| 【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论! | 您所在的位置:网站首页 › 小红书爬取已发布图文 › 【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论! |
【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论!
|
目录一、爬取目标二、爬虫代码讲解2.1 分析过程2.2 爬虫代码三、演示视频四、获取完整源码
一、爬取目标
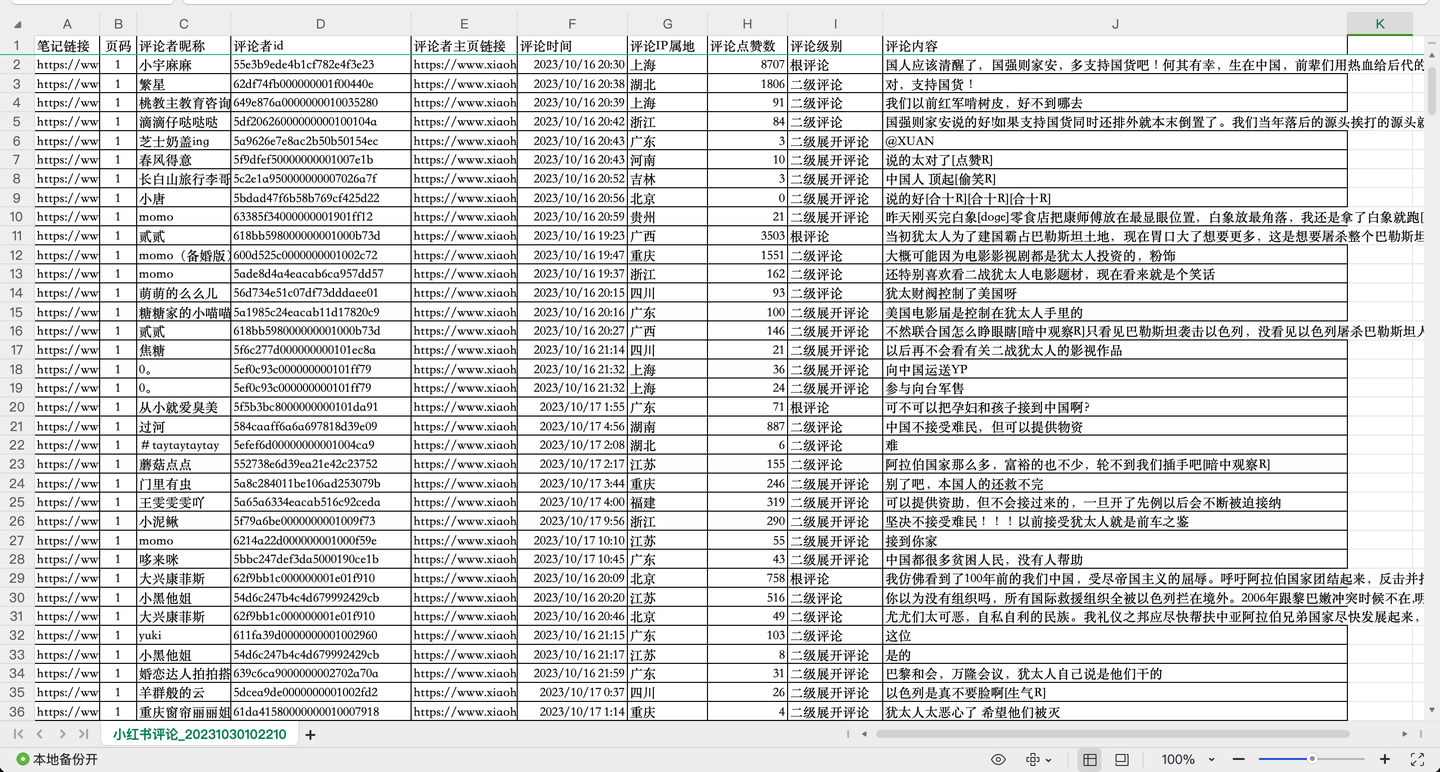
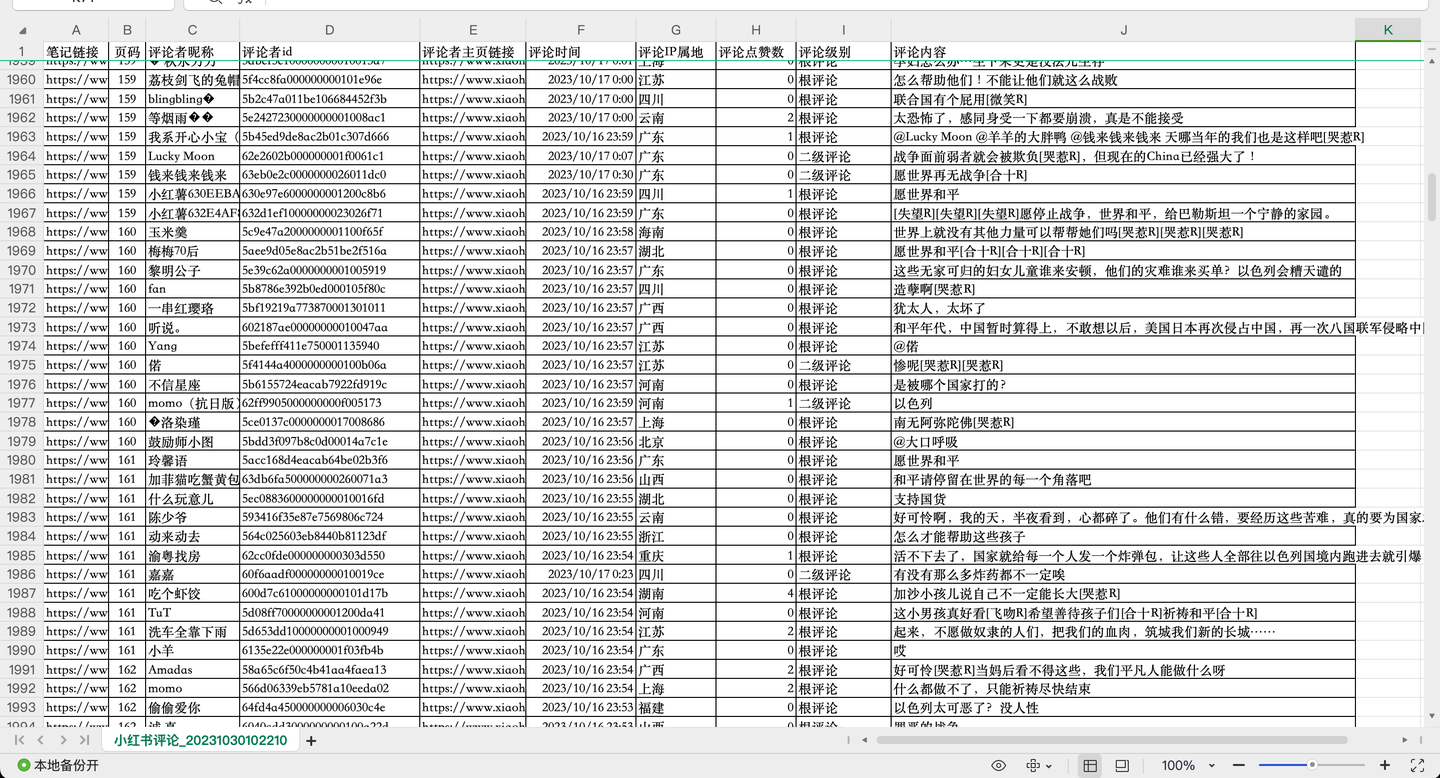
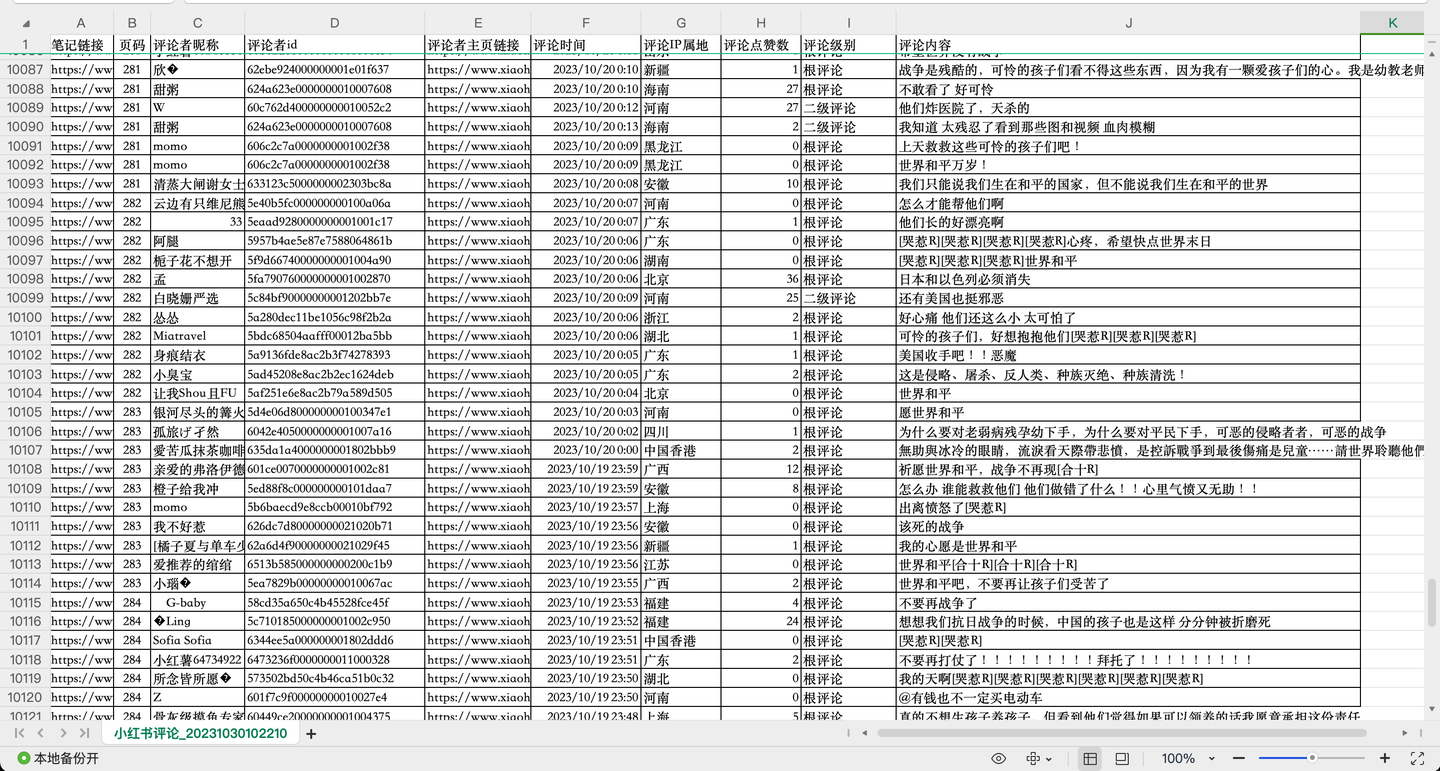
您好!我是@马哥python说 ,一名10年程序猿。 我们继续分享Python爬虫的案例,今天爬取小红书上指定笔记("巴勒斯坦"相关笔记)下的评论数据。 老规矩,先展示结果: 截图1:
