再右击此单元格,选择形态>公式形态,输入公式:REPLACE(NUMTO(YEAR($$$), true), "零", "〇") + "年" + NUMTO(MONTH($$$), false) + "月" + NUMTO(DAY($$$), false) + "日"
注:REPLACE(NUMTO(YEAR($$$),true),"零","〇"),表示将其中输出的中文的零替换为特殊字符 〇。 注:REPLACE 函数的具体使用,可参见文本函数。 4. 保存预览 保存模板后,选择填报预览。 在日期控件中选择好日期后,点击其他处,显示效果如上图所示。 注:有些日期的中文形式还想含有星期,公式如下所示。 示例: 【REPLACE(NUMTO(YEAR(today()),true),"零","〇")+"年"+format(today(),'MMMMM')+NUMTO(DAY(today()),false)+"日"+format(today(),'EEEEE')】返回值为【二O一八年二月十八日星期天】 5. 模板下载 点击下载模板:将日期型转化为中文形式.cpt 字符串与数组相加 1. 问题描述字符串与数组的相加有两种方式,一是直接使用+号,另外一种是使用字符串连接函数 concatenate,那么这两个有区别吗? 2. 使用+号连接字符串及数组 字符串会和每个数组元素分别进行相加。 如公式:="a"+[1,2,3]+"b",其结果是:a1b,a2b,a3b。 3. 使用 concatenate 函数连接字符串及数组 数组会被作为字符串与其他字符串串联。 如公式:=concatenate("a",[1,2,3],"b"),其结果是 a1,2,3b。
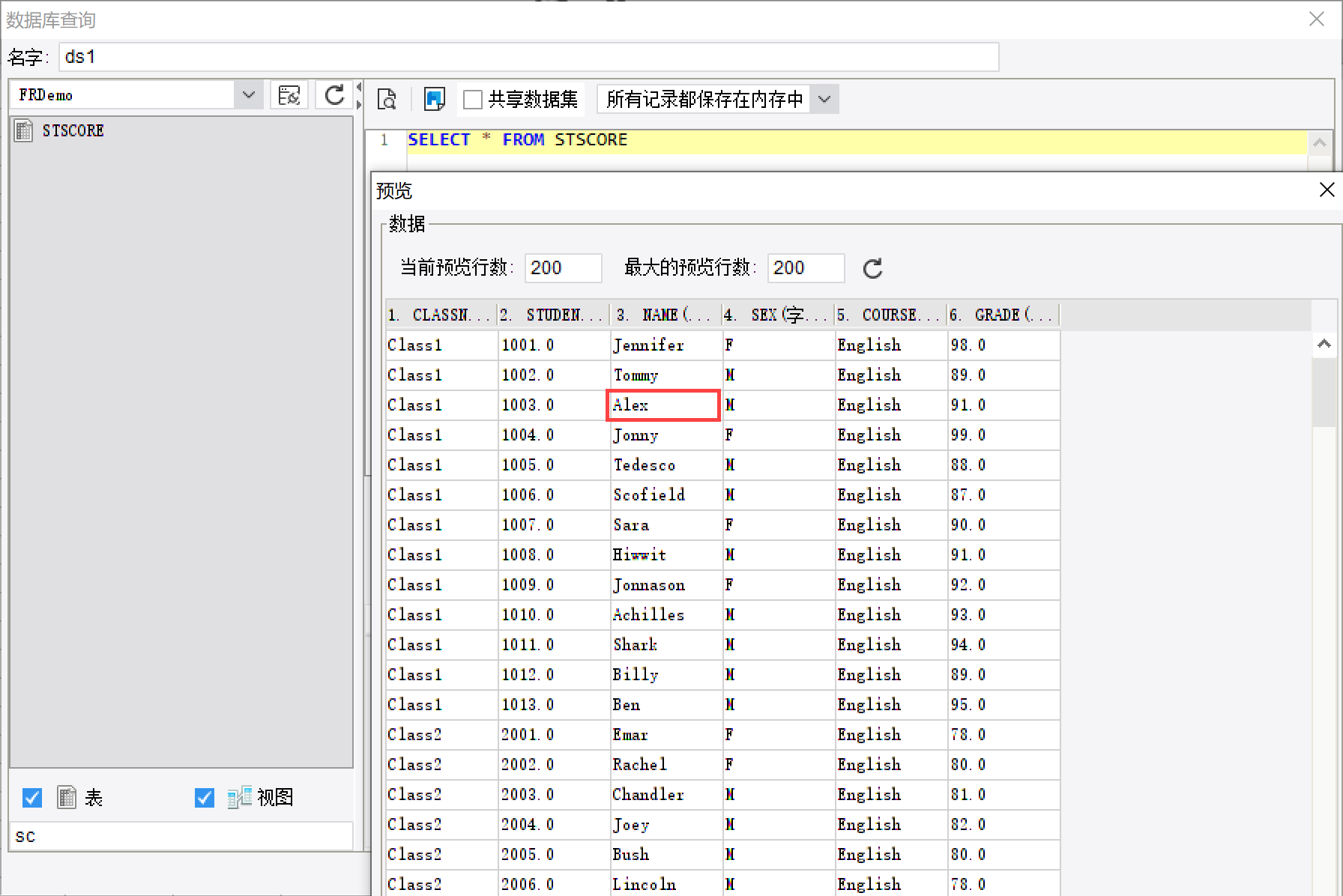
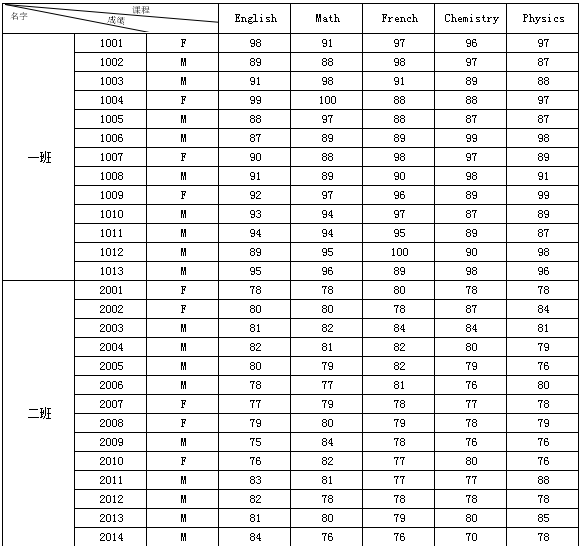
SQL函数 1. 概述 1.1 函数作用数据集函数 能够从数据集中直接进行条件取数,但是有的时候用户希望某个单元格能够直接获取到数据库中的某个值,而不是先要定义一个数据集后,再去取数据。 这时就可以用 SQL 函数。 1.2 函数解释 语法 SQL(connectionName,sql,columnIndex,rowIndex) 返回的数据是从 connectionName 数据库中获取的 SQL 语句的表中的第 columnIndex 列第 rowIndex 行所对应的元素。 参数1 connectionName 数据连接名字,字符串形式,需要用引号如"FRDemo"; 参数2 sql SQL 语句或者数据库存储过程,字符串形式,传参数、条件等可以在此拼接实现; 参数3 columnIndex 列序号,整型; 参数4 rowIndex 行序号,整型。注:行序号可以省略,这样返回值为数据列。 1.3 注意事项仅支持查询 sql 语句。 2. 取数据库中不带参数的指定内容示例数据:内置数据库 FRDemo 中的 STSCORE 数据表。 从内置数据库「FRDemo」里的 STSCORE 表取第三行第三列数据值。 从表 STSCORE 中,可看到第 3 行第 3 列的值为 Alex,如下图所示:
现在若要直接在报表的单元格中显示数据值:Alex,而不是通过先定义一个数据集后,再去取数据的方式,使用 sql() 公式,此时只需在单元格中输入:=sql("FRDemo","SELECT * FROM STSCORE",3,3)即可,预览就可看到 Alex 值,如下图所示:
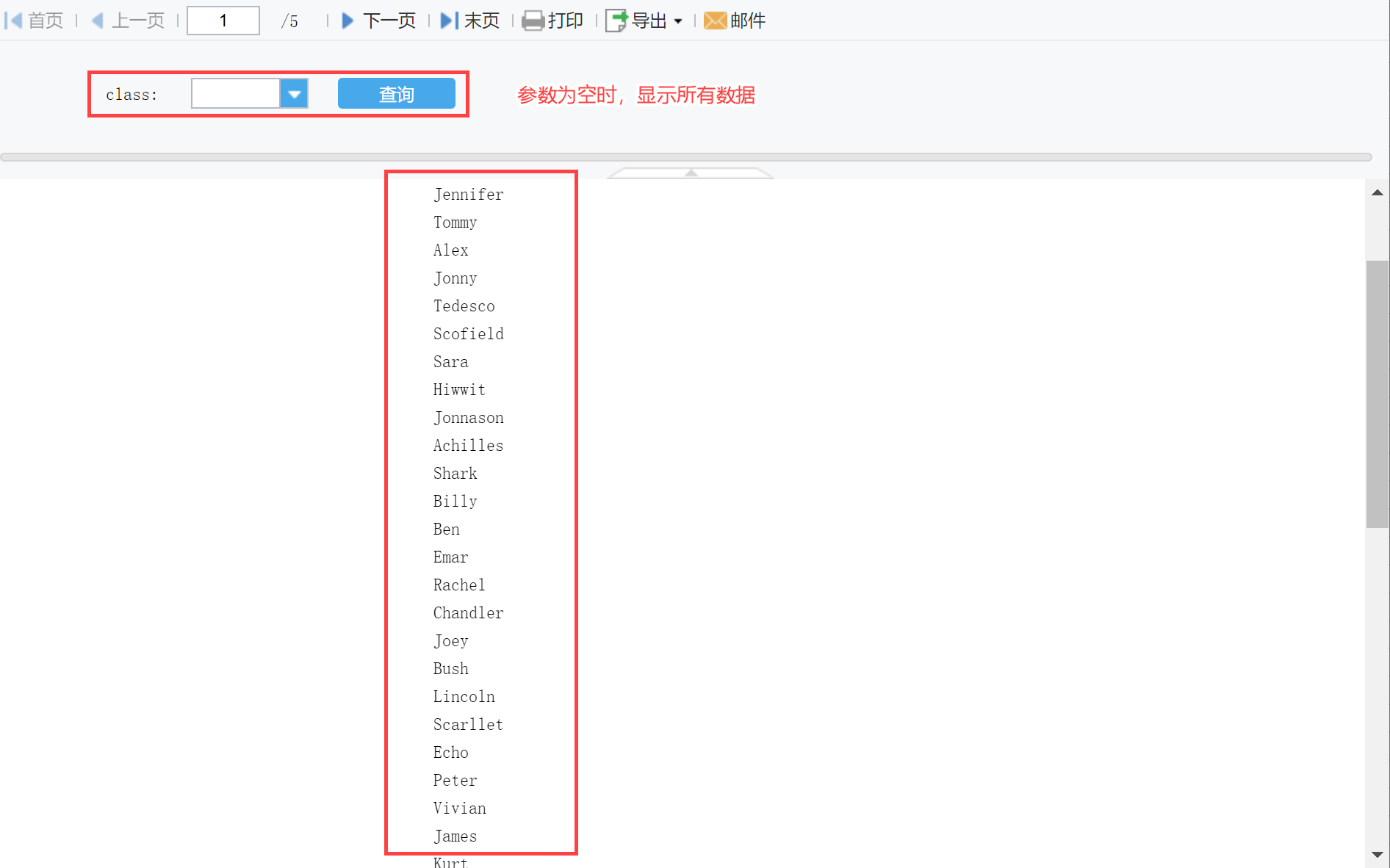
示例数据:内置数据库 FRDemo 中的 STSCORE 数据表。 3.1 SQL 参数为普通参数需要取出班级为 Class1 的第 3 列所有值。 在单元格中输入:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = 'Class1' ",3),显示效果(班级为 Class1 的第 3 列所有值),如下图所示:
公式说明: 公式说明 "FRDemo" 数据连接名 "SELECT * FROM STSCORE where CLASSNO = 'Class1' " SQL 语句;查询 CLASSNO 为 Class1 的数据 3 列序号,第三列的数据若需要显示某个具体值,如显示 Jonny (即班级为 Class1 的第 3 列第 4 行的值),写法如下: =sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = 'Class1' ",3,4) 3.2 SQL 参数为变量若参数值为变量如为报表参数或者是某个单元格,则写法如下:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$class+"' ",3,4) 或=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+A1+"' ",3,4) 例如希望过滤控件选择不同班级,显示不同班级下所有的同学的名字。 首先设置模板参数「class」,然后在单元格中输入公式:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$class+"' ",3),如下图所示:
显示效果如下图所示:
