| AHP(层次分析法)学习笔记及多层权重Python实践 | 您所在的位置:网站首页 › 层级分析 › AHP(层次分析法)学习笔记及多层权重Python实践 |
AHP(层次分析法)学习笔记及多层权重Python实践
|
层次分析法(The analytic hierarchy process)简称AHP,在20世纪70年代中期由美国运筹学家托马斯·塞蒂(TLsaaty)正式提出。它是将与决策有关的因素分解成目标、准则、方案等层次,在此基础之上进行定性和定量分析的决策方法。由于它在处理复杂的决策问题上的实用性和有效性,很快在世界范围得到重视。它的应用已遍及经济计划和管理、能源政策和分配、行为科学、军事指挥、运输、农业、教育、人才、医疗和环境等领域。 1. 层次分析法 1.1. AHP模型构建在深入分析问题的基础上,将决策的目标、考虑的因素和决策对象按相关关系分为最高层、中间层和最低层。 最高层:决策的目的、要解决的问题 中间层:主因素,考虑的因素、决策的准则 最低层:决策时的备选方案,也可为中间层的子因素
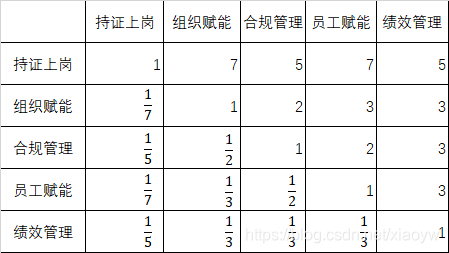
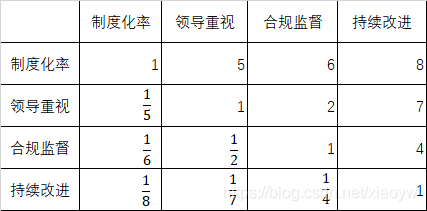
构造判断矩阵的方法是一致矩阵法,即:不把所有因素放在一起比较,而是两两相互比较;对此时采用相对尺度,以尽可能减少性质不同因素相互比较的困难,以提高准确度。 标度 A i j A_{ij} Aij含义1i 指标比 j 指标同样重要3i 指标比 j 指标略微重要5i 指标比 j 指标明显重要7i 指标比 j 指标重要的多9i 指标比 j 指标重要很多2,4,6,8介于上述两个判断的中值倒数i 指标与 j 指标比较得 A i j A_{ij} Aij, j 指标与 i指标比较判断得 A j i = 1 A i j A_{ji}=\frac{1}{A_{ij}} Aji=Aij1按照前面建立的层次递阶结构模型,每一层因素以相邻上一层因素为基准,按照表 1 标度取值方法两两比较构造判断矩阵。指标的标度值由专家取定,构造判断矩阵 A = [ a i j ] m × n A=\left [ a_{ij}\right ]_{m\times n} A=[aij]m×n。 因素两两比较,比较次数为: n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1) 判断思想:整体判断,n个因素两两比较;定性判断,定量标识(标量); 构造判断矩阵规则:填补右上三角为有规则; 判断矩阵元素有如下特征: a i j > 0 a_{ij}>0 aij>0、 a i j = 1 a i j a_{ij}=\frac{1}{a_{ij}} aij=aij1、 a i i = 1 a_{ii}=1 aii=1。 1.2.1. 构造准则层判断矩阵按专家投票打分等方式,构造准则层判断矩阵。 以“合规管理”为例,专家投票打分等人为方式构造因素层判断矩阵。 对应于判断矩阵最大特征根 λ m a x λ_{max} λmax的特征向量,经归一化(使向量中各元素之和为1)后记为 W W W。 W W W的元素为同一层次元素对于上一层因素某因素相对重要性的排序权值,这一过程称为层次单排序。 1.3.1. 规范化将判断矩阵按列规范化,即对判断矩阵 A 每一列归一化: a ˉ i j = a i j ∑ i = 1 n a i j \bar{a}_{ij} = \frac{a_{ij}}{\sum_{i=1}^{n}a_{ij}} aˉij=∑i=1naijaij 按行相加得和向量: W i = ∑ i = 1 n a ˉ i j W_{i} ={\sum_{i=1}^{n}\bar{a}_{ij}} Wi=∑i=1naˉij 1.3.2. 特征向量(权重)将得到的和向量正规化,可得权重向量: W ˉ i = W i ∑ i = 1 n W i \bar{W}_{i}=\frac{W_{i}}{\sum_{i=1}^{n}W_{i}} Wˉi=∑i=1nWiWi,近似为特征向量。 