截图2:
截图3:
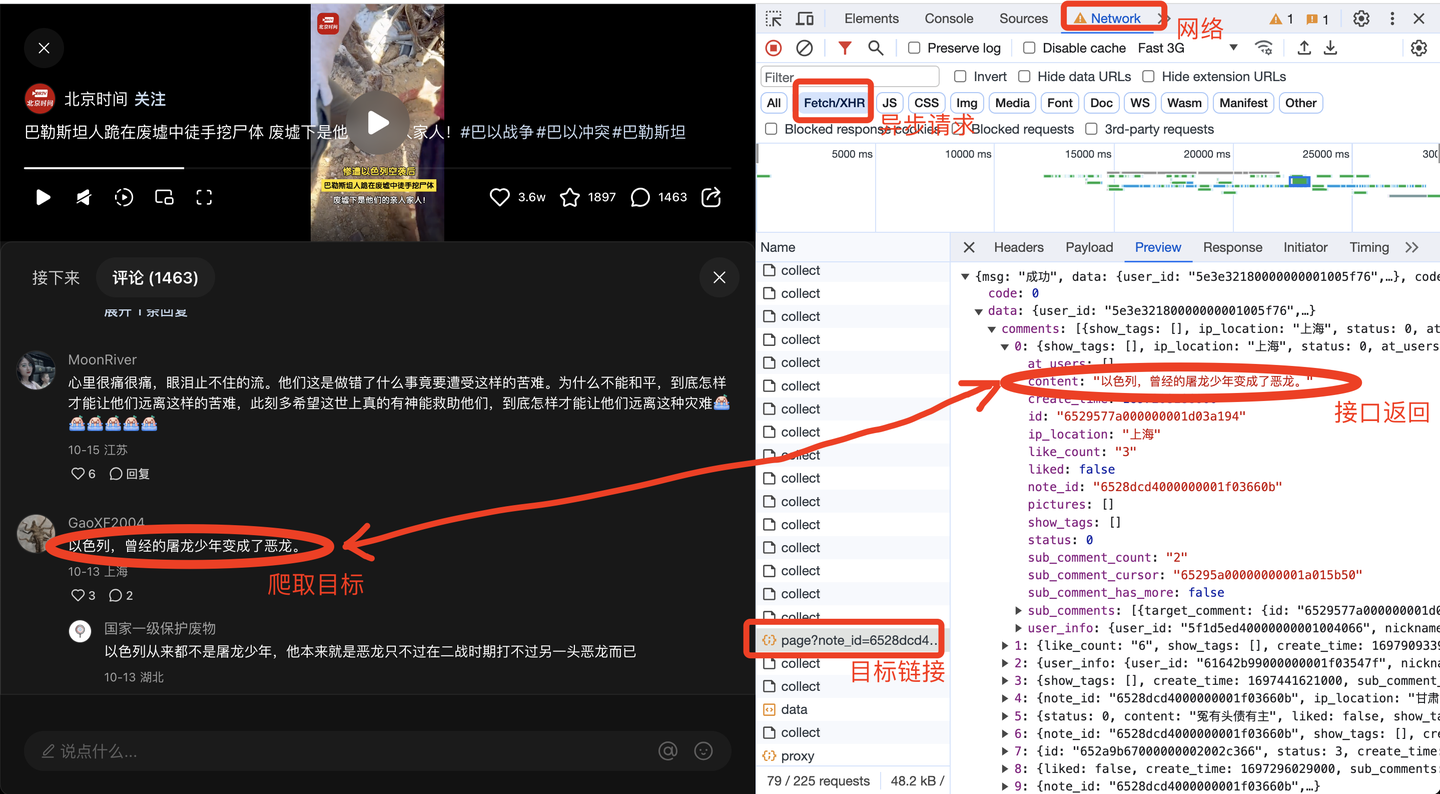
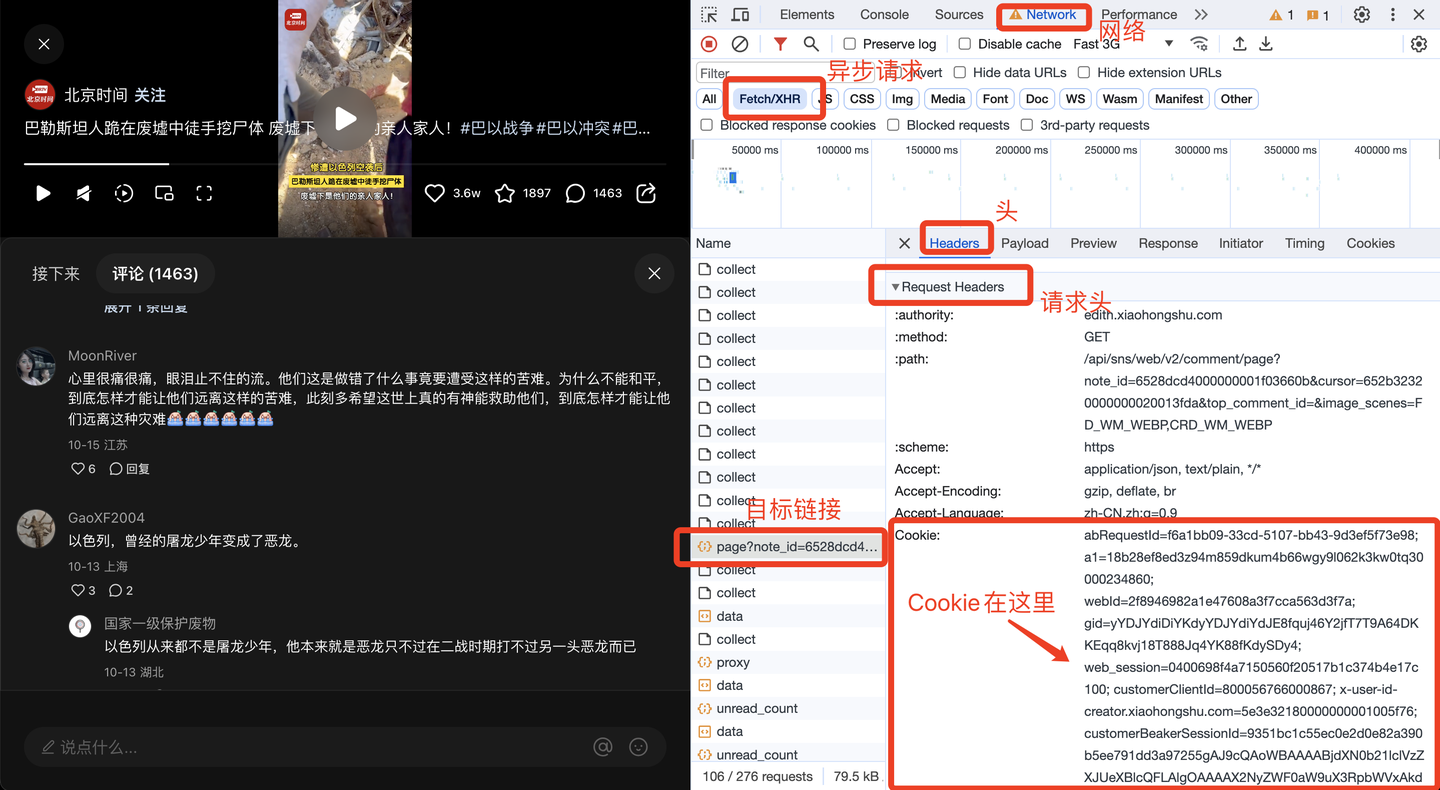
共爬取了1w多条"巴勒斯坦"相关评论,每条评论含10个关键字段,包括: 笔记链接, 页码, 评论者昵称, 评论者id, 评论者主页链接, 评论时间, 评论IP属地, 评论点赞数, 评论级别, 评论内容。 其中,评论级别包括:根评论、二级评论及二级展开评论。 二、爬虫代码讲解 2.1 分析过程任意打开一个小红书笔记的评论,打开浏览器的开发者模式,网络,XHR,找到目标链接的预览数据,如下:
由此便得到了前端请求链接,下面开始开发爬虫代码。 2.2 爬虫代码首先,导入需要用到的库: import requests from time import sleep import pandas as pd import os import time