如果传递的参数是获取当前单元格的值,即用 $$$ 作为参数时,字符串类型同样需要拼接单引号,例如: =sql("FRDemo","SELECT * FROM STSCORE where CLASSNO = '"+$$$+"' ",3,4) 注1:如果参数或者单元格值有多个,那么 SQL 函数的写法如下:=sql("FRDemo","SELECT * FROM STSCORE where CLASSNO in ('"+$class+"') and COURSE in ('"+$COURSE+"') ",3,4) 注2:class 参数返回值的分隔符需为',',具体请查看下拉复选框参数联动。 3.3 SQL 参数为变量且需要拼接在 SQL 中还可以使用 IF 函数进行判断并拼接模板参数,例如希望实现当参数 class 为空时,选择全部学生姓名,可输入公式: =sql("FRDemo","SELECT * FROM STSCORE where 1=1 "+if(len(class)== 0,"","and CLASSNO = '"+class+"'"),3)
公式说明: 公式说明 "SELECT * FROM STSCORE where 1=1 " 将 SQL 语句两边加上引号作为字符串 +if(len(class)== 0,"","and CLASSNO = '"+class+"'"这里的+是指字符串拼接符号 将前面的 SQL 语句通过+进行拼接 当参数「class」为空,查询语句相当于:SELECT * FROM STSCORE 当参数「class」不为空时,查询语句相当于:SELECT * FROM STSCORE WHERE 1=1 and CLASSNO ='"+$class+"' sql("FRDemo","SELECT * FROM STSCORE where 1=1 "+if(len(class)== 0,"","and CLASSNO = '"+class+"'"),3)当参数「class」为空,相当于:sql("FRDemo","SELECT * FROM STSCORE",3) 当参数「class」不为空时,查询语句相当于:sql("FRDemo","SELECT * FROM STSCORE WHERE 1=1 and CLASSNO ='"+$class+"'",3) 如果在 SQL 中参数为模糊查询时,可使用如下公式: =sql("FRDemo","SELECT * FROM STSCORE where CLASSNO like '%"+$class+"%' ",3,4) 利用sql进行排序 1. 描述 在对数据进行展示之前,如果没有对数据进行排序,会使数据看起来一片混乱,不能清晰地看到各数据之间的关系。而排序,也有各种各样的需求,如按时间排序,按数字排序,按中文排序等,如果我们只会使用使用设计器的高级排序,扩展后排序,将无法满足各种特殊的排序需求。 2. 解决方案 通过sql直接在数据库中排序,这样不仅性能最佳,而且各数据库对各种特殊的排序需求也比较支持,这里以Oracle为例。 3. 示例 3.1 简单的升序、降序 使用asc进行升序排序,如select * from table order by id asc 注:asc可以省略,默认为升序 使用desc进行降序排序,如select * from table order by id desc 3.2 空值排序 如果我们想要排序后空值永远在前面可以使用nulls first,如:
 使用case when..then...来自定义(不推荐):
使用case when..then...来自定义(不推荐):

Cnmoney函数 1. 问题描述 在票据类汇总报表中,为防止随意涂改作假,常需将金额转换为大写的人民币形式,此时可使用Cnmoney()函数直接进行转换。 2. 公式的使用说明 Cnmoney(number,unit):返回人民币大写。 其中,number:需要转换的数值型的数。 unit:单位,"s","b","q","w","sw","bw","qw","y","sy","by","qy","wy"分别代表“拾”,“佰”,“仟”,“万”,“拾万”,“佰万”,“仟万”,“亿”,“拾亿”,“佰亿”,“仟亿”,“万亿”。 注:单位可为空,如果为空,则直接将number转换为人民币大写,否则先将number与单位的进制相乘,然后再将相乘的结果转换为人民币大写。 3. 示例 CNMONEY(1200)等于壹仟贰佰圆整。 CNMONEY(12.5,"w")等于壹拾贰万伍仟圆整。 CNMONEY(56.3478,"bw")等于伍仟陆佰叁拾肆万柒仟捌佰圆整。 CNMONEY(3.4567,"y")等于叁亿肆仟伍佰陆拾柒万圆整。 同样,有时也需要将数字用中文来表示,此时可使用NUMTO()函数。 Switch函数:Switch函数多条件赋值 1. 概述 1.1 问题描述 当需要判断条件多的时候,使用 IF 函数 可能会觉得用要对每种情况都进行判断,比较麻烦,那么可以使用 switch 函数与NVL函数结合进行多条件赋值。 例如希望对班级进行设置:当前值是 Class1 则显示一班,如果是 Class2,则显示二班,如果是 Class3,则显示三班,否则则显示四班,如下图所示:
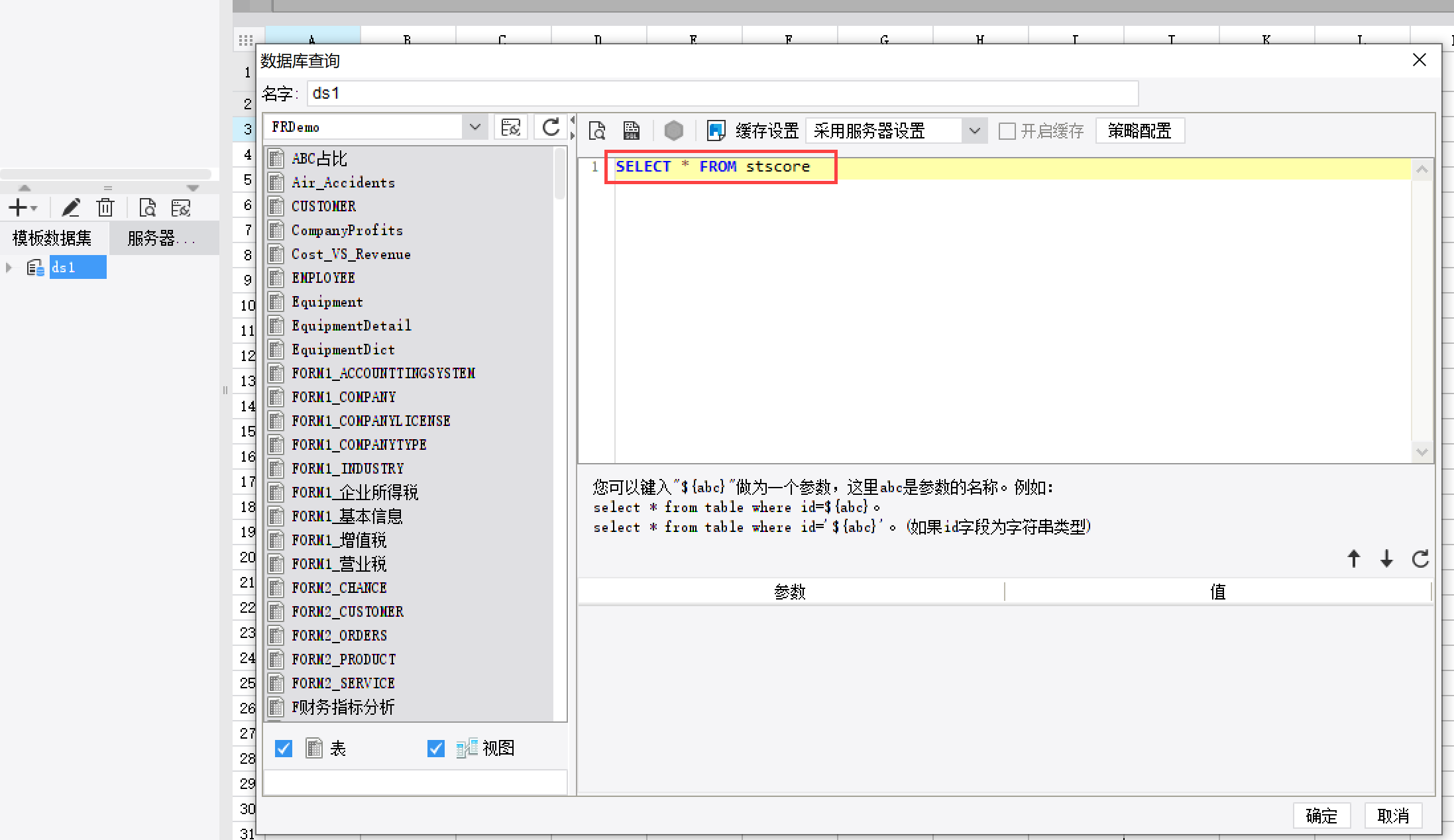
使用 switch 函数与NVL函数结合进行多条件赋值。 2. 操作步骤 3.1 报表设计 3.1.1 数据准备新建数据查询 ds1,数据查询语句如下:SELECT * FROM stscore,如下图所示:
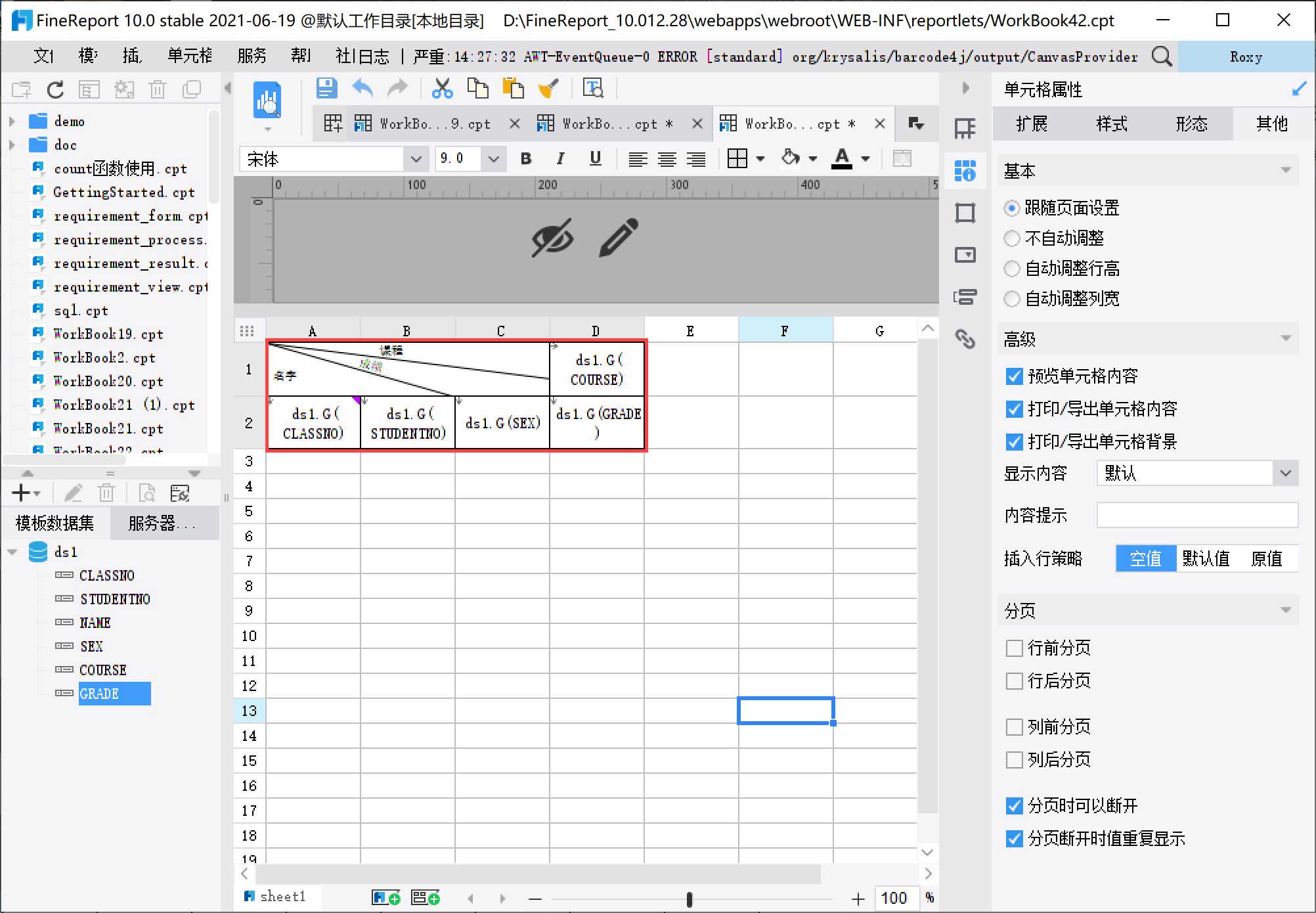
1)设置模板样式,如下图所示: 注:插入斜线可参见 插入 2.7 节。
