| 【数据挖掘】岭回归Ridge讲解及实战应用(超详细 附源码) | 您所在的位置:网站首页 › 岭回归方程模型 › 【数据挖掘】岭回归Ridge讲解及实战应用(超详细 附源码) |
【数据挖掘】岭回归Ridge讲解及实战应用(超详细 附源码)
|
需要源码请点赞关注收藏后评论区留言私信~~~ 岭回归岭回归(Ridge Regression)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价,获得回归系数更为符合实际、更可靠的回归方法,对病态数据的耐受性远远强于最小二乘法 岭回归的目标函数在一般的线性回归的基础上加入了L2正则项,在保证最佳拟合误差的同时,使得参数尽可能的“简单”,使得模型的泛化能力强,同时可以解决线性回归中不可逆情况 岭回归算法是在原线性回归模型的损失函数中增加L2正则项
岭回归主要适用于过拟合严重或各变量之间存在多重共线性的情况,它可以解决特征数量比样本量多的问题,另外,岭回归作为一种缩减算法可以判断哪些特征重要或者不重要,有点类似于降维,缩减算法可以看作是对一个模型增加偏差的同时减少方差。但是岭回归方程的R平方值会稍低于普通回归分析,但回归系数的显著性往往明显高于普通回归,在存在共线性问题和病态数据偏多的研究中有较大的实用价值 欠拟合、过拟合与泛化能力明显地向两端寻找曲线点,看看这些形状和趋势是否有意义。更高次的多项式最后可能产生怪异的推断结果
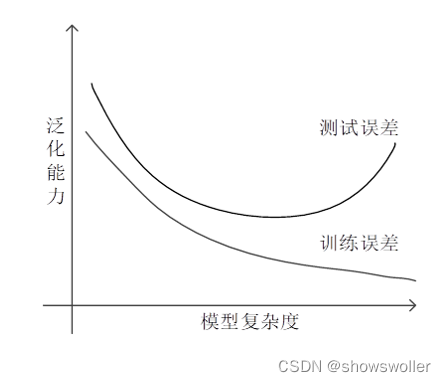
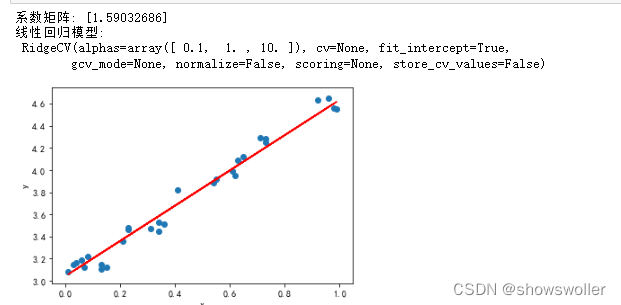
模型在训练样本上产生的误差叫训练误差(training error。在测试样本上产生的误差叫测试误差(test error) 衡量模型好坏的是测试误差,它标志了模型对未知新实例的预测能力,因此一般追求的是测试误差最小的那个模型。模型对新实例的预测能力称为泛化能力,模型在新实例上的误差称为泛化误差 能够求解问题的模型往往不只一个。一般来说,只有合适复杂程度的模型才能最好地反映出训练集中蕴含的规律,取得最好的泛化能力 实战效果如下 可见可以十分精确的拟合数据
部分代码如下 import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import Ridge,RidgeCV # Ridge岭回归,RidgeCV带有广义交叉验证的岭回归 data=[ [0.07,3.12],[0.41,3.82],[0.99,4.55],[0.73,4.25],[0.98,4.56], [0.55,3.92],[0.34,3.53],[0.03,3.15],[0.13,3.11],[0.13,3.15], [],[0.36,3.51],[0.15,3.12],[0.63,4.09],[0.23,3.46], [0.08,3.22],[0.06,3.19],[0.92,4.63],[0.71,4.29],[0.01,3.08], [0.34,3.45],[0.04,3.16],[0.21,3.36],[0.61,3.99],[0.54,3.89] ] #生成X和y矩阵 dataMat = np.array(data) X = dataMat[:,0:1] # 变量x y = dataMat[:,1] #变量y # 岭回归 model = Ridge(alpha=0.5) model = RidgeCV(alphas=[0.1, 1.0, 10.0]) # RidgeCV可以设置多个参数,算法使用交叉验证获取最佳参数值 model.fit(X, y) # 线性回归建模 print('系数矩阵:',model.coef_) print(预测 predicted = model.predict(X) # 绘制散点图 参数:x横轴 y纵轴 plt.scatter(X, y, marker='o') plt.plot(X, predicted,c='r') # 绘制x轴和y轴坐标 plt.xlabel('x') plt.ylabel('y') # 显示图形 plt.show()创作不易 觉得有帮助请点赞关注收藏~~~ |
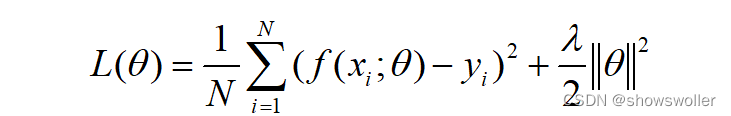



【本文地址】
公司简介
联系我们