import datetime import random定义一个请求头: # 请求头 h1 = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36', # cookie需定期更换 'Cookie': '换成自己的cookie值', }经过我的实际测试,请求头包含User-Agent和Cookie这两项,即可实现爬取。
其中,Cookie很关键,需要定期更换。那么Cookie从哪里获得呢?方法如下:
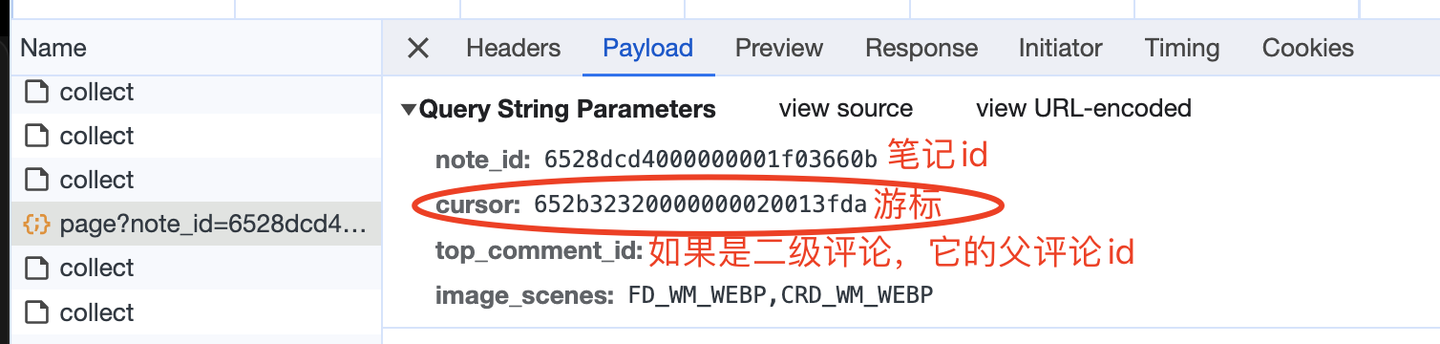
下面,开发翻页逻辑。 由于我并不知道一共有多少页,往下翻多少次,所以采用while循环,直到触发终止条件,循环才结束。 那么怎么定义终止条件呢?我注意到,在返回数据里有一个叫做"has_more"的参数,大胆猜测它的含义,是否有更多数据,正常情况它的值是true。如果它的值是false,代表没有更多数据了,即到达最后一页了,也就该终止循环了。 