1.3.3. 最大特征根计算最大特征根 λ m a x λ_{max} λmax,采用“和积法”: λ m a x = 1 n ∑ i = 1 n ( A W ˉ ) i W ˉ i λ_{max}=\frac{1}{n} \sum_{i=1}^{n} \frac{(A \bar{W})_{i}}{\bar{W}_{i}} λmax=n1∑i=1nWˉi(AWˉ)i 这里 ( A W ˉ ) i (A \bar{W})_{i} (AWˉ)i是指矩阵乘法,原始矩阵 A A A与特征矩阵 W ˉ \bar{W} Wˉ相乘。 1.3.4. 一致性检验一致性检验是指对判断矩阵 A A A确定不一致的允许范围。 n n n阶一致阵的唯一非零特征根为 n n n, n n n阶正互反阵 A A A的最大特征根 λ m a x ⩾ n λ_{max}\geqslant n λmax⩾n 时, A A A为非一致矩阵,比 n n n 大的越多, A A A的不一致性越严重; 当且仅当 λ m a x = n λ_{max}=n λmax=n 时, A A A为一致矩阵。因此可由 λ m a x λ_{max} λmax 是否等于 n 来检验判断矩阵 A A A是否为一致矩阵。 从理论上分析得到:如果A是完全一致的成对比较矩阵,应该有 a i j a j k = a i k , 1 ≤ i , j , k ≤ n . a_{ij}a_{jk}=a_{ik},1\le i,j,k\le n. aijajk=aik,1≤i,j,k≤n. 但实际上在构造成对比较矩阵时要求满足上述众多等式是不可能的。因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。 由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。对成对比较矩阵的一致性要求,转化为要求: 的绝对值最大的特征值和该矩阵的维数相差不大。 检验成对比较矩阵A一致性的步骤如下: 定义一致性指标 C I = λ m a x − n n − 1 CI=\frac{λ_{max}−n}{n−1} CI=n−1λmax−n : C I = 0 CI=0 CI=0,有完全的一致性; C I CI CI接近于0,有满意的一致性; C I CI CI越大,不一致越严重。 为了衡量 C I CI CI的大小,引入随机一致性指标 R I RI RI,按照 Saaty 给出的关于平均随机一致性指标: n1234567891011RI000.580.901.121.241.321.411.451.491.51注解:从有关资料查出检验成对比较矩阵A 一致性的标准RI:RI称为平均随机一致性指标,它只与矩阵阶数n 有关(一般不超过9个)。 定义一致性比率: C R = C I R I CR=\frac{CI}{RI} CR=RICI,一般认为一致性比率$CR 1e-7: raise ValueError('不是反互对称矩阵') eigenvalues, eigenvectors = np.linalg.eig(input_matrix) max_idx = np.argmax(eigenvalues) max_eigen = eigenvalues[max_idx].real eigen = eigenvectors[:, max_idx].real eigen = eigen / eigen.sum() if n > 9: CR = None warnings.warn('无法判断一致性') else: CI = (max_eigen - n) / (n - 1) CR = CI / self.RI[n] return max_eigen, CR, eigen def run(self): max_eigen, CR, criteria_eigen = self.cal_weights(self.criteria) print('准则层:最大特征值{: |

【本文地址】