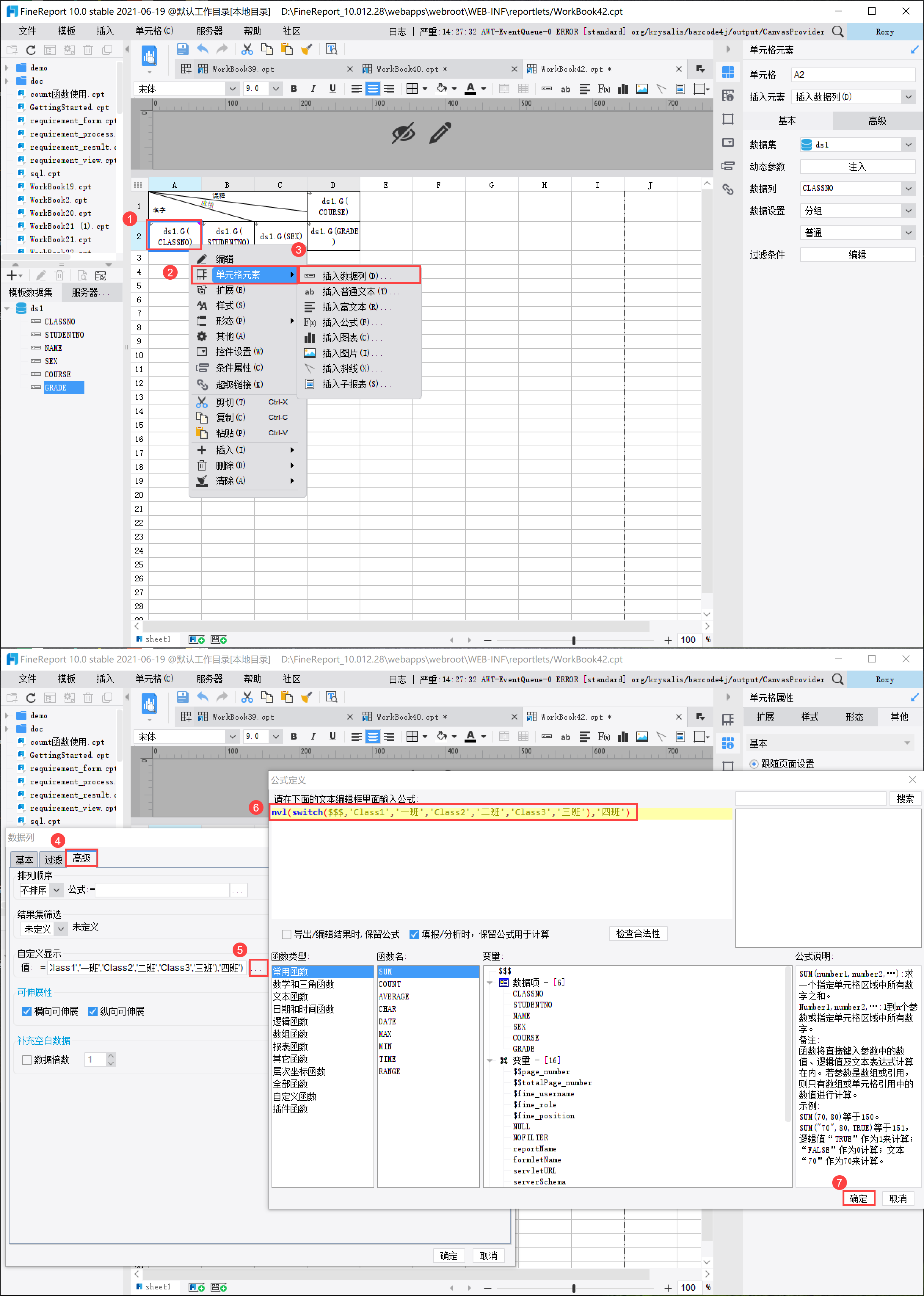
2)设置公式 单击 A2 单元格,右键单击「单元格元素>插入数据列>高级」,或者双击单元格,点击「高级」,在自定义显示的值中填入公式:nvl(switch($$$,'Class1','一班','Class2','二班','Class3','三班'),'四班'),如下图所示:
公式说明: 公式说明 switch($$$,'Class1','一班','Class2','二班','Class3','三班') 如果数据为 Class1,则赋值为一班,Class2 则赋值为二班,Class 三则赋值为三班 nvl(switch($$$,'Class1','一班','Class2','二班','Class3','三班'),'四班') 返回第一个不是空的字段,即数据如果不是一班、二班或者三班,则返回「四班」 3.2 效果查看1)PC端 保存模板,点击分页预览,如下图所示: 注:若希望不分页展示,可以选择「数据分析预览」。
2)移动端
NVL函数 1. 函数用法 NVL 函数的使用方法:NVL(value1,value2,value3,...):在所有参数中返回第一个不是 null 的值。 注:6.5 之前的版本 NVL 只支持 2 个参数,现在升级到支持多个参数。 下面以填报的示例来说明 NVL 多参数的用法。 2. 需求填报应用中,可能会遇到一组单元格中,只需将其中不为空的值保存至数据库的某个字段,如下图所示,对于语文成绩级别这个字段,可能有四个值,入库的时候只保存选择的级别。 3. 示例 3.1 创建数据 在数据库中新建一个表,表名为 C,新建如下数据:
然后,添加其报表数据集 ds1,SQL 语句为:select * from C 3.2 表样设计如下图所示,拖动字段到对应单元格并做相应合并:
设置 B5、C5、E5、E6、E7、E8 为文本类型控件即可。
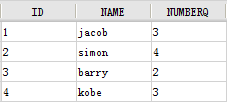
对 E5 单元格,设置条件属性:不等于 4 时,公式为$$$!=4,赋新值为空,如下:
对 E6 单元格:设置为不等于 3 时,公式为$$$!=3,赋新值为空; 对 E7 单元格:设置为不等于 2 时,公式为$$$!=2,赋新值为空; 对 E8 单元格:设置为不等于 1 时,公式为$$$!=1,赋新值为空。 3.5 其他属性设置为了保证“优秀”等不设置控件的单元格在添加记录时能默认添加,可设置单元格属性表-其他属性>插入行策略>原值,如下图:
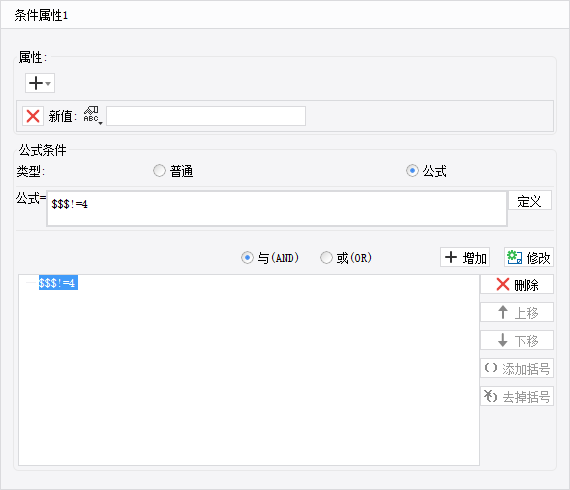
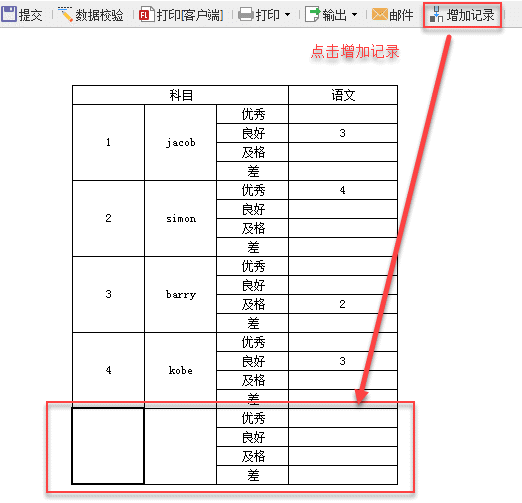
在 NUMBERQ 的值中,输入=NVL(E5,E6,E7,E8),取出第一个不为空的值进行填报,如下:
在设计器中,点击填报预览,效果:
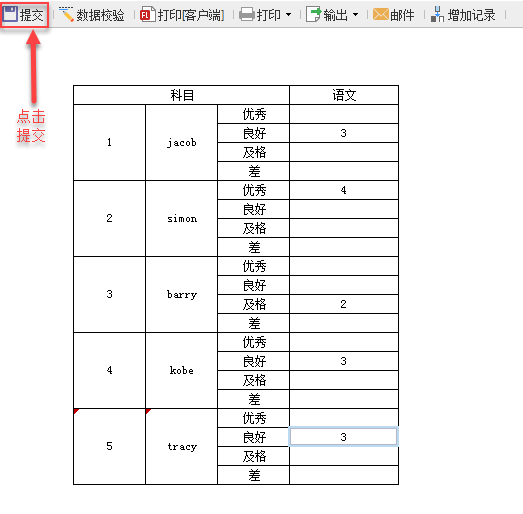
点击增加记录后,点击提交,如下:
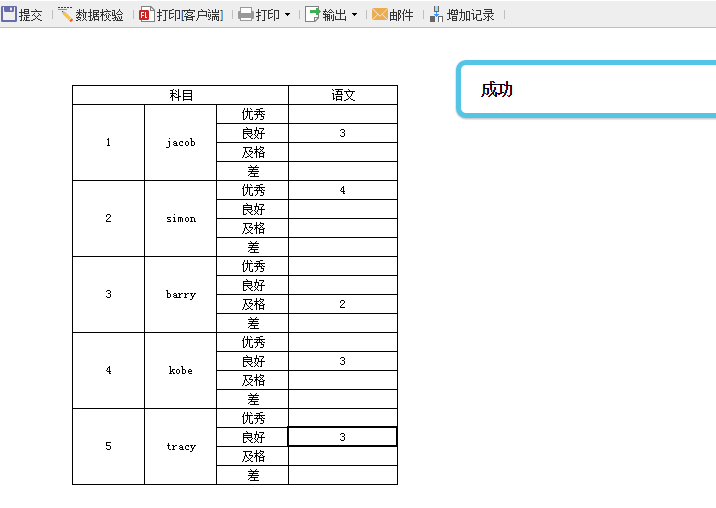
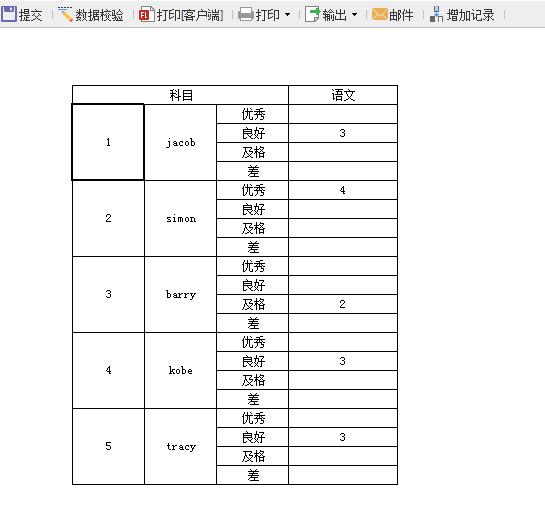
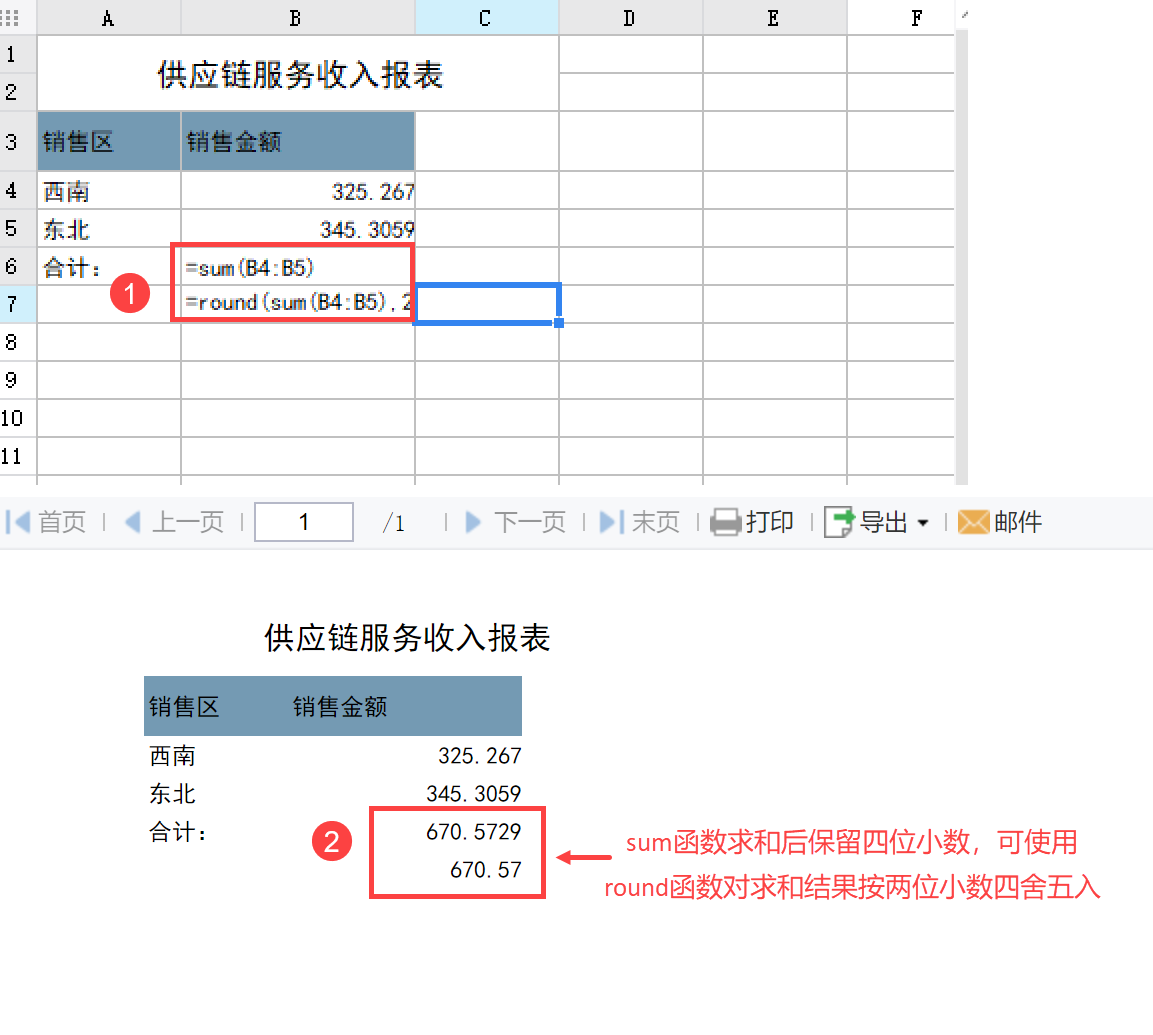
提交成功时,效果如下: 刷新页面,可见提交成功,提交值就是第一个不为空的值 3,如下: 点击下载模板:NVL函数.cpt Let函数 1. 函数作用报表中,若使用到复杂的FR脚本表达式,如:=if (很长很长的公式 > 0,执行语句 1(很长很长的公式),执行语句 2(很长很长的公式)),首先想到的是:将很长很长的公式先放在一个单元格(如:A1)中,然后在另一个单元格中,输入=if(a1>0, 执行语句1(a1), 执行语句2(a1))。对于这样的很长公式,一般公式中还会有部分内容是一些其他的简单运算,若再使用单元格去求算一下,最终求算最终结果时就得引用多个单元格。这样的赋值方式,不但多占用空间内存使得重复计算,其性能往往也不是很好。据此 FR 已增加 LET 公式,可将其很长的公式直接赋值,且可直接使用此公式求解最终结果(复杂的脚本表达式),还可提高其性能。 2. 使用说明 2.1 LET()函数说明LET(变量名,变量值,变量名,变量值,...,表达式):局部变量赋值函数,参数的个数 N 必须为奇数, 最后一个是表达式,前面是 N-1(偶数)为局部变量赋值对。 变量名:必须是合法的变量名,以字母开头,可包括字母,数字和下划线。 表达式:根据其前面的 N-1 个参数赋值后,需计算的结果表达式,且这些变量赋值只在这个表达式内部有效。 示例: LET(a, 5,b, 6, a+b)等于 11。 2.2 示例下面根据如上所遇的情况示例介绍,您可根据实际情况,参照示例使用此公式。 1)一个很长的公式为((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1),若将其赋给 a,需计算 IF(a>1000,(a+200)/a,(a-200)*a)的结果表达式。 2)通常的做法:在任意单元格(如:A1)中,输入((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1),然后在另一个单元格(如:B1)中,输入=IF(A1>1000,(A1+200)/A1,(A1-200)*A1)。 3)而计算时是将 A1 中的值,对应带入其结果表达式中的。