因此,核心代码结构应该是这样(以下是伪代码,主要是表达逻辑,请勿直接copy): while True: # 发送请求 r = requests.get(url, headers=h1) # 解析数据 json_data = r.json() # 逐条解析 for c in json_data['data']['comments']: # 评论内容 content = c['content'] content_list.append(content) # 保存数据到csv 。。。 # 判断终止条件 next_cursor = json_data['data']['cursor'] if not json_data['data']['has_more']: print('没有下一页了,终止循环!') break page += 1另外,还有一个关键问题,如何进行翻页。 查看请求参数,如下:
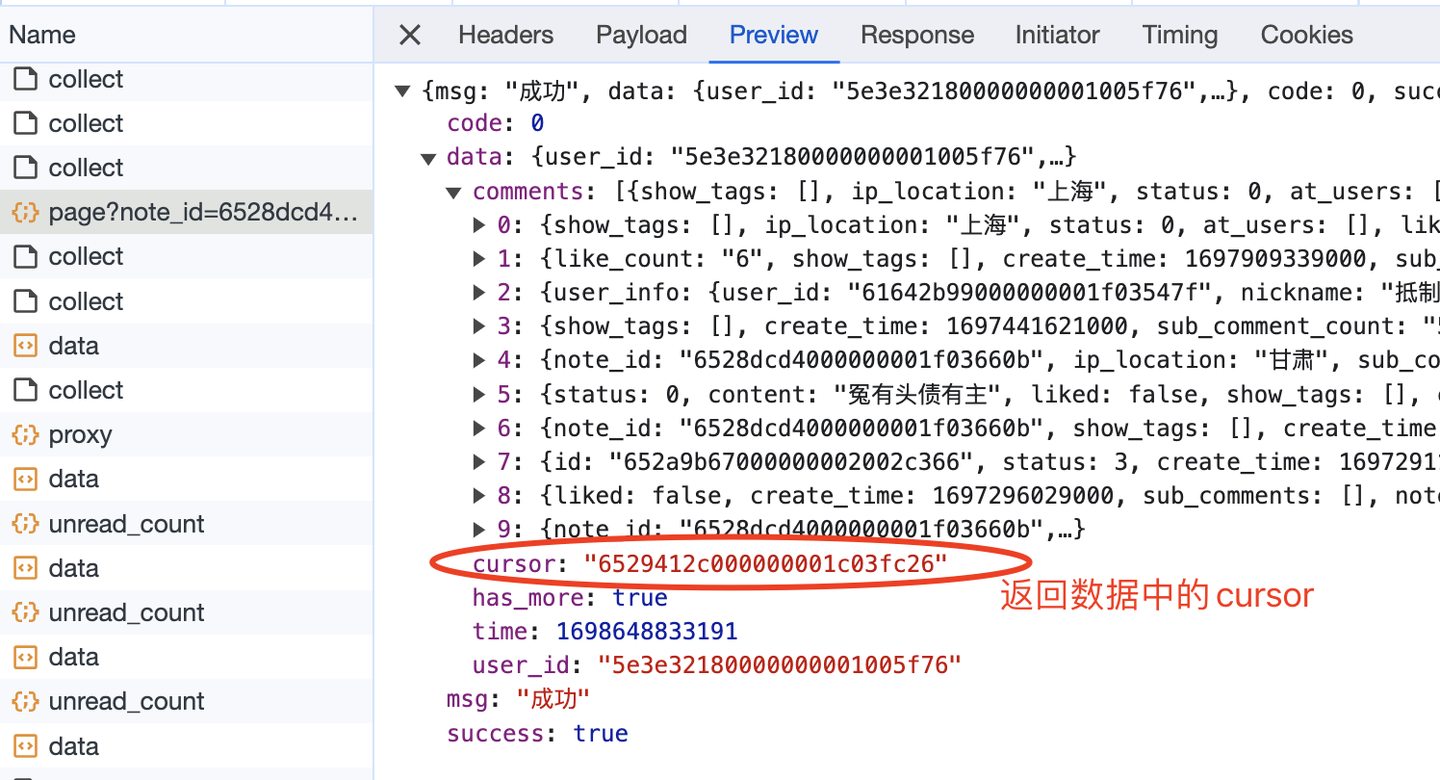
