| 双重差分法(DID)的原理及Python实现 | 您所在的位置:网站首页 › 差分法的原理是什么 › 双重差分法(DID)的原理及Python实现 |
双重差分法(DID)的原理及Python实现
|
问题情境 假设我想了解国家实施了一个政策(比如某个防疫政策)对经济的影响,我该如何检验这种影响? 一个自然的想法是:比较实施了这种政策的地区(实验组)和没有实施地区(对照组)的差异。但很多时候,对照组和实验组本身就有差异,所以对比出的结果并不可靠。我们还要比较政策实施点前后实验组和对照组的差异。 这种想法在统计上的实现可以是双重差分法(Difference-in-Difference ,DiD). 双重差分法双重差分法是一种在经济学、社会科学和公共卫生等领域中广泛使用的统计方法,用于估计一种政策、干预或事件对一个或多个群体的影响。这种方法的基本思想是比较同一时间内不同群体之间的差异,并比较这些群体在政策、干预或事件之前和之后的变化。 具体来说,DiD方法的核心是使用两个时间点的差异进行分析。其中一个时间点是政策、干预或事件之前的时间,另一个时间点是政策、干预或事件之后的时间。同时,研究者需要选择一个实验组和一个对照组。实验组是受政策、干预或事件影响的群体,而对照组则是没有受到影响的群体。 在DiD方法中,研究者首先比较两个时间点的实验组和对照组之间的差异。然后,研究者比较政策、干预或事件之前和之后实验组和对照组的差异。通过这种比较,研究者可以得出政策、干预或事件对实验组与对照组之间差异的影响大小。 DiD方法的优点在于它可以解决许多潜在的混淆因素,并且可以在不进行随机分组试验的情况下估计政策、干预或事件的效应。然而,DiD方法也有一些限制,包括对实验组和对照组的选择敏感以及对时间趋势的假设。 具体例子假设我们想了解某个城市实施“限行令”对汽车交通拥堵的影响。限行令是指在特定时间段内限制特定车牌号码的汽车上路,以减少道路交通拥堵。 我们可以将政策实施前后的交通流量和车速作为主要的衡量指标。在这种情况下,我们需要选择一个实验组和一个对照组。实验组可以是政策实施范围内的区域,而对照组可以是政策实施范围之外的区域。 我们需要选择两个时间段,一个是政策实施前,另一个是政策实施后。例如,政策实施前是 2020 年,政策实施后是 2021 年。 接下来,我们比较政策实施前后,实验组和对照组中的交通流量和车速。如果限行令可以显著降低实验组中的交通流量,同时提高实验组中的车速,而对照组中的交通流量和车速没有变化或变化不显著,那么我们可以得出结论:限行令对减少交通拥堵产生了积极的影响。 数学模型双重差分法的数学模型可以表示为以下方程: Y_it = β0 + β1 * D_it + β2 * P_t + β3 * D_it * P_t + ε_it \\ 其中,Y_{it} 表示观测对象 i 在时间 t 的观测结果;D_{it} 是二进制自变量(0-1变量),表示观测单位 i 在时间 t 是否接受了政策、干预或事件;P_t 是二进制自变量,表示观测时间是否在政策、干预或事件发生后;β0 是常数项;β1 表示政策、干预或事件的效应,即 DiD 估计量;β2 表示时间的效应,即 P_t 的系数;β3 表示 DiD 估计量与时间的交互作用,即 D_it * P_t 的系数;ε_it 表示误差项。 DiD 方法的基本思想是,通过比较实验组和对照组在政策实施前后的差异,来估计政策对实验组的影响。DiD 估计量 β1 的计算公式为: β1 = (Y_{1t} - Y_{0t}) - (Y_{1t-1} - Y_{0t-1}) \\ 其中,Y_{1t} 和 Y_{0t} 分别表示实验组和对照组在政策实施后的观测结果,而 Y_{1t-1} 和 Y_{0t-1} 分别表示实验组和对照组在政策实施前的观测结果。通过计算 DiD 估计量 β1,我们可以评估政策对实验组的影响。 Python实现现在有这样一份数据,A市放置了 3 个广告牌。我们想看看这是否会增加A市居民的存款。作为对照,我们也选取了B市居民的数据。