如这边带入的话就是计算=IF((((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))>1000,((((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))+200)/(((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1)),((((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))-200)*(((10+20+30)*MAX(10,20,30)+DATEDIF("2001/2/28","2004/3/20","D"))*COS(0.5)/ROUND(2.15, 1))) 不仅多占用单元格且使得表达式重复计算,其性能往往也不是很好。 4)LET 公式的写法:只需在单元格中直接赋值和写入结果表达式。在一个单元格中,直接输入=LET(a, ((10 + 20 + 30) * MAX(10, 20, 30) + DATEDIF("2001/2/28", "2004/3/20", "D")) * COS(0.5) / ROUND(2.15, 1), IF(a> 1000, (a+ 200) / a, (a - 200) * a))即可执行结果表达式,从而得出最终结果。 2.3 总结对比可看出,使用 LET 公式明显比通常的做法来得简单,且公式中若再有其他简单运算,如:最大值、平均值等等,也可不必再次占用其他单元格然后再引用此类单元格,这边可直接一步到位求算结果(亦可在 LET 中直接写一些常用的计算公式),这样也大大地提高了性能。 Round函数 1. 概述 1.1 应用场景 在制作报表时,某数据列如收入金额是数字类型,其中数据包含小数,且小数位数不超过 2 位,对该列进行求和(使用公式 sum)等处理时,会发现最终的结果如:123456.409999996,即小数位数超过 2 位。 此时您可能会有疑问,为什么小数位数不是 2 位?若您的报表对有效位数比较敏感,如金额汇总,总金额最多精确到分,即小数位数最多 2 位,该怎么办? 1.2 功能简介此情况时,可使用 round() 函数对计算后的结果按指定位数四舍五入来解决。 2. 示例 2.1 函数说明 1)概述 语法 ROUND(number,num_digits, boolean)返回某个数字按指定位数舍入后的数字。 参数1 number需要进行舍入的数字 参数2 num_digits 指定的位数,按此位数进行舍入。 如果 num_digits 大于 0,则舍入到指定的小数位。 如果 num_digits 等于 0,则舍入到最接近的整数。 如果 num_digits 小于 0,则在小数点左侧进行舍入。 参数3 boolean因浮点数存在精度计算丢失问题,导致计算结果里可能带上 9999、0000 这些,因此加入第三个参数来控制是否需要去除 9999、0000。 false 表示需要过滤 9999、0000 这些数据;true 表示保留,参数为空则默认为 false。
2)注意事项 2020-07-08 及之后版本的 JAR 包才会有第三个参数。 2020-07-08 及之后版本的 JAR 包 number 参数支持字符串。 3)示例 公式结果 ROUND(2.15, 1) 2.2 ROUND(2.149, 1) 2.1 ROUND(-1.475, 2) -1.48 ROUND(21.5, -1) 20 ROUND(1.99999999, 8) 2 ROUND(1.99999999, 8, true) 1.99999999 2.2 操作步骤报表中的销量列求和,设计如下:
如上对收入 sum 求和后精度变大了。 遇到这样的情况时,可使用 round 函数对求和结果按 2 位小数位四舍五入,即 B5 单元格中的使用方法。 Map函数 1. 函数作用 在制作报表时,我们可能需要根据某一单元格的值对数据集进行检索并返回对应的值。 此情况时,可使用 map() 函数,根据数据集的名字,找到对应的数据集,找到其中索引列的值为 key 所对应的返回值。 map() 函数首先检索模板数据集,再检索服务器数据集。 示例: MAP(1001,"employee",1,2)返回 employee 数据集,第 1 列中值为 1001 那条记录中第 2 列的值。 MAP(1001,"employee","name","address")返回 employee 数据集,name 列中值为 1001 那条记录中 address 列的值。注:只返回第一个找到的值。 2. 使用说明 MAP(object,string,int,int):根据数据集的名字,找到对应的数据集,找到其中索引列的值为 key 所对应的返回值。 object:索引值,需要查询的内容。 string:数据集的名字,定义的数据查询的名字。 int:索引值所在列序号。 int:返回值所在列序号。 注:后两个参数也可以写列名代替。根据数据集的名字,找到对应的数据集,找到其中索引列的值为key所对应的返回值。数据集的查找方式是依次从报表数据集找到服务器数据集。索引列序号与返回值序列号的初始值为1。 3. 示例 3.1 报表设计 3.1.1 数据准备新建数据查询 ds1 ,SQL 语句如下SELECT * FROM 供应商,如下图所示:
新建普通报表,分别给 A1~A5 单元格赋值,单击 A2 单元格,右键选择单元格元素,选择插入公式,公式如下: MAP(A1, "ds1", "公司名称", "供应商ID")返回 ds1 数据集,“公司名称”列中值为 A1 那条记录中“供应商 ID”列的值。 MAP(A1, "ds1", 2, 1)返回 ds1 数据集,第 2 列中值为 A1 那条记录中第1列的值。 MAP("妙生", "ds1", "公司名称", "供应商ID")返回 ds1 数据集,“公司名称”列中值为“妙生”那条记录中“供应商 ID”列的值。 MAP("妙生", "ds1", 2, 1)返回 ds1 数据集,第2列中值为“妙生”那条记录中第1列的值。
1)PC端 保存模板,点击分页预览,如下图所示:
2)移动端
点击下载模板:Map函数.cpt treelayer函数 1. 概述 语法:treelayer(TreeObject, Int, Boolean, String) 定义:返回一个树对象 TreeObject 第 n 层的值,一般为树数据集,或下拉树、视图树等树对象,并且可以设置返回值类型及分隔符。
详细解释: 对象定义值 TreeObject tree 对象 例如:$tree Int 想要获得层级的数值最上层为 1 ,第二层为 2 ,依此类推,若无则返回最底层 Boolean 返回值类型false:返回值类型为数组,默认值 true:返回值类型为字符串 String 当返回值类型为字符串时的分隔符以双引号表示,默认为逗号:"," 2. 示例以一个下拉树控件展示 FRDemo 数据库中的部门层级树为例,来讲解 treelayer 函数的作用。 2.1 新建数据集 2.1.1 新建数据库查询新建普通报表,新建数据集 ds1,SQL 语句为:select * from department,如下图所示:
新建一个树数据集 Tree1,数据集为 ds1,依赖字段为 did,父标记字段为 fid,如下图所示:
树数据集效果预览如下图所示:
2.2 添加控件 在参数栏添加两个控件:一个下拉树控件和一个文本控件,如下图所示:
下拉树控件的控件名称修改为 tree。勾选 多选和结果返回完整层次路径。 数据字典选择自动构建,依靠树数据集 Tree1 构建,实际值和显示值都选择 department。如下图所示:
文本控件的控件值选择公式:treelayer($tree, true, "\',\'"),如下图所示:
2.4 效果预览 保存模板,点击预览,勾选总部>人力资源部>人力资源文员、总部>市场部>业务员,如下图所示:
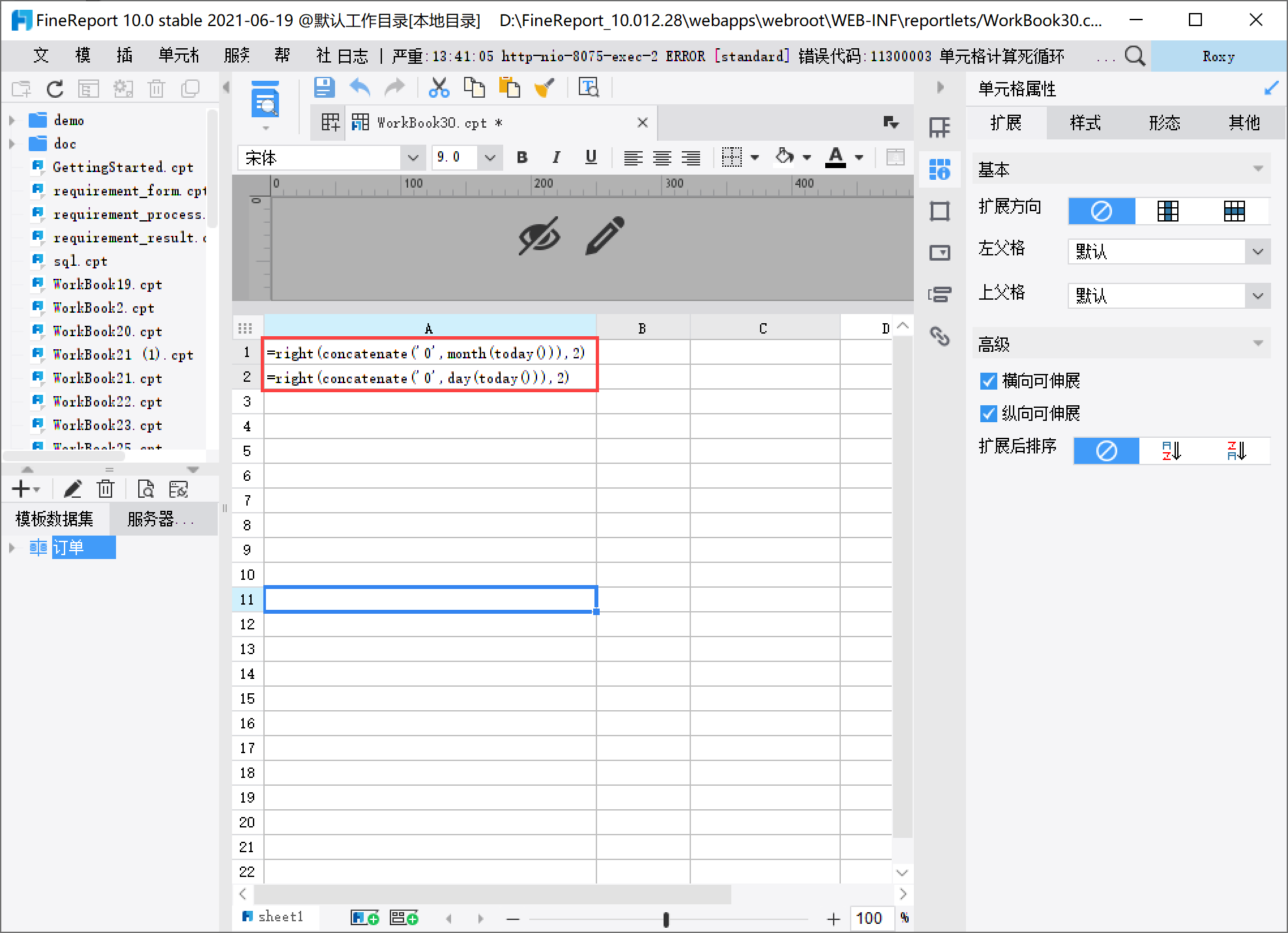
根据文本控件值中填入的公式,预览时的返回值和分隔符也会有所不同,详情如下表所示: 公式返回值分隔符图示 treelayer($tree, true, "\',\'")人力资源文员 业务员 ','人力资源部 市场部 ,人力资源部 市场部 ','点击下载模板:treelayer函数.cpt 日期函数应用 1. 概述在使用 FineReport 进行可视化展示时,经常会需要对日期数据进行处理,本文介绍几种日期类型数据的处理应用场景。 2. 获取月份或日期的时候显示 2 位 2.1 问题描述在使用公式month()或者是day()时,如果月份或日期是一位数,则显示出来的也只有一位数,比如说 1 月 9 号,获取月份时显示的是 1,而不是 01,获取日期时,显示的是 9,而不是 09,如果需要获取到 01 或者是 09,这个该如何通过公式实现呢? 2.2 解决方案通过公式或者自定义函数实现。 2.3 操作步骤 2.3.1 公式实现1)使用 RIGHT、CONCATENATE、MONTH 组合函数实现。 例如显示当前时间(2021-08-31)对应的月份和天数且以两位数字显示。 在单元格分别输入: 月份公式:=right(concatenate('0',month(today())),2) 天数公式:=right(concatenate('0',day(today())),2)
公式说明: 公式说明concatenate('0',month(today())) concatenate('0',day(today())) 通过 concatenate 将获取到的月份或者天数前面拼接一个 0,比如说 11 月,则显示 011,如果是 2 月,则显示 02;如果是 31 号,则显示 031right(concatenate('0',month(today())),2) right(concatenate('0',day(today())),2) 通过 right 方法,获取右边的 2 位数字,比如说 2 月,截取 2 位数字,则为 02,比如 12 月,截取右边的两位,则为 12;比如 31号,则截取右边的两位 31效果查看:
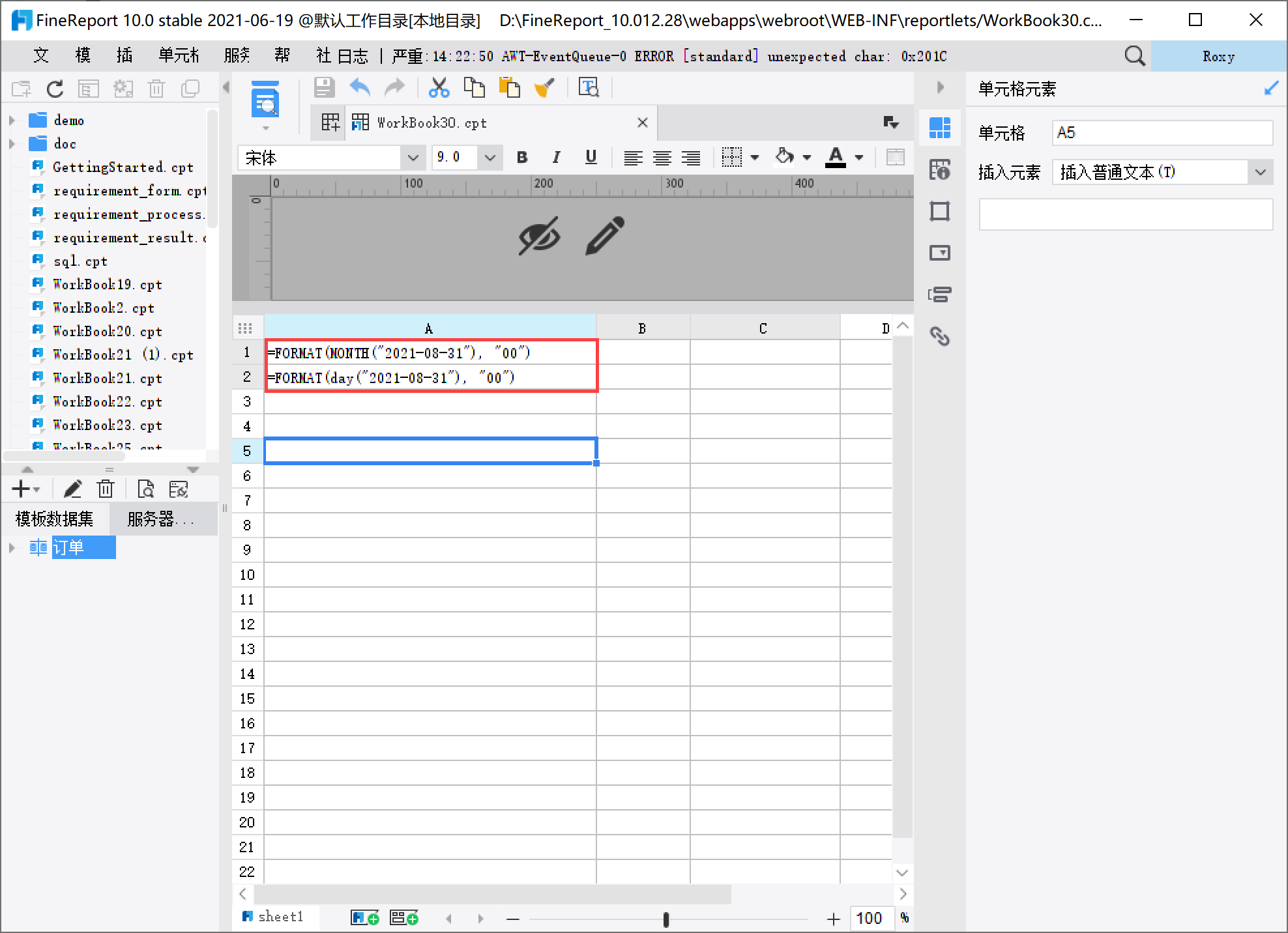
2)通过 FORMAT 来格式化字符串。 在单元格分别输入: 月份公式:=FORMAT(MONTH("2021-08-31"), "00") 天数公式:=FORMAT(day("2021-08-31"), "00")
公式说明: 公式说明MONTH("2021-08-31") day("2021-08-31") 返回月份数字:8 返回天数数字:31 FORMAT(MONTH("2021-08-31"), "00") FORMAT(day("2021-08-31"), "00") 返回 format 格式,也就是效果查看:
如果觉得公式比较复杂,则可以通过自定义函数实现,代码如下: package com.fr.function;import com.fr.script.AbstractFunction;public class Add0 extends AbstractFunction { public Object run(Object[] args) { String result = args[0].toString(); if(result.length() == 1) result = '0' + result; return result; }}自定义函数的详细定义步骤请参照 自定义函数。 3. 利用日期函数生成特定编号有些情况下需要生成特定字符且带「年月日时分秒」这样的字符串,类似 china20170726144516 这样的编号,可以直接利用时间公式和字符串拼接函数来实现。 在单元格中写入公式:="china" + FORMAT(now(), "yyyMMddhhmmss") 结果为:china20180101124516,即字符串“china”后面加当前的「年月日时分秒」。 注:一般编号非必要的情况下,不要全用数字,因为在导入导出到 EXCEL 时数字有可能出错。 两个表里数组字段的映射关联 1. 描述 有时,在新建数据集过程中,可能会遇到这样的需求:将2个表进行数组字段的映射关联,形成一个最终表。一般情况下,可以直接通过表与表之间通过JOIN关联实现,但如果某个字段以数组存在时,JOIN方法就不好处理了。 如图:表1、表2
 2. 思路
1)在MYSQL数据库中通过group_concat()函数与find_in_set()函数结合实现。
2)在Sql Server数据库中通过stuff()函数与charindex()函数结合实现。
3. 示例(一)
Mysql版本:5.5.28
在Mysql中实现,SQLl脚本如下:
select a.*, group_concat(lesson) as LESSONNAME from t2 a, t1 b where find_in_set(b.id, lessonid) group by name
2. 思路
1)在MYSQL数据库中通过group_concat()函数与find_in_set()函数结合实现。
2)在Sql Server数据库中通过stuff()函数与charindex()函数结合实现。
3. 示例(一)
Mysql版本:5.5.28
在Mysql中实现,SQLl脚本如下:
select a.*, group_concat(lesson) as LESSONNAME from t2 a, t1 b where find_in_set(b.id, lessonid) group by name
4. 示例 4.1 准备数据 DROP TABLE [dbo].[test_a] GO CREATE TABLE [dbo].[test_a] ( [id] int NULL , [name] varchar(255) NULL ) GO -- ---------------------------- -- Records of test_a -- ---------------------------- INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'1', N'苹果') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'2', N'橘子') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'3', N'菠萝') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'4', N'香蕉') GO GO INSERT INTO [dbo].[test_a] ([id], [name]) VALUES (N'5', N'西瓜') GO GO ----------------------------------------------------------- DROP TABLE [dbo].[test_b] GO CREATE TABLE [dbo].[test_b] ( [id] int NULL , [name] varchar(255) NULL ) GO -- ---------------------------- -- Records of test_b -- ---------------------------- INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'1', N'梨子') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'2', N'苹果') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'3', N'草莓') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'4', N'桃子') GO GO INSERT INTO [dbo].[test_b] ([id], [name]) VALUES (N'5', N'香蕉') GO GO 注:需要手动建test_a,test_b两个表。 4.2 示例介绍 1)Inner join 产生A和B的交集。 SELECT * FROM test_a INNER JOIN test_b ON test_a.name = test_b.name
