| Adult数据集分析及四种模型实现 | 您所在的位置:网站首页 › 小于50k的图片 › Adult数据集分析及四种模型实现 |
Adult数据集分析及四种模型实现
|
文章目录
一、数据集数据集介绍数据集预处理及分析
二、四种模型对上述数据集进行预测深度学习决策树支持向量机随机森林
三、结果分析
一、数据集
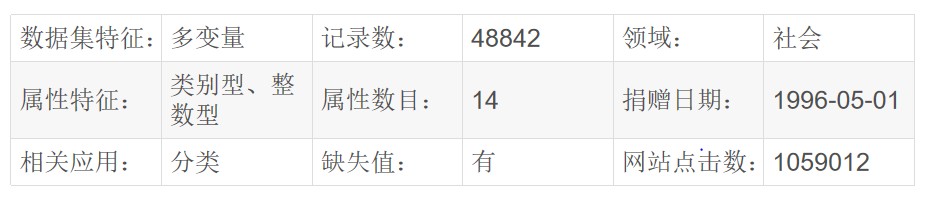
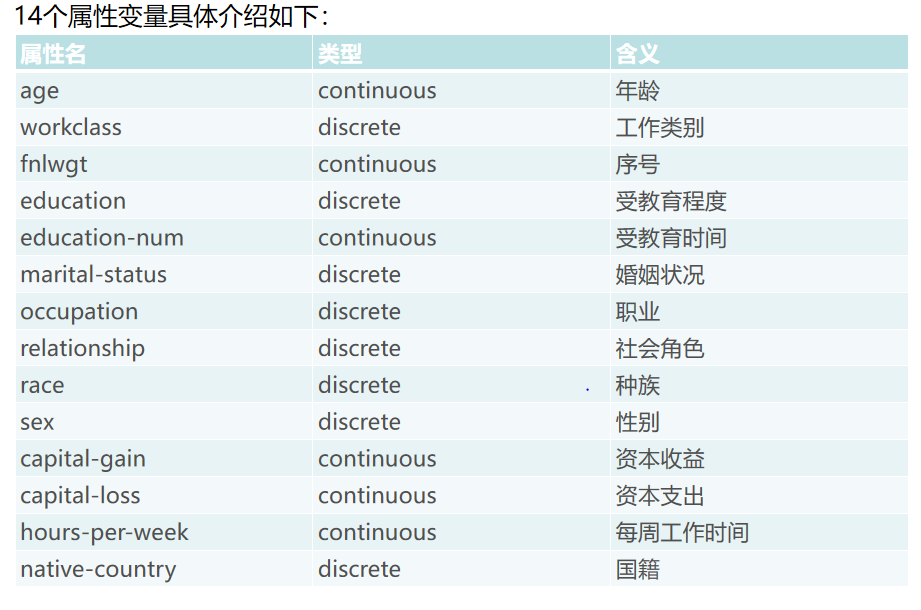
数据集下载:https://drive.google.com/drive/folders/17okhIt6mHpjof9eo03DoZNE1Zw4_wh7J?usp=sharing,只需要将代码读取的后缀改成 “.csv” 即可。 数据集介绍Adult数据集是一个经典的数据挖掘项目的的数据集,该数据从美国1994年人口普查数据库中抽取而来,因此也称作“人口普查收入”数据集,共包含48842条记录,年收入大于 50k$ 的占比23.93%年收入小于 50k$ 的占比76.07%,数据集已经划分为训练数据32561条和测试数据16281条。该数据集类变量为年收入是否超过 50k$ ,属性变量包括年龄、工种、学历、职业等14类重要信息,其中有8类属于类别离散型变量,另外6类属于数值连续型变量。该数据集是一个分类数据集,用来预测年收入是否超过50k$。下载地址点这里 因为是csv数据,所以主要采用pandas和numpy库来进行预处理,首先数据读取以及查看是否有缺失值 import pandas as pd import numpy as np df = pd.read_csv('adult.csv', header = None, names = ['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income']) df.head() df.info()
|
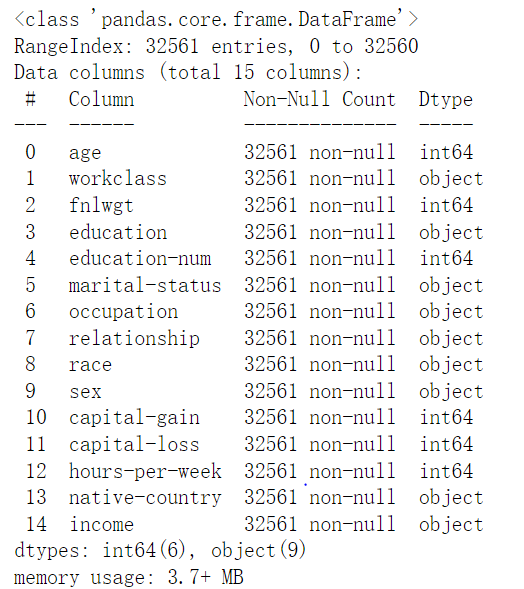 虽然上面查看数据是没有缺失值的,但其实是因为缺失值的是" ?",而info()检测的是NaT或者Nan的缺失值。注意问号前面还有空格。
虽然上面查看数据是没有缺失值的,但其实是因为缺失值的是" ?",而info()检测的是NaT或者Nan的缺失值。注意问号前面还有空格。 分别是居民的工作类型workclass(离散型)缺1836、职业occupation(离散型)缺1843和国籍native-country(离散型)缺583。离散值一般填充众数,但是在此之前要先将缺失值转化成nan或者NaT。同时因为收入可以分为两种类型,则将>50K的替换成1," >50K" : income_1, "
分别是居民的工作类型workclass(离散型)缺1836、职业occupation(离散型)缺1843和国籍native-country(离散型)缺583。离散值一般填充众数,但是在此之前要先将缺失值转化成nan或者NaT。同时因为收入可以分为两种类型,则将>50K的替换成1," >50K" : income_1, " 【本文地址】
公司简介
联系我们