放置广告牌的时间是7月. import warnings warnings.filterwarnings('ignore') import pandas as pd import numpy as np from matplotlib import style from matplotlib import pyplot as plt import seaborn as sns import statsmodels.formula.api as smf %matplotlib inline style.use("fivethirtyeight") data = pd.read_excel('data/billboard.xlsx')这是前5条数据: depositAjuly0421010102521031191042110接下来我们比较放置广告牌前后,A市居民存款量的变化 a_before = data.query("A==1 & july==0")["deposit"].mean() a_after = data.query("A==1 & july==1")["deposit"].mean() a_after -a_before值为41.04775。但这个值是不是由于广告牌的影响的,说不定就是因为收入随时间一直在增加导致的,和广告牌没啥关系。我们需要找到对照组。 b_after = data.query("A==0 & july==1")["deposit"].mean() a_after - b_after值为 -119.10175000000001。这个值表示的是7月以后A市与B市的平均存款之差,A市低于B市。当然,这可能是因为B市本来存款就多,比A市要富裕。我们还需要综合时间因素和对照组因素。 b_before = data.query("A==0 & july==0")["deposit"].mean() diff_in_diff = (a_after-a_before)-(b_after-b_before) diff_in_diff结果为:6.524557692307688。 确实是涨了。 画个图像来看看: plt.figure(figsize=(10,5)) plt.plot(["Before", "After"], [a_before, a_after], label="A", lw=2) plt.plot(["Before", "After"], [b_before, b_after], label="B", lw=2) plt.plot(["Before", "After"], [a_before, a_before+(b_after-b_before)], label="Counterfactual", lw=2, color="C2", ls="-.") plt.legend()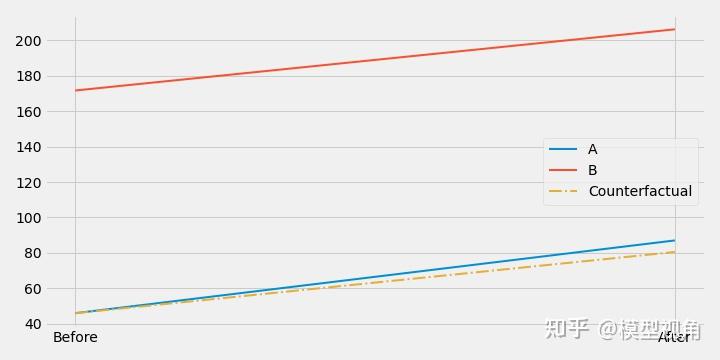 点画线(黄线)是通过B市的变化推出的假设A市没有放置广告牌的变化曲线,是“反事实”(counter factual)的结果。 我们再来将数据放到模型中,来看一下系数和标准误: Y_i = \beta_0 + \beta_1 A_i + \beta_2 Jul_i + \beta_3 A_i*Jul_i + e_i smf.ols('deposit ~ A*july', data=data).fit().summary().tables[1]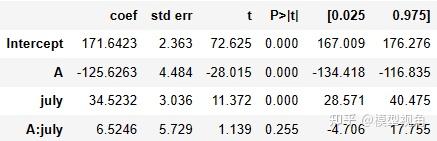 从结果上来看,A,july 的系数都是显著的,交叉项不显著。请注意,\beta_0 是控制组的基线。在我们的例子中,是 7月份之前B市的存款水平。如果我们将干预过的城市对应的虚拟变量设为1,我们会得到 \beta_1。所以 \beta_0 + \beta_1是A市7月份之前前的基线,而 \beta_1 是A市基线在B之上的增量。如果我们关闭 A虚拟变量并打开 7 月之后虚拟变量,我们会得到 \beta_0 + \beta_2,即干预期后 B市 在 7 月之后的水平。 \beta_2 是控制组的趋势,是我们将它添加到基线之上以获得干预后时期的控制水平。\beta_1 是我们从处理到控制得到的增量,\beta_2 是我们从之前的时期到之后的时期得到的增量干涉。最后,如果我们打开两个虚拟变量,我们会得到 \beta_3。 \beta_0 + \beta_1 + \beta_2 + \beta_3 是干预后A的水平。所以 \beta_3 是从 7月之前到 7 月之后以及从B到 A 的增量影响。换句话说,它是差异估计量的差. 参考资料 Matheus Facure; Michell Germano Python-causality-handbook: First Edition |
【本文地址】