3.3 动态SQL declare @ck varchar(8000) set @ck='' --初始化变量@ck select @ck=@ck+','+ cp from test_table group by cp -- 变量多值赋值,将结果 ,香蕉,苹果,梨,菠萝 赋值给变量@ck set @ck=stuff(@ck,1,1,'') --去掉首个',' 将 香蕉,苹果,梨,菠萝 赋值给变量@ck --第一个字符串 apple 中删除从第 2 个位置(字符 b)开始的3个字符,然后在删除的起始位置插入第二个字符串,从而创建并返回一个新的字符串。 --例:SELECT STUFF('apple', 2, 3, 'test'); 返回ateste set @ck='select * from test_table pivot (max(price) for cp in ('+@ck+'))a' --拼接sql并赋值给变量@ck exec(@ck) --执行sql语句
Null的处理 1. 描述 我们在建立数据集时,有时候可以会在原表基础上对字段进行加减乘除的运算,此时如果遇到字段中有Null或0值的情况,我们该怎么处理呢? 2. 思路 可以对Null或0值通过数据库表达式进行转换再运算。 3. 示例 3.1 示例(字段为空) 当在做二个字段相乘,一个有数据值,一个为空值时,这时您会发现语句并不会报错,但是这种结果并不是您想要的,您的需求是当数据列值为空时,用1来表示。OK,现在我们就以实例(分不同的数据库)来解答! 准备数据 -- ---------------------------- -- Table structure for test_c -- ---------------------------- DROP TABLE [dbo].[test_c] GO CREATE TABLE [dbo].[test_c] ( [cp] varchar(255) NULL , [price] int NULL , [numb] int NULL ) GO -- ---------------------------- -- Records of test_c -- ---------------------------- INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'苹果', N'80', N'20') GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'橘子', N'35', null) GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'菠萝', N'45', N'0') GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'香蕉', N'24', null) GO GO INSERT INTO [dbo].[test_c] ([cp], [price], [numb]) VALUES (N'西瓜', N'60', N'15') GO GO cp price numb 苹果 80 20 橘子 35 菠萝 45 0 香蕉 24 西瓜 60 15 1)SQL Server 数据库--使用Isnull()函数 SELECT cp, price, numb, price * isnull(numb, 1) AS priceb --isnull(numb, 1) 当numb的值为空值时,就返回1 FROM test_c;
3)MySQL 数据库-使用Coalesce()函数 SELECT cp, price, numb, price * coalesce(numb, 1) AS priceb -- coalesce(numb, 1) 当numb的值为空值时,就返回1 FROM test_c;
3.2 示例(字段为0) 当我们在做数据集sql运算的时候,可能会遇见字段相除的情况,这个时候可要注意,分母不能为0,例: SELECT cp, price, numb, price /numb AS priceb FROM test_c; 会报如下错误 [SQL]SELECT cp, price, numb, price /numb AS priceb FROM test_c [Err] 22012 - [SQL Server]遇到以零作除数错误。 如果遇到分母为0的情况,我们可这样处理。 以sql server为例 SELECT cp, price, numb, price / CASE WHEN numb = 0 THEN Null ELSE numb END AS priceb --CASE WHEN numb = 0 THEN Null ELSE numb END 解释:当numb = 0时,返回null FROM test_c;