这里的游标,就是向下翻页的依据,因为每次请求的返回数据中,也有一个cursor:
大胆猜测,返回数据中的cursor,就是给下一页请求用的cursor,所以,这部分的逻辑实现应该如下(以下是伪代码,主要是表达逻辑,请勿直接copy): while True: if page == 1: url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP'.format( note_id) else: url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP&cursor={}'.format( note_id, next_cursor) # 发送请求 r = requests.get(url, headers=h1) # 解析数据 json_data = r.json() # 得到下一页的游标 next_cursor = json_data['data']['cursor']另外,我在第一章节提到,还爬到了二级评论及二级展开评论,怎么做到的呢? 经过分析,返回数据中有个节点sub_comment_count代表子评论数量,如果大于0代表该评论有子评论,进而可以从sub_comments节点中爬取二级评论。 其中,二级展开评论,请求参数中的root_comment_id代表父评论的id,其他逻辑同理,不再赘述。 最后,是顺理成章的保存csv数据: # 保存数据到DF df = pd.DataFrame( { '笔记链接': 'https://www.xiaohongshu.com/explore/' + note_id, '页码': page, '评论者昵称': nickname_list, '评论者id': user_id_list, '评论者主页链接': user_link_list, '评论时间': create_time_list, '评论IP属地': ip_list, '评论点赞数': like_count_list, '评论级别': comment_level_list, '评论内容': content_list, } ) # 设置csv文件表头 if os.path.exists(result_file): header = False else: header = True # 保存到csv df.to_csv(result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')至此,爬虫代码开发完毕。 完整代码中,还包含转换时间戳、随机等待时长、解析其他字段、保存Dataframe数据、多个笔记同时循环爬取等关键逻辑,详见演示视频。 三、演示视频代码演示:【Python爬虫】用python爬了10000条小红书评论,以#巴勒斯坦#为例 四、获取完整源码get完整源码:【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论! 我是@马哥python说,一名10年程序猿,持续分享python干货中! |
【本文地址】