4.2 执行(组内)排名sql SELECT t_time, code, name, CL, row_number () OVER (partition BY t_time ORDER BY cl) AS 组内排名1, --T_time组内,cl排名 row_number () OVER (ORDER BY cl) AS 排名1_1, --所有cl的排名 rank () OVER (partition BY t_time ORDER BY cl) AS 组内排名2, --T_time组内,cl排名 rank () OVER (ORDER BY cl) AS 排名2_1, --所有cl的排名 dense_rank () OVER (partition BY t_time ORDER BY cl) AS 组内排名3, --T_time组内,cl排名 dense_rank () OVER (ORDER BY cl) AS 排名3_1 --所有cl的排名 FROM zsh_0220 ORDER BY t_time,code; 关键点分析: OVER (partition BY t_time ORDER BY cl) 解释:按t_time分组(示例将t_time分为2005,2006二个组), cl排序(默认:升序)。降序可设置ORDER BY cl desc 函数ROW_NUMBER() OVER () ,RANK() OVER ()RANK(),DENSE_RANK() OVER ()的区别在这就不详细介绍了,可参考:开窗函数-排名 4.3 预览结果: 执行上述sql语句,可得到如下效果:
4.2 使用分析函数进行分析 执行sql: SELECT part, name_c, pay, CUME_DIST () OVER (ORDER BY pay) AS cat_1, CUME_DIST () OVER (PARTITION BY part ORDER BY pay) AS cat_2 FROM ZSH_170222 ORDER BY part, pay 结果预览与分析:
Cat_1: 没有PARTITION BY ,在整个公司里分析 所有数据均为1组,总行数为17 第一行(黄伟):小于等于1646的行数为2,因此,2/17= 0.117647058823529 第二行(张军):小于等于3538的行数为5,因此,5/17= 0.294117647058824 第三行(赵丽):小于等于3538的行数为7,因此,7/17= 0.411764705882353 … 第十七行(赵丽君):小于等于7975的行数为15,因此,15/17= 0.882352941176471 Cat_2: 按照部门(技术部/综合部)分析 技术组的行数为7, 第一行(黄伟):小于等于1646的行数为1,因此,1/7= 0.142857142857143 第二行(张军):小于等于3538的行数为2,因此,2/7= 0.285714285714286 … 第七行(小明):小于等于9741的行数为7,因此,7/7= 1 综合部的行数为10, 第一行(黄渤):小于等于1247的行数为1,因此,1/10= 0.1 第二行(刘伟):小于等于2142的行数为2,因此,2/10= 0.2 … 第十行(赵丽君):小于等于7975的行数为10,因此,10/10= 1 表达式-CASE 1. CASE介绍 计算条件列表,并返回多个可能的结果表达式之一。 CASE 表达式有两种格式: ☆ CASE 简单表达式:它通过将表达式与一组简单的表达式进行比较来确定结果。 ☆ CASE 搜索表达式:它通过计算一组布尔表达式来确定结果。 这两种格式都支持可选的 ELSE 参数。 CASE 可用于允许使用有效表达式的任意语句或子句。 例如,可以在 SELECT、UPDATE、DELETE 和 SET 等语句以及 select_list、IN、WHERE、ORDER BY 和 HAVING 等子句中使用 CASE。 2. 示例分析 2.1 准备数据 -- ---------------------------- -- Table structure for zsh_170225 -- ---------------------------- DROP TABLE [dbo].[zsh_170225] GO CREATE TABLE [dbo].[zsh_170225] ( [name] varchar(255) NULL , [sex] varchar(255) NULL ) GO -- ---------------------------- -- Records of zsh_170225 -- ---------------------------- INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'张三', N'1') GO GO INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'李四', N'2') GO GO INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'王五', null) GO GO INSERT INTO [dbo].[zsh_170225] ([name], [sex]) VALUES (N'赵六', N'1') GO GO Name Sex 张三 1 李四 2 王五 赵六 1 2.2 演示sql_1 简单 CASE 表达式︰CASE 简单表达式的工作方式如下:将第一个表达式与每个 WHEN 子句中的表达式进行比较,以确定它们是否等效。 如果这些表达式等效,将返回 THEN 子句中的表达式。 Select name,sex, CASE sex WHEN '1' THEN '男' --如果sex字段值为1就sex=’男’ WHEN '2' THEN '女' --如果sex字段值为2就sex=’女’ ELSE '其他' END --否则sex=’其他’ AS sex_n FROM zsh_170225
